The boom of e-commerce has resulted in 96% of Americans shopping online [1] and billions of customers worldwide[2]. With so many options in the realm of online shopping, a major goal in e-commerce is customer retention. A common approach to achieving this is through specialized marketing techniques. It is not feasible, however, to develop marketing techniques specific to each individual customer. If the customer pool can be segmented into smaller groups, then the time required to develop effective marketing techniques can be reduced -- which is why it is important for companies to understand their customer base and identify the most valuable ones.
Online retailers have enormous customer pools and customers often share similar traits. There may be, however, a better way to identify customers than simply grouping them by their location or gender. Customers are a source of revenue and it would be more advantageous to segment customers based on metrics that are associated with profits.
How can we identify the best customers?
Customer data has been obtained from an online retailer. The dataset is provided in the form of several tables obtained from a relational database. The primary key is the customer_id. The dataset only contains customer data prior to connection to an account manager. The following features are provided in the data:
- Total sales per customer
- Total orders per customer
- Total sales per Product Types per customer
- Total orders per Product Types per customer
- Total sales per Fiscal Quarter per customer
- Total orders per Fiscal Quarter per customer
- Customer shipping and billing zip code
- Cohort for each account manger
Per the request of the data provider, sensitive information regarding actual numbers for sales and amount of customers were scrubbed. Only the relative amounts are allowed to be presented. The product type categories were replaced with dummy names.
Customer sales does exist from other sources (e.g. Kaggle, UCI Machine Learning Repository), but they do not come from companies that use a business model that utilizes personal account managers.
The raw data is provided via several small tables. Each individual table is pivoted so that each row represents a record for a single customer. The pivoted tables are then merged together into a combined dataset.
A sample of the raw data for customer purchases per product_type is shown below:
| CUSTOMER_ID | PRODUCT_TYPE | SALES |
|---|---|---|
| cid1 | A | 799.9 |
| cid1 | C | 531.87 |
| cid1 | D | 375.96 |
| cid2 | B | 1062.31 |
| cid2 | E | 892.72 |
| cid2 | F | 366.22 |
| cid2 | G | 360.64 |
| cid2 | D | 239.9 |
| cid3 | B | 4256.53 |
| cid3 | C | 2612.06 |
| cid3 | H | 1235.27 |
The table after pivoting:
| CUSTOMER_ID | A | C | D | G | B | E | F | H |
|---|---|---|---|---|---|---|---|---|
| cid1 | 799.9 | 0 | 375.96 | 0 | 0 | 0 | 0 | 0 |
| cid2 | 0 | 139.95 | 239.9 | 360.64 | 1062.31 | 892.72 | 366.22 | 0 |
| cid3 | 799.9 | 2612.06 | 375.96 | 0 | 4256.53 | 0 | 0 | 1235.27 |
There are a total of 21 distinct product types. If a customer did not make any purchases for a given product_type, a 0 value is used. The same process is applied to the other raw data tables. The pivoted tables are joined together on the customer_id key to create a dataset formatted for analysis.
Furthermore, the data was pivoted so that each row represented information on a single customer. Using the pivot_table method in pandas resulted in numerous null values and they were replaced with 0. The data was further reduced to only customers with a billing address located in the US.
The customer locations data was filtered to only include customers located in the US. The data contains a state abbreviations column that had to be cleaned to deal with situations like:
- inconsistencies in upper and lower case abbrevations
- full state name used instead of abbrevations
Customer location, however, is not included in the feature set for the clustering algorithm. Location is considered more of a descriptive feature and it was thought best to avoid possibility of simply clustering customers by their location. From the perspective of the client, a customer's location should not necessarily be important. The goal of finding the most valuable customer should be based on metrics related to sales.
The code to conduct the analysis presented in this section can be found in
eda_for_customers.ipynb
The distribution of customer's in the sample per state is shown below:

Majority of the customers in the dataset are located in CA, CO, NY, UT, WA and TX. Three of those states are ranked as the top 4 in the US Census Bureau's population ranking [3]. It is interesting, however, to note that so many customers are also located in fairly low population states (CO,UT). Customer location is not as important when it comes to digital marketing compared to other media (e.g. print ads, tv commercials, billboards).
The overall distribution of customer sales per product_type is shown below:

The distribution shows that products from type B are the most expensive as very few customers have purchased from that category, but it has generated the most sales. Conversely, A and F products appear to be cheaper items due to the discrepancy from number of customers who have purchased it and the sales generated.
Marketing should be focused on customers purchasing high cost items from product_types such as E, I, O, R and S.
Looking into the variety of products that customers from each state buy, a plot of the amount of unique product_types purchased from customers in each state is shown below

