近些年,深度学习在多个学科上取得了巨大的成功,标志性的学科包括:图像识别、自然语言处理、语音识别、生物医学等。但是对于一些复杂的物理、生物和工程系统,获取合适规模的标注数据通常是困难的,先进的机器学习技术性能面临着巨大的挑战。
例如,采用深度学习方法,利用少量的标注数据学习高维的输入和输出数据之间的非线性映射似乎是难以完成的任务。但是对于一个物理系统,存在着大量的先验知识,最直观的方式是利用这些知识辅助深度神经网络的训练。这些先验知识可以是控制系统的动力学物理定律、经验验证的规则或其他领域的专业知识,利用先验信息作为正则化,限制模型搜索的解空间范围。
**PINN(Physics-Informed Neural Network)**将物理知识(比如物理定律,PDE,或者简化的数学模型)嵌入神经网络,从而设计出更好的机器学习模型。这些模型可以自动满足一些物理不变量,可以被更快地训练,达到更好的准确性。
科学计算在各门自然科学(物理学、气象学、地质学和生命科学等)和技术科学与工程科学(核技术、石油勘探、航空与航天和大型土木工程等)中起着越来越大的作用,在很多重要领域中成为不可缺少的工具。而科学与工程计算中最重要的内容就是求解在科学研究和工程技术中出现的各种各样的偏微分方程或方程组。
含有未知函数




常见的偏微分方程例子:
(1)Poisson方程
泊松方程是数学中一个常见于静电学、机械工程和理论物理的偏微分方程。形式如下:

(2)热传导方程
热传导方程(或称热方程)是一个重要的偏微分方程,它描述一个区域内的温度如何随时间变化。

(3)波动方程
波动方程主要描述自然界中的各种的波动现象,包括横波和纵波,例如声波、光波和水波。波动方程抽象自声学,电磁学,和流体力学等领域。一般形式如下:

神经网络可以看作一个复合数学函数,网络结构设计决定了多个基础函数如何复合成复合函数,网络的训练过程确定了复合函数的所有参数。为了获得一个“优秀”的函数,训练过程中会基于给定的数据集合,对该函数参数进行多次迭代修正。
神经网络上的自动求导基于计算图构建和链式求导实现。深度学习框架如pytorch包含自动求导的包,可以直接调用。PyTorch中所有神经网络的核心是autograd包。autograd包为张量上的所有操作提供自动微分。
例如:
In [1]: x = torch.Tensor(1)
In [2]: x.requires_grad=True
In [3]: y = x * 2
In [4]: grad = torch.autograd.grad(y, x)
Out [4]: grad=2如果将神经网络看作一个通用的函数拟合器拟合
利用偏微分方程构建损失函数指导神经网络拟合的
Physics-informed neural networks (PINN) 具体的数学描述如下:
问题:

- 初始\边界条件 :
- 其他信息:


损失函数:

其中:



一维非线性薛定谔方程是一个经典的场方程,用于研究量子力学系统,包括非线性波在光纤、导波管波导中的传播、等离子体波等。
示例为带有循环边界条件的一维薛定谔方程如下:

其中微分方程的残差项为:

初始条件:

边界条件:

其中神经网络拟合的

首先,对于解


class PhysicsInfromedNN(nn.Module):
def __init__(self, layers, lb, ub):
super(PhysicsInfromedNN, self).__init__()
self.net_u = self.neural_net(layers)
self.lb = torch.Tensor(lb).cuda()
self.ub = torch.Tensor(ub).cuda()
# self.net_v = self.neural_net(layers)
def forward(self, x, t):
x.requires_grad_()
t.requires_grad_()
X = torch.cat((x, t), dim=1)
X = 2.0 * (X - self.lb) / (self.ub - self.lb) - 1.0
uv = self.net_u(X)
u = uv[:, 0:1]
v = uv[:, 1:2]
u_x = torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u), retain_graph=True, create_graph=True)[0]
v_x = torch.autograd.grad(v, x, grad_outputs=torch.ones_like(v), retain_graph=True, create_graph=True)[0]
return u, v, u_x, v_x
def neural_net(self, layers):
num_layers = len(layers)
layer_list = []
for i in range(num_layers - 2):
layer_list += [
nn.Linear(layers[i], layers[i + 1]),
nn.Tanh()
]
layer_list += [
nn.Linear(layers[-2], layers[-1]),
]
return nn.Sequential(*layer_list)使用pytorch自动微分求解




