The repository contains Master thesis Artificial Intelligence 2022 at the University of Amsterdam as a thesis intern at Robeco. Note that this is a light version where all the data files are removed, hence not executable. This version can be used to check jupyter notebook results without the need to open it locally. The full version of 20+ GB can be viewed and retrieved from here: https://drive.google.com/drive/folders/15Cju0hlG1vCmh9ZUeVQpK-flenVyJND2?usp=sharing
Additionally, Robeco has not yet decided on whether I could include their data into this repository, thus the commands associated with Robeco's data is not executable at the moment. I will notify you once there is an update from them.

The United Nations launched the 17 Sustainable Development Goals (SDGs) in 2015 as part of the 2030 Sustainable Development Agenda (as shown in the Figure above. The Figure is taken from the UN official website: https://www.un.org/en/sustainable-development-goals ).The aim of this project is to assess the present SDG framework produced by prominent financial institutions, as well as to aggregate diverse resources and automate the framework with the aid of artificial intelligence (AI), which could potentially help alignment with the SDGs and allow for informed investment decisions.
This project involves three steps:
-
Step I: Dataset Construction. We proposed a pipeline for constructing sustinability datasets for thousands of companies, and extracting SDG-related information for each company from different parts of the data we collected.
-
Step II: Investigating existing SDG frameworks through classification (with and without graphs). We conducted empirical research to study what features could contribute to forecasting existing SDG frameworks and whether/when graph algorithms would help, which gives us some insightful results.
-
Step III: Improving the existing SDG frameworks by incorporating more dimensions of data to generate and explain SDG scores. We proposed an algorithm/schema to generate and forecast SDG scores by incoporating more dimensions of data (including graphs!).
In this dissertation, we mix numerous AI algorithms from several subfields (Boosting, Graph Machine Learning, Information Retrieval/Natural Language Processing, XAI) in a unique manner to address the problem of sustainable investment in the financial arena. The challenges are solved by combining many AI approaches in an original way, which has not traditionally been done in earlier studies. The outline of our approach is shown in the schema below.
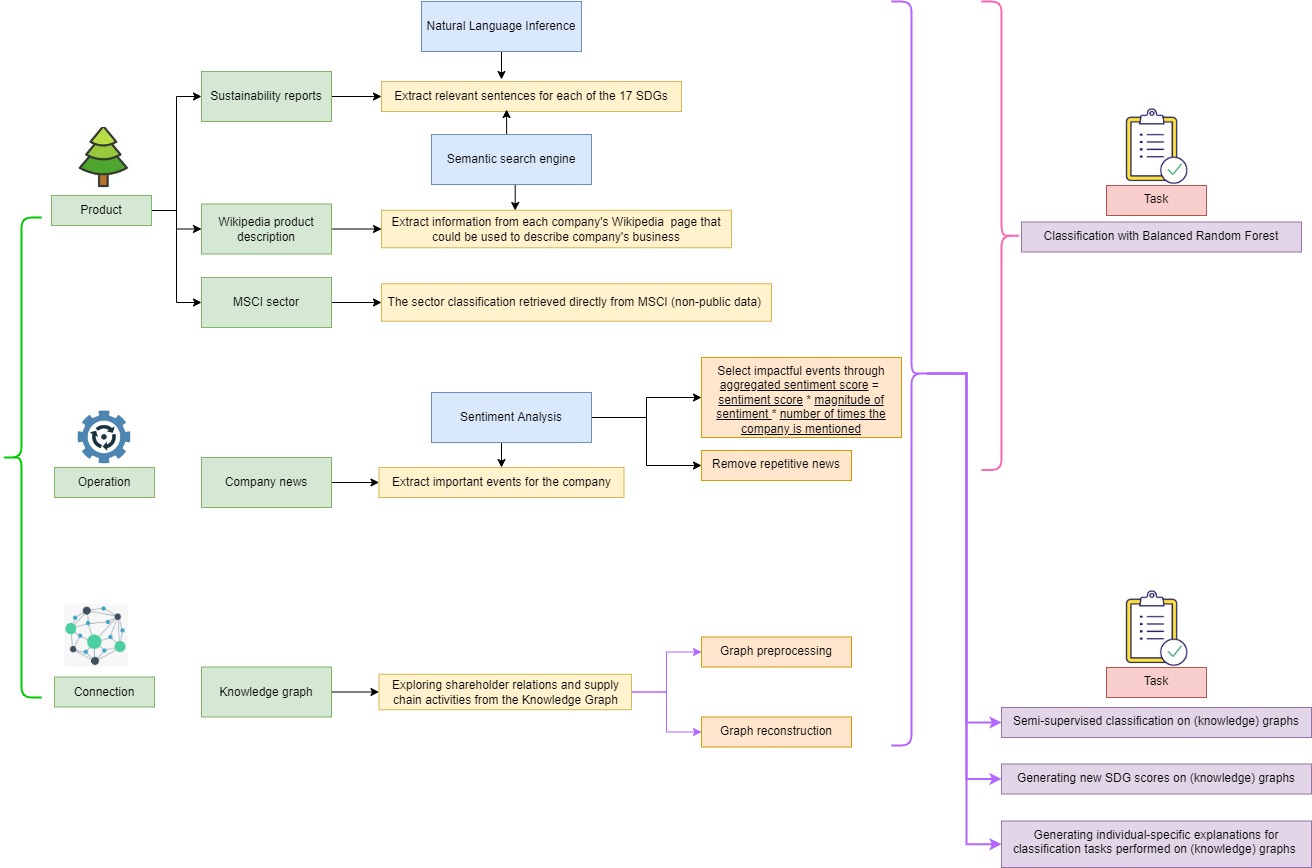