Only the customer groups from CO and NJ have purchased all 20 possible product types. Most states hover around the 16 to 19 range. On the other end of the spectrum, customers from PW are only interested in only few specific types of products. States with lower count of product types may present some potential to increase via marketing. On the other hand, it can also be said that marketing should focus on the products customers are already buying.
The distribution of orders and sales per fiscal quarter is shown below:

As expected, the states with the most customers have the highest orders and sales per quarter. Although, both CO and UT customers outperform NY every quarter despite a smaller customer pool -- which may indicate that CO and UT customers are more valuable than NY customers.
It is also interesting to note is that Q2_orders total is significantly higher for NY than every other state by a wide margin. This did not directly translate to higher sales in the plot for Q2_sales. The discrepancy in Q2_orders and Q2_sales can be attributed to NY customers buying less expensive items.
To take advantage of the trends in seasonality, marketing approaches need to target customers who have highest sales per customer (e.g. UT and CO). Furthermore, the timing of the marketing campaigns should advantage of the most profitable quarters for customers from each state.
A heatmap of Pearson correlation coefficients calculated for the dataset is shown below:

The feature set consists of the 21 categories of product_type, amount of sales per fiscal quarter (e.g. Q1_sales), and amount of orders per fiscal quarter (e.g., Q2_orders). Majority of the features have positive, but weak linear correlation to each other. There are some instances of high correlation between product_types (e.g. F and G) which can be interpreted as product_types that customers often buy together.
There are also several examples of higher correlation coefficients between product_type and quarterly orders/sales (e.g., F and Q3_orders) which indicate that customers who buy in Q3 often buy items from F.
Fairly strong correlation is aso observed among quarterly sales. The highest correlation coefficients among all features can be found between Q4_sales and Q1_sales. This could possibly be due to customers buying gifts for the holiday season in Q4 and having to make gift exchanges in Q1 -- and exchange orders would count as a new sale.
A bubble chart showing the relationship between product_type, state, number of customers, and sales is shown below

The color of the markers represent the number of unique customers that have purchased given a product_type and state. The size of the markers represent the average of the sales made by those same customers.
The bubble chart shows that the most popular product_types -- based on number of customers who have purchased them -- are A,F,K,Q, and T for most locations. The most sales are generated from product type E across almost all states.
Specific product_types are much popular in certain states than others. It appears that customers from military addresses (AE) have generated the most sales for D type products. While customers in Guam (GU) have spent the most money on C, D and B. Products from H and K are quite popular among customers in the Northern Mariana Islands and Virgin Islands (VI) customers are fond of Q items.
A closer look at the state with the most customers (CA) shows that products from K have been bought from the most customers and also generated the most total sales.

The code to conduct the unsupervised learning and clustering analysis presented in this section can be found in the notebooks directory.
An unsupervised learning approach is used to conduct customer segmentation. The goal is to use clustering algorithms to be able to segment customers into informative groups.
The dataset is kept to continuous numerical features: the product_types, quarterly sales and orders. The data is scaled using the StandardScaler() method from sci-kit learn library. After scaling the data, Principal Components Analysis (PCA) is applied to the dataset. The resulting explained_variance_ratio from PCA is:
| PCA0 | PCA1 | PCA2 | PCA3 | PCA4 | PCA5 | PCA6 | PCA7 | PCA8 | PCA9 | PCA10 | PCA11 | PCA12 | PCA13 | PCA14 | PCA15 | PCA16 | PCA17 | PCA18 | PCA19 | PCA20 | PCA21 | PCA22 | PCA23 | PCA24 | PCA25 | PCA26 | PCA27 | PCA28 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.2284605 | 0.2893555 | 0.34382091 | 0.39476022 | 0.43490012 | 0.47336997 | 0.50902827 | 0.54393445 | 0.57858124 | 0.61295025 | 0.64680443 | 0.68018976 | 0.71259298 | 0.74354075 | 0.77250861 | 0.79802764 | 0.82239615 | 0.8442303 | 0.86501432 | 0.88359106 | 0.90179775 | 0.91936953 | 0.93643075 | 0.95107138 | 0.96453712 | 0.97538785 | 0.98470915 | 0.99278416 | 1.0 |
There are 29 features in the dataset and after conducting PCA, it takes 21 principial components to explain at least 90% of the variance in the data.
The code for running K-Means clustering can be found in the KMeans.ipynb. The dataset was processed using PCA with 21 components prior to applying MiniBatchKMeans.
As a baseline for clustering, the MiniBatchKMeans algorithm -- as opposed to KMeans -- is used from the sci-kit learn library due to limited time and resources. From sci-kit learn documentation [3]:
The MiniBatchKMeans is a variant of the KMeans algorithm which uses mini-batches to reduce the computation time, while still attempting to optimise the same objective function. Mini-batches are subsets of the input data, randomly sampled in each training iteration. These mini-batches drastically reduce the amount of computation required to converge to a local solution.
An example plot of the predicted labels of the dataset from MiniBatchKMeans for 6 clusters is provided below. The 2-D plots show pairs of principcal components in sequential order.