u_x = torch.autograd.grad(u, x, grad_outputs=torch.ones_like(u), retain_graph=True, create_graph=True)[0]
v_x = torch.autograd.grad(v, x, grad_outputs=torch.ones_like(v), retain_graph=True, create_graph=True)[0]
u_t = torch.autograd.grad(u, t, grad_outputs=torch.ones_like(u), retain_graph=True, create_graph=True)[0]
u_xx = torch.autograd.grad(u_x, x, grad_outputs=torch.ones_like(u_x), create_graph=True)[0]
v_t = torch.autograd.grad(v, t, grad_outputs=torch.ones_like(v), retain_graph=True, create_graph=True)[0]
v_xx = torch.autograd.grad(v_x, x, grad_outputs=torch.ones_like(v_x), create_graph=True)[0]通过偏微分方程、边界条件、初始条件中
任务中的Loss包含三部分:
- 初始条件loss
从初始条件区域采点,这些区域点的值已知,使得网络预测与这点保持一致。

其中

u0_pred, v0_pred, _, _ = net(x0, t0)
loss_0 = criterion(u0, u0_pred) + criterion(v0, v0_pred)- 循环边界条件loss
在边界条件区域,边界区域


其中
u_lb_pred, v_lb_pred, u_x_lb_pred, v_x_lb_pred = net(x_lb, t_lb)
u_ub_pred, v_ub_pred, u_x_ub_pred, v_x_ub_pred = net(x_ub, t_ub)
loss_b = criterion(u_lb_pred, u_ub_pred) + criterion(v_lb_pred, v_ub_pred)
+ criterion(u_x_lb_pred, u_x_ub_pred) + criterion(v_x_lb_pred, v_x_ub_pred)- 残差loss

其中:
其中

def net_f_uv(net, x, t):
u, v, u_x, v_x = net(x, t)
u_t = torch.autograd.grad(u, t, grad_outputs=torch.ones_like(u), retain_graph=True, create_graph=True)[0]
u_xx = torch.autograd.grad(u_x, x, grad_outputs=torch.ones_like(u_x), create_graph=True)[0]
v_t = torch.autograd.grad(v, t, grad_outputs=torch.ones_like(v), retain_graph=True, create_graph=True)[0]
v_xx = torch.autograd.grad(v_x, x, grad_outputs=torch.ones_like(v_x), create_graph=True)[0]
f_u = u_t + 0.5 * v_xx + (u ** 2 + v ** 2) * v
f_v = v_t - 0.5 * u_xx - (u ** 2 + v ** 2) * u
return f_u, f_v
f_u_pred, f_v_pred = net_f_uv(net, x_f, t_f)
loss_f = criterion(f_u_pred, torch.zeros_like(f_u_pred)) + criterion(f_v_pred, torch.zeros_like(f_v_pred))- 有监督损失函数(如果有观测值)
从除初始和边界条件等已知区域采点,这些区域点作为观测值,使得网络预测与已知观测值保持一致。

其中
在PINN中,大多数采用L-BFGS优化器进行训练。采用5层全连接神经网络,其中隐层神经单元数量为100。采用tanh激活函数。从初始边界采样50个点、循环边界采样50个点,求解区域中采样20000个配置点,最终训练loss为:

- 训练结果展示
最终网络训练效果如下,其中上部分为整个时空区域解

薛定谔方程求解示例在schrodinger.py文件中已给出。
详细了解PINN和Schrodinger's方程求解,请仔细阅读参考文献Physics Informed Deep Learning (Part I): Data-driven Solutions of Nonlinear Partial Differential Equations
Burgers方程出现在应用数学的各个领域,包括流体力学、非线性声学、气体动力学和交通流等。这是一个基础的偏微分方程,可以从Navier-Stokes方程中去掉压力梯度项而得到。
本示例求解如下带有狄利克雷边界条件的一维Burgers方程。

其中微分方程的残差项为:

初始条件:

边界条件:

与求解薛定谔方程相比,预测值为实数而非复数,神经网络的输出维度为1,本任务更简单。
首先,对于解
使用pytorch自动微分求解


通过偏微分方程、边界条件、初始条件中
- 残差项损失函数

其中
- 初始/边界条件损失函数
从初始和边界条件区域采点,这些区域点的值已知,使得网络预测与这点保持一致。

其中
已知数据burgers_shock.mat
usol: 已知解,256x100.
t: 已知解中的时间维度值,100x1
x: 已知解中的空间坐标值,256x1
数据读取函数prepare_data已实现并提供使用。
任务:
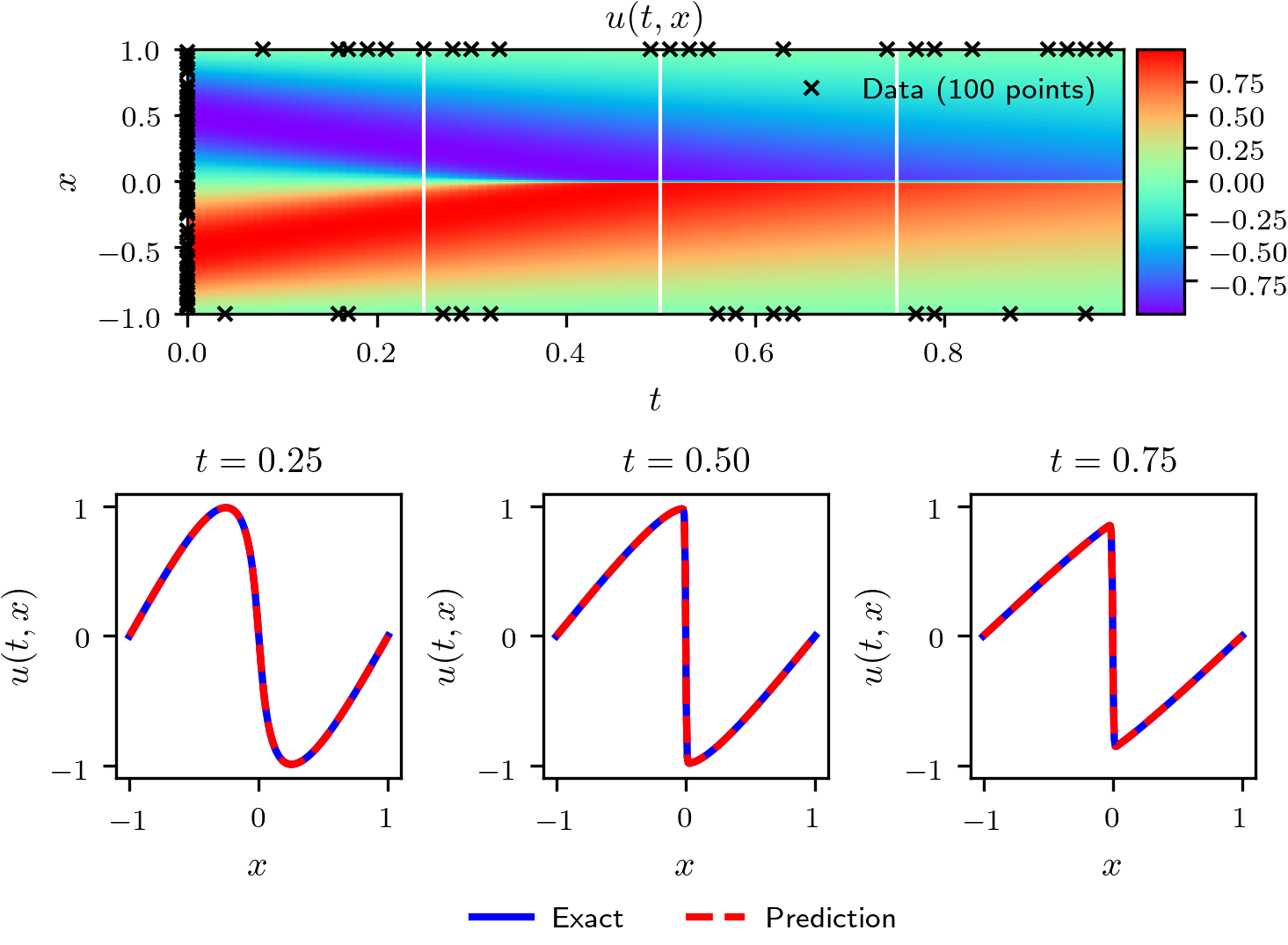
1.实现PINN求解Burgers方程,并可视化整个时空域上的求解结果,并展示0.30、0.60和0.90时刻求解结果。展示示例如下:
2. 讨论采样点数量对求解结果的影响,表格示例如下:
|
|||
|---|---|---|---|
|
3000 | 6000 | 9000 |
| 40 | |||
| 80 | |||
| 160 |
3.讨论神经网络规模对求解结果的影响,表格示例如下:
| 隐层单元数 | |||
|---|---|---|---|
| 神经网络层数 | 10 | 20 | 40 |
| 2 | |||
| 4 | |||
| 8 |
4.讨论优化器对求解结果的影响,表格示例如下:
| 优化器 | |
|---|---|
| SGD | |
| Adam | |
| L-BFGS | |
| .... |
[2] 内嵌物理的深度学习
[3] 偏微分方程在物理学中的完美应用——热方程,推导和示例
[4] 机器学习之自动求导
[6] Tensorflow实现代码参考
感谢以下仓库的工作。