This slide was previously used for department presentation to other researchers at Robeco. It aims at providing an intuitive explanations on the thesis without involving to much technical details. Please unzip the slides.zip and click on presentation.html inside the folder to open the slides. For old audients who attended the first presentation, you can start to read from page 16 onwards (otherwise it might be a better idea starting from page 1). You may click on the components of the page (green buttons, icons, etc.) to interact with it as it will show you more details regarding how each step is done or the intuition behind.
The slides contain the following sections:
-
data engineering pipeline
-
the modelling of text data with modern NLP techniques for each part (reports/Wikipedia/news/KG)
-
the insights from the classification results for predicting MSCI SDG product/operation scores with the data in step (1)
-
generative models on graphs for integrating all the useful data to create the SDG framework and provide explanations (explainability + forecasting abilities)
The thesis in pdf format has been submitted, and you can also find it in this repository: ./master_AI_thesis_13167200.pdf
Create a conda environment with all the requirements (edit environment.yml)
conda env create -f environment.yml
If you want to change environment name
conda env create -n ENVNAME --file environment.ymlActivate the environment
source activate python3.7Or you can also use the pip to install the required packages via
pip install -r requirements.txtNote lots of results are saved in Jupyter notebooks, and there is a few things to keep in mind while running the Jupyter notebooks:
-
BertNLI requires transformer 2.5.1
-
Semantic search with vector_engine requires transformer >=4.16.2
-
Preprocessing sustainability reports require both semantic search and BertNLI thus remember to switch between transformer versions while running the code ./analysis_cleaned_report.ipynb (I have printed the transformer version before running NLI and semantic search just to remind about this).
-
The original vector_engine requires SentenceTransformer 0.3.8 but due to we use a new pretrained model from HuggingFace, it is required to use sentence-transformers >= 2.2.0 (e.g. sentence-transformers==2.2.2)
-
The environment file is produced from my conda environment on Windows10 with GPU Nvidia RTX 3070. You need to install the right version for torch, pytorch geometric according to your system and GPU (cuda version) by following the instructions from their official websites.
Note that all the classification results from BRF and GCN/RGCN is saved in the ./results folder.