Attempts at evaluating K-Means clusters via silhouette analysis was not possible due to memory issues associated with the size of the dataset. Another common approach to determining the number of clusters for K-Means is the "elbow method"[4]. A plot of the inertia_ attribute of the MiniBatchKMeans class, however, shows no discernible elbow.

From visual inspection, the disadvantages of using KMeans on this dataset are clear. By minimizing distances, K-Means tends to partition the data into globular chunks as opposed to finding clusters[5]. Another disadvantage is that one must define the clusters in the beginning. From the elbow curve shown earlier, it is not clear how many clusters should be used.
The code for running DBSCAN clustering can be found in the DBSCAN.ipynb. The dataset was processed using PCA with 21 components prior to applying DBSCAN.
DBSCAN algorithm from sci-kit learn is evaluated on its ability to cluster customers. Compared to K-Means, one of the advantages of using DBSCAN is that the number of clusters does not have to be pre-defined. Furthermore, DBSCAN performs better for data that may not conform to globular chunks[6]:
DBSCAN is a density based algorithm – it assumes clusters for dense regions. It is also the first actual clustering algorithm we’ve looked at: it doesn’t require that every point be assigned to a cluster and hence doesn’t partition the data, but instead extracts the ‘dense’ clusters and leaves sparse background classified as ‘noise’.
The DBSCAN algorithm requires two parameters: eps and min_samples. In DBSCAN, a point is considered a core point if there are a minimum number of points (min_samples) that fall within a specified radius (eps)[4]. A grid search to tune these parameters is conducted. The results of the grid search is shown below with the number of clusters estimated and the number of points considered noise.

As expected, increasing eps reduces the number of clusters until they become one giant cluster including most of the data. Increasing min_samples also reduces the number of clusters while considering most of the data as noise. As a compromise between number of clusters and number of points considered noise, the final parameters are set to 1 and 5 for eps and min_samples, respectively. The 5 clusters estimated by DBSCAN are plotted below, but with the noise points removed for clarity. Each subplot represents different pairs of principal components.

The plots show that a majority of clusters belong to same cluster (0) with very customers belonging to the remaining 4 clusters. A breakdown of the number of customers contained within each clusters, as well the number of customers considered noise (label = -1), are summarized below:
| label | number of customers |
|---|---|
| -1 | 5804 |
| 0 | 26503 |
| 1 | 5 |
| 2 | 4 |
| 3 | 7 |
| 4 | 5 |
The code for analyzing the clustering results from DBSCAN can be found in the analyze_clusters.ipynb. The points considered noise are not included in the following analysis.
The array of 2D plots of the PCA components show that the DBSCAN algorithm appears to have performed better at clustering the customer data. One of the disadvantages of KMeans algorithm is that it will always build clusters in globular shapes. The plots of the DBSCAN results did not include -1 labels -- which represent "noise" in the data.
It is clear that most of the data is either considered noise or labeled as 0. The other 5 labels were applied to only a few customers each. The distributions of customer locations for each cluster are shown below:

The distributions of customers for the most populated clusters match the overall distribution of customers by location of the original dataset. This may reinforce the idea that customer location is not an important feature to consider if evaluating the value of a customer.
Plots of total sales and orders generated by customers for each cluster are shown below. As expected, customers labeled -1 (i.e., noise data points) have the highest totals since majority of the customers belong to this cluster.



The average metrics for each cluster, however, are a bit more interesting. Customers who were considered noise (label -1) continue to dominate in the averaged categories as well. The customers in label -1 significantly outperform customers from other clusters based on average order count. Following them, customers in label 3 average the highest number of orders for Q1 and Q4. Customers from label 1 average just a little less in orders for Q4, but hold the 2nd highest rank for average number of orders in Q2.

For quarterly sales, the disparity isn't as great between clusters. Customers from label -1 still dominate in this category, but customers from label 3 are a closer second in terms of average sales for Q1 and Q4. Customers from both -1 and 3 average the most sales in Q4, while the other clusters peak in other quarters.