Run group of BRF experiments with the following commands:
python run_product_MSCI.py f1_micro
python run_product_MSCI.py f1_macro
python run_news_MSCI.py f1_micro
python run_news_MSCI.py f1_macro
python run_net_MSCI.py f1_micro
python run_net_MSCI.py f1_macro
python run_net_RSAM.py f1_micro
python run_net_RSAM.py f1_macroRun group of GCN and RGCN experiments with the following commands:
python CG_MSCI_GCN.py 0.6 micro
python CG_MSCI_GCN.py 0.6 macro
python CG_RSAM_GCN.py 0.6 micro
python CG_RSAM_GCN.py 0.6 macro
python KG_MSCI_rGCN.py 0.6 micro
python KG_MSCI_rGCN.py 0.6 macro
python KG_RSAM_rGCN.py 0.6 micro
python KG_RSAM_rGCN.py 0.6 macro
# ablation study
python CG_MSCI_GCN.py 0.1 micro
python CG_MSCI_GCN.py 0.1 macro
python CG_MSCI_GCN_featureless.py 0.6 micro
python CG_MSCI_GCN_featureless.py 0.6 macroThese are the python and jupyter scripts where you can get the rest of the results. The jupyter notebooks already contained the results after execution. You can open these files with local Jupyter Notebook app or view it directly by openning the github website.
-
Dataset construction:
-
./wikidata.ipynb (one-hop KG extraction and wikipedia descriptions)
-
./KG_2hop.ipynb (two-hop KG extraction)
-
./get_domain_wikipedia_sus_url.ipynb (get url of domain, wikipedia, sustainability websites through Bing Search API)
-
./get_report.py (read and save the content of the pdf/sustainability reports)
-
./download_data_all.ipynb (filter the sustinability websites urls through search engine, get contents of sustainability websites, get raw wiki content)
-
./preprocessing.ipynb (this script contains making company graph, figures and summary statistics, tables in the thesis)
-
-
Preprocessing sustainability reports, news and wikipedia/wikidata:
-
./analysis_cleaned_report.ipynb
-
./analysis_cleaned_news.ipynb
-
./analysis_cleaned_wiki.ipynb
-
-
Generating SDG Scores:
-
./generate_score.py
-
./overlapping-community-detection/SDG_framework_new.py
-
-
Producing explanations with GNNExplainer:
- ./overlapping-community-detection/SDG_framework_new.py
-
Text classifier explained with LIME:
- ./explanation_text_classifier/...
We understand with multiple jupyter notebook scripts provided for data engineering pipeline would pose difficulty to understand the order of running these scripts. Hence, this section is to add some details for explaining the logic of how different parts of datasets are interlinked/produced.
-
analysis_cleaned_news.ipynb contains news_headlines.csv production
-
download_data_all.ipynb produce ./wiki_data/sus_reports_pdf_url.csv, ./wiki_data/sus_reports_pdf_url2.csv, temp.csv is generated as intermediate file for rank url; then ./wiki_data/sus_reports_content.tsv is generated; then rank sus web url from ./wiki_data/sus_reports_url.csv where temp2.csv is generated; then ./wiki_data/sus_web_content.csv is generated. Then wiki_data/wiki_content.csv is generated from ./wiki_data/wiki_url_final.csv.
-
wikidata.ipynb generate wiki_data/wikidata.csv and wiki_data/wiki_graph_data.csv KG_2hop.ipynb generate wiki_data/wiki_graph_data_2hop.csv and wiki_data/wiki_graph_data_2hop_description.csv
-
analysis_cleaned_report.ipynb produce ./temp_data/rank/ and further ./temp_data/entail
-
analysis_clearned_wiki.ipynb produce ./temp_data/wiki/wiki_product_info.csv (run with transformer 4.16.2)
-
get_domain_wikipedia_sus_url.ipynb contains code for get wiki_url, domain_url, sustainability_web_url
-
get_report.py extract content of pdf through fitz
The project tree is shown below with detailed description (inside of brackets) for scripts.
directory
│ analysis_cleaned_news.ipynb (preprocess the news and produce features sentiment related features and news headline feature)
│ analysis_cleaned_report.ipynb (preprocess the reorts with semantic search engine and NLI)
│ analysis_cleaned_wiki.ipynb (preprocess the Wikipedia pages by extracting the relevant product information)
│ download_data_all.ipynb (download data)
│ generate_score.py (heuristic way of generating scores, note the GNN method of generating scores is in SDG_framework_new.ipynb inside of folder overlap-community-detection)
│ get_domain_wikipedia_sus_url.ipynb (get url of companies' domain, sustainability reports and wikipedia, and these links will be used to extract content later)
│ get_report.py (download PDF reports and extract the content of the reports from sustainability reports url)
│ wikidata.ipynb (compose the Wikidata Knowledge Graph of our interests and this includes getting entity wiki id, relations)
| KG_2hop.ipynb (compose a bigger Wikidata Knowledge Graph from the extracted Wikidata Knowledge 1-hop graph)
│ CG_MSCI_GCN.py (GCN experiments on company graph with MSCI labels with different training ratios and F1 measures macro/micro and save results inside of ./results/KG)
│ CG_MSCI_GCN_featureless.py (running GCN with featureless approach on the company graph)
│ KG_MSCI_rGCN.py (RGCN experiments on the extracted Wikidata Knolwedge Graph with MSCI labels with different training ratiosand F1 measures macro/micro and save the results inside of ./results/KG)
│ CG_RSAM_GCN.py (GCN experiments on company graph with RSAM labels with different training ratios and F1 measures macro/micro and save results inside of ./results/KG)
│ KG_RSAM_rGCN.py (RGCN experiments on the extracted Wikidata Knolwedge Graph with RSAM labels with different training ratiosand F1 measures macro/micro and save the results inside of ./results/KG)
│ merge_fundamental_reports.ipynb (this script will produce ./wikidata/fundamental_report_merged.csv that can provide readers a brief view of the collected data)
│ preprocessing.ipynb (this script is mainly used to produce relevant figures or statistics displayed inside of the thesis along with some preprocessing that produces company graph)
│ README.md (documentation of the code)
│ requirements.txt (all the packages required to be installed to run the code)
│ requirements_vector_engine.txt (all the packages required to use the semantic search engine)
│ run_product_MSCI.py (BRF experiments with MSCI product scores)
│ run_news_MSCI.py (BRF experiments with MSCI operation scores)
│ run_net_MSCI.py (BRF experiments with MSCI net alignment scores/overall scores)
│ run_net_RSAM.py (BRF experiments with RSAM net alignment scores/overall scores)
│ bert_nli.py (BERT-based NLI model implemented by the paper Adapting by Pruning: A Case Study on BERT https://github.com/yg211/bert_nli)
│
├───data
│ │ companies.txt (companies of interests)
│ │ embeddings.pkl (embeddings produced by semantic search engine saved so next time only need to load without inference again)