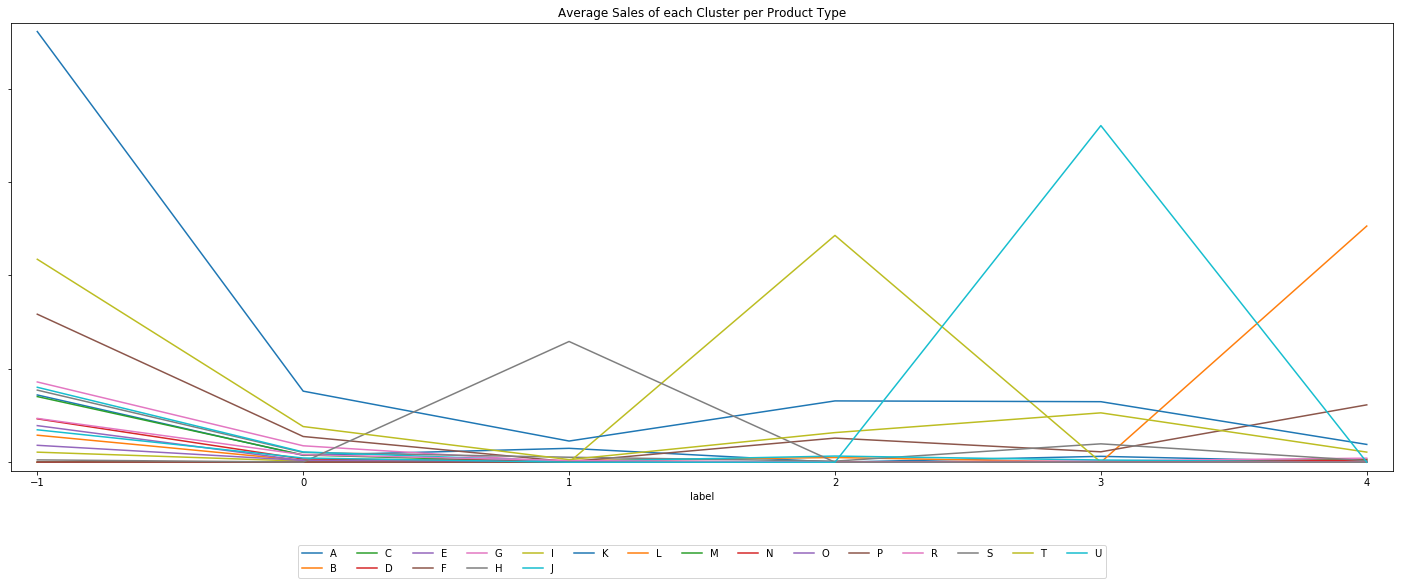
Plotting average sales per product type, the clusters appear to identify with product type. Customers from label -1 spend the most on products from A, label 0 customers tend to buy products from S, customers from 2 buy T products, customers from 3 buy U products, and customers from label 4 average the highest sales B products. Cross referencing the other plots regarding average sales in each quarter, customers spend a significant amount of money on products from A in Q4. On the other hand, initial findings in the previous EDA section showed that A products were fairly low in value (i.e., less expensive items). It was also determined that products from E were of the highest value and only customers from -1 purchased from that product group.
Boxplots of the customer metrics (e.g., sales, orders, and sales by product type) are shown below. The y-axes have been normalized for the group of subplots within each metric. When looking at the boxplots for sales and orders for each cluster, it seems like the most valuable customers are labeled as noise (-1). In fact, it appears DBSCAN may have identified the least valuable customers in its estimated clusters. As mentioned before, customers labeled (-1) dominated customers in the other clusters over all metrics and they are outliers in their value compared to the rest of the sample. Most of the customers are labeled 0 and they are considered the typical customer. The remaining clusters are differentiated from the group due to their focus on product types that aren't popular with the other customers in the sample.



Unsupervised techniques are applied to a dataset provided by an online retailer to conduct customer segmentation. The dataset contained a random sample of customers and their order history. The original dataset contained total sales per quarter, total orders per quarter, and total sales per product type for each customer. Customer location was also available, but not included in the feature set.
The dataset was processed via pivoting to have each product type as a feature and each quarter as a feature for both sales and orders. The pivoted dataset now had 29 features: 21 product types, 4 quarters for sales, and 4 quarters for orders.
K-Means was initially used to find clusters among the customer sample, but the structure of the dataset did not lend itself well to the algorithm. DBSCAN was chosen as an alternative approach to segment the customers. A grid search was conducted to tune the hyperparameters of DBSCAN and the optimal setup resulted in an estimate of 5 clusters -- the remaining points were considered noise.
After analyzing the clusters, it appears that DBSCAN had identified the average customer (label 0), , the very best customers (label -1), and the least valuable customers compared to the rest of the sample (remaining labels). The fact that the best customers were considered noise by DBSCAN could be due to the sparseness of the data. The dataset was pivoted so each column represented sales from a single product type, sales from a single quarter, and orders from a single quarter. It is similar to one-hot encoding. On the other hand, it is also possible that the most valuable customers may order above average amounts of specific product types as opposed to evenly distributing their purchases.
Moving forward, some additional work towards feature engineering may help further segment the largest cluster (label 0) as well as identify the points which are currently considered noise. Some additional features that may help include quarterly sales and orders per product type, front end stats (e.g. frequency of site visits, click data), and variations on customer location (e.g., distance from a competing brick & mortar store).