│ │ embeddings_cleaned.pkl (embeddings produced by semantic search engine saved so next time only need to load without inference again)
│ │ embeddings_wiki.pkl (embeddings produced by semantic search engine saved so next time only need to load without inference again)
│ │ Fundamental.csv (MSCI sectors information)
│ │ msci.csv (MSCI data)
│ │ msci2.csv (MSCI data)
│ │ msci3.csv (RSAM data)
│ │ SDG_key_words.csv (SDG keywords list)
│ │
│ └───GDELT (raw news data)
│ news_data_with_content_0_99999.tsv
│ news_data_with_content_1000000_1099999.tsv
│ news_data_with_content_100000_199999.tsv
│ news_data_with_content_1100000_1199999.tsv
│ news_data_with_content_1200000_1299999.tsv
│ news_data_with_content_1300000_1399999.tsv
│ news_data_with_content_1400000_1499999.tsv
│ news_data_with_content_1500000_1599999.tsv
│ news_data_with_content_1600000_1699999.tsv
│ news_data_with_content_1700000_1799999.tsv
│ news_data_with_content_1800000_1849222.tsv
│ news_data_with_content_200000_299999.tsv
│ news_data_with_content_300000_399999.tsv
│ news_data_with_content_400000_499999.tsv
│ news_data_with_content_500000_599999.tsv
│ news_data_with_content_600000_699999.tsv
│ news_data_with_content_700000_799999.tsv
│ news_data_with_content_800000_899999.tsv
│ news_data_with_content_900000_999999.tsv
│
├───download_news (scripts and data involved with downloading news from GDELT)
│ │ download_data_url.py
│ │ news_data_analysis.ipynb
│ │ query_raw_file.py
│ │ run_commands.py
│ │
│ ├───data (filter news from GDELT)
│ │ merged_filtered_news_0_40000.csv
│ │ merged_filtered_news_119713_120000.csv
│ │ merged_filtered_news_120000_160000.csv
│ │ merged_filtered_news_40000_80000.csv
│ │
│ └───new
│ │ companies_wikipedia_corrected.csv
│ │ news_data.csv
│ │
│ └───content
│ news_data_with_content_0_99999.tsv
│ news_data_with_content_1000000_1099999.tsv
│ news_data_with_content_100000_199999.tsv
│ news_data_with_content_1100000_1199999.tsv
│ news_data_with_content_1200000_1299999.tsv
│ news_data_with_content_1300000_1399999.tsv
│ news_data_with_content_1400000_1499999.tsv
│ news_data_with_content_1500000_1599999.tsv
│ news_data_with_content_1600000_1699999.tsv
│ news_data_with_content_1700000_1799999.tsv
│ news_data_with_content_1800000_1849222.tsv
│ news_data_with_content_200000_299999.tsv
│ news_data_with_content_300000_399999.tsv
│ news_data_with_content_400000_499999.tsv
│ news_data_with_content_500000_599999.tsv
│ news_data_with_content_600000_699999.tsv
│ news_data_with_content_700000_799999.tsv
│ news_data_with_content_800000_899999.tsv
│ news_data_with_content_900000_999999.tsv
│
├───explanation_text_classifier (explaining the text classifier with LIME)
│ shap3-MSCI-SDG1.html
│ shap3-MSCI-SDG10.html
│ shap3-MSCI-SDG11.html
│ shap3-MSCI-SDG12.html
│ shap3-MSCI-SDG13.html
│ shap3-MSCI-SDG14.html
│ shap3-MSCI-SDG15.html
│ shap3-MSCI-SDG2.html
│ shap3-MSCI-SDG3.html
│ shap3-MSCI-SDG4.html
│ shap3-MSCI-SDG5.html
│ shap3-MSCI-SDG6.html
│ shap3-MSCI-SDG7.html
│ shap3-MSCI-SDG8.html
│ shap3-MSCI-SDG9.html
│ shap3-RSAM-SDG1.html
│ shap3-RSAM-SDG10.html
│ shap3-RSAM-SDG11.html
│ shap3-RSAM-SDG12.html
│ shap3-RSAM-SDG13.html
│ shap3-RSAM-SDG14.html
│ shap3-RSAM-SDG15.html
│ shap3-RSAM-SDG16.html
│ shap3-RSAM-SDG2.html
│ shap3-RSAM-SDG3.html
│ shap3-RSAM-SDG4.html
│ shap3-RSAM-SDG5.html
│ shap3-RSAM-SDG6.html
│ shap3-RSAM-SDG7.html
│ shap3-RSAM-SDG8.html
│ shap3-RSAM-SDG9.html
│
├───extra (some other analysis that could be mentioned inside of the thesis)
│ ├───case_study
│ │ case_study.ipynb
│ │ charts.ipynb
│ │ cora_extra.ipynb (cora dataset analysis)
│ │ distri_oper_msci.py
│ │ report-samsung.ipynb
│ │ samsung.csv
│ │
│ ├───excel_sheet
│ │ graph_stat.xlsx
│ │ property_name.csv
│ │ sus_sdg13_evidence_sample.csv
│ │
│ └───text_comparison (intertwined analysis of retrieved sentences from sustainability reports)
│ Convention-Visualization.html
│ Convention-Visualization2.html
│ Convention-Visualization3.html
│ Convention-Visualization4.html
│ Convention-Visualization5.html
│ Convention-Visualization6.html
│ Convention-Visualization7.html
│
├───figures (figures used inside of the thesis)
│ │ 17SDGs.png
│ │ barplot_kg.png
│ │ barplot_kg2.png
│ │ cora.PNG
│ │ cora_barplot.PNG
│ │ degree_count.png
│ │ degree_count2.PNG
│ │ degree_dist.png
│ │ degree_dist2.png
│ │ diagram.JPG
│ │ MSCI_NET_dist.png
│ │ MSCI_OPER_dist.png
│ │ MSCI_PROD_dist.png
│ │ MSCI_sector_bar.png
│ │ RSAM_dist.png
│ │ SDG13-12-Picture.PNG
│ │ SDG13-12.JPG
│ │ SDG13-5.JPG
│ │ SDG13-9-Picture.PNG
│ │ SDG13-9.JPG
│ │ SDG_number_of_companies.png
│ │ sector_classification.png
│ │ sus_report_wordcloud_SDG13.png
│ │
│ └───KG
│ MSCI_GCN_macro.PNG
│ MSCI_GCN_macro_0.1.PNG
│ MSCI_GCN_macro_featureless.PNG
│ MSCI_GCN_macro_featureless_0.1.PNG
│ MSCI_GCN_micro.PNG
│ MSCI_GCN_micro_0.1.PNG
│ MSCI_GCN_micro_featureless.PNG
│ MSCI_GCN_micro_featureless_0.1.PNG
│ MSCI_rGCN_macro.PNG
│ MSCI_rGCN_micro.PNG
│ RSAM_GCN_macro.PNG
│ RSAM_GCN_micro.PNG
│ RSAM_rGCN_macro.PNG
│ RSAM_rGCN_micro.PNG
│
├───generate (results obtained from heuristic way of generating SDG scores)
│ SDG_10_generated_score.csv
│ SDG_11_generated_score.csv
│ SDG_12_generated_score.csv
│ SDG_13_generated_score.csv
│ SDG_14_generated_score.csv
│ SDG_15_generated_score.csv
│ SDG_16_generated_score.csv
│ SDG_17_generated_score.csv
│ SDG_1_generated_score.csv
│ SDG_2_generated_score.csv
│ SDG_3_generated_score.csv
│ SDG_4_generated_score.csv
│ SDG_5_generated_score.csv
│ SDG_6_generated_score.csv
│ SDG_7_generated_score.csv
│ SDG_8_generated_score.csv
│ SDG_9_generated_score.csv
│
├───output (pretrained NLI model from bert_nli implementation https://github.com/yg211/bert_nli)
│ bert-base.state_dict (this is the one we use in this project)
│
├───overlapping-community-detection (the graph clustering package)
│ │ LICENSE
│ │ README.md
│ │ requirements.txt
│ │ SDG_framework_new.ipynb (this is our script of generating scores and explaining scores)
│ │ setup.py
│ │
│ ├───build
│ │ ......
│ ├───data (replicate the data folder at the root)
│ │ .......
│ ├───dist
│ │ .......
│ ├───nocd
│ │ .......
│ ├───nocd.egg-info
│ │ .......
│ ├───temp_data (replicate of temp_data at the root)
│ │ .......
│ ├───temp_data2 (replicate of temp_data2 at the root)
│ │ .......
│ └───wiki_data (replicate of wiki_data at the root)
│
├───results (classification results)
│ ├───all (BRF results MSCI net alignment score)
│ │ f1_macro.pkl
│ │ f1_micro.pkl
│ │
│ ├───all-rsam (BRF results RSAM net alignment score)
│ │ f1_macro.pkl
│ │ f1_micro.pkl
│ │
│ ├───excel (excel tables of results used inside of the thesis)
│ │ all_msci_macro.csv
│ │ all_msci_micro.csv
│ │ all_rsam_macro.csv
│ │ all_rsam_micro.csv
│ │ brf.xlsx
│ │ news_macro.csv
│ │ news_micro.csv
│ │ product_macro.csv
│ │ product_micro.csv
│ │
│ ├───KG (results from running graph algorithms)
│ │ msci_gcn_0.1_macro.pkl
│ │ msci_gcn_0.1_macro_featuresless.pkl
│ │ msci_gcn_0.1_micro.pkl
│ │ msci_gcn_0.1_micro_featuresless.pkl
│ │ msci_gcn_0.6_macro.pkl
│ │ msci_gcn_0.6_macro_featuresless.pkl
│ │ msci_gcn_0.6_micro.pkl
│ │ msci_gcn_0.6_micro_featuresless.pkl
│ │ msci_rgcn_0.6_macro.pkl
│ │ msci_rgcn_0.6_micro.pkl
│ │ rsam_gcn_0.1_macro.pkl
│ │ rsam_gcn_0.1_micro.pkl
│ │ rsam_gcn_0.6_macro.pkl
│ │ rsam_gcn_0.6_micro.pkl
│ │ rsam_rgcn_0.6_macro.pkl
│ │ rsam_rgcn_0.6_micro.pkl
│ │
│ ├───news (BRF results MSCI operation scores)
│ │ f1_macro.pkl
│ │ f1_micro.pkl
│ │
│ ├───product (BRF results MSCI product scores)
│ │ f1_macro.pkl
│ │ f1_micro.pkl
│ │
│ ├───PR_BRF_macro (macro precision recall curves of forecasting MSCI net alignment scores with BRF)
│ │ 1.pdf
│ │ 10.pdf
│ │ 11.pdf
│ │ 12.pdf
│ │ 13.pdf
│ │ 14.pdf
│ │ 15.pdf
│ │ 16.pdf
│ │ 17.pdf
│ │ 2.pdf
│ │ 3.pdf
│ │ 4.pdf
│ │ 5.pdf
│ │ 6.pdf
│ │ 7.pdf
│ │ 8.pdf
│ │ 9.pdf
│ │
│ └───PR_BRF_micro (micro precision recall curves of forecasting MSCI net alignment scores with BRF)
│ 1.pdf
│ 10.pdf
│ 11.pdf
│ 12.pdf
│ 13.pdf
│ 14.pdf
│ 15.pdf
│ 16.pdf
│ 17.pdf
│ 2.pdf
│ 3.pdf
│ 4.pdf
│ 5.pdf
│ 6.pdf
│ 7.pdf
│ 8.pdf
│ 9.pdf
│
├───temp_data (data during and after preprocessing)
│ │ df_merge_final.csv
│ │ embeddings_cleaned.pkl
│ │ embeddings_cleaned2.pkl
│ │ embeddings_wiki.pkl
│ │
│ ├───entail (reports evidence collection with respect to each SDG after NLI)
│ │ entail_SDG_1.csv
│ │ entail_SDG_10.csv
│ │ entail_SDG_11.csv
│ │ entail_SDG_12.csv
│ │ entail_SDG_13.csv
│ │ entail_SDG_14.csv
│ │ entail_SDG_15.csv
│ │ entail_SDG_16.csv
│ │ entail_SDG_17.csv
│ │ entail_SDG_2.csv
│ │ entail_SDG_3.csv
│ │ entail_SDG_4.csv
│ │ entail_SDG_5.csv
│ │ entail_SDG_6.csv
│ │ entail_SDG_7.csv
│ │ entail_SDG_8.csv
│ │ entail_SDG_9.csv
│ │
│ ├───mentioned (whether the definition of SDGk is mentioned with respect to each company, and the MSCI label is also included for comparison)
│ │ SDG_1.csv
│ │ SDG_10.csv
│ │ SDG_11.csv
│ │ SDG_12.csv
│ │ SDG_13.csv
│ │ SDG_14.csv
│ │ SDG_15.csv
│ │ SDG_16.csv
│ │ SDG_17.csv
│ │ SDG_2.csv
│ │ SDG_3.csv
│ │ SDG_4.csv
│ │ SDG_5.csv
│ │ SDG_6.csv
│ │ SDG_7.csv
│ │ SDG_8.csv
│ │ SDG_9.csv
│ │
│ ├───rank (reports relevant sentences collection with respect to each SDG after NLI)
│ │ ranked_SDG_1.csv
│ │ ranked_SDG_10.csv
│ │ ranked_SDG_11.csv
│ │ ranked_SDG_12.csv
│ │ ranked_SDG_13.csv
│ │ ranked_SDG_14.csv
│ │ ranked_SDG_15.csv
│ │ ranked_SDG_16.csv
│ │ ranked_SDG_17.csv
│ │ ranked_SDG_2.csv
│ │ ranked_SDG_3.csv
│ │ ranked_SDG_4.csv
│ │ ranked_SDG_5.csv
│ │ ranked_SDG_6.csv
│ │ ranked_SDG_7.csv
│ │ ranked_SDG_8.csv
│ │ ranked_SDG_9.csv
│ │
│ └───wiki (wikipedia product information)
│ wiki_product_info.csv
│ wiki_product_info2.csv
│
├───temp_data2 (preprocessing related to news)
│ features.csv
│ news_features.csv
│ news_headlines.csv (news headline features)
│ news_headlines2.csv
│ news_sentiment.csv (news sentiment features)
│
├───utils (this folder is from bert_nli package implementation)
│ .......
├───vector_engine (the semantic search engine package from https://github.com/kstathou/vector_engine )
│ .......
│
└───wiki_data (the final and intermediate data files from our data engineering pipeline)
companies_official_website.csv (produced by get_domain_wikipedia_sus_url.ipybn)
companies_sustainability_web.csv (produced by get_domain_wikipedia_sus_url.ipybn)
domain_correct.csv
fundamental_report_merged.csv
reports_and_web.csv
report_temp.csv
sustainability_reports.csv
sus_reports_content_alll1.tsv
sus_reports_content_alll2.tsv
sus_reports_pdf_url.csv
sus_reports_pdf_url2.csv
sus_reports_url.csv
sus_reports_url_top1.csv
sus_reports_url_top3.csv
sus_reports_url_top5.csv
sus_report_content.tsv
sus_web_content.csv
wikidata.csv
wiki_content.csv
wiki_graph_data.csv
wiki_graph_data_2hop.csv
wiki_graph_data_2hop_cleaned.csv
wiki_graph_data_2hop_description.csv
wiki_url.csv
wiki_url_final.csv-
Semantic Search with SentenceTransformers: kstathou/vector_engine: Build a semantic search engine with Transformers and Faiss (github.com)
-
Pytorch Geometric Framework: pyg-team/pytorch_geometric: Graph Neural Network Library for PyTorch (github.com)
-
GDELT Open Source Project: Announcing The Global Entity Graph (GEG) And A New 11 Billion Entity Dataset – The GDELT Project
-
MSCI SDG and RSAM SDG data provided by Robeco.
I would like to thank Robeco for providing me this unique opportunity and all the resources (particularly financial data from MSCI RSAM), and organizing frequent research sessions to discuss and track my development.
Robeco - The Investment Engineers, is an international asset manager that manages stocks and bonds. Our ‘pioneering yet cautious' attitude has been in their DNA since our founding in Rotterdam in 1929. They are advocates for sustainable investing, quantitative approaches, and continuous innovation. Robeco is always working to improve the way environmental, social, and governance (ESG) responsibilities are considered in investment choices.
Robeco is a PRI (Principles for Responsible Investment) signatory, a participant in the UNGC and the ICGN which are organizations that define guidelines for responsible business practise in the areas of human rights, labor, the environment, and corruption (https://www.investopedia.com/terms/u/un-global-compact.asp). They also signed the Dutch SDG Investing Agenda and several local stewardship codes. As of September 2021, they have more than 175 billion EUR assets integrating ESG With an extensive range of impact investing products, where they cater to investors with explicit ESG targets, like environmental footprint reduction, investors who wish to contribute to the SDGs, or invest in themes, like water or gender equality (The information is obtained through https://www.robeco.com/en/key-strengths/sustainable-investing/).