Storage engine experiment of LSM-tree. #443
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,6 @@ | ||
| [submodule "go-ycsb"] | ||
| path = go-ycsb | ||
| url = [email protected]:QingyangZ/go-ycsb.git | ||
| [submodule "snappy"] | ||
| path = snappy | ||
| url = https://github.com/google/snappy.git | ||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,72 @@ | ||
| # Welcome to the TinyEngine! | ||
| TinyEngine is a course designed to help you quickly familiarize yourself with the underlying storage engine of [TiKV Project](https://github.com/tikv/tikv). | ||
|
|
||
| After completing this course, you will have a better understanding of LSM-tree-based KV stores with high throughput, high scalability and high space utilization. | ||
|
|
||
| ## Course Introduction | ||
| TinyEngine is forked from open source [TinyKV](https://github.com/talent-plan/tinykv), a key-value storage system with the Raft consensus algorithm. TinyKV focuses on the storage layer of a distributed database system, which uses [badger](https://github.com/dgraph-io/badger), a Go library to store keys and values, as its storage engine. In order to get closer to the actual implementation of TiKV, TinyEngine plans to replace the original storage engine badger with [LevelDB](https://github.com/google/leveldb)/[RocksDB](https://github.com/facebook/rocksdb) wrapped by Golang. Therefore, please modify your implementation of project1 to use the interface of levigo(a wrapper of LevelDB) or gorocksdb(a wrapper of RocksDB) rather than badger. | ||
|
|
||
| In this course, you need to finish the implementation of LevelDB and then implement an existing optimization method on LevelDB/RocksDB. We provide a KV | ||
| Separation project [WiscKey](https://dl.acm.org/doi/abs/10.1145/3033273) in this folder, which introduce a classic and generally accepted optimization idea presented in recent famous paper. Please implement it on LevelDB. | ||
|
|
||
| After completing the implementation, you need to test and evaluate your optimization. We provide go-ycsb, which can be used to evaluate database performance. If you successfully implement a project, you will get better performance in reading or writing or some other dimension. Finally, you need to chart your evaluation results and submit a report and source code. The experts will give you an appropriate score depending on your optimization results and report. | ||
|
|
||
| After finish this course, you can try to implement other optimizations like [DiffKV](chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.usenix.org/system/files/atc21-li-yongkun.pdf). | ||
|
|
||
| ### LevelDB/RocksDB | ||
| [LevelDB](https://github.com/google/leveldb)/[RocksDB](https://github.com/facebook/rocksdb) is a storage engine for server workloads on various storage media, with the initial focus on fast storage (especially Flash storage). It is a C++ library to store key-value pairs. It supports both point lookups and range scans, and provides different types of ACID guarantees. | ||
|
|
||
| RocksDB borrows significant code from the open source [Leveldb](https://code.google.com/google/leveldb/) project and does a lot of performance optimization. It performs better than LevelDB under many real workloads and TiKV uses it as storage engine. However, RocksDB has a higher amount of code and is more difficult to learn. As a beginner's course for KV storage, TinyEngine requires you to complete the course with LevelDB. Besides, if you already have the knowledge of LSM-tree or enough coding ability, TinyEngine also provide code based on the RocksDB. | ||
|
|
||
| ## Evaluation & Report | ||
| After finishing the project, you need to present evaluation results that demonstrate the benefits of your optimization and write a report. After submitting, you will receive a score based on the optimization results and your report. | ||
|
|
||
| ### Go-ycsb | ||
| Go-ycsb is a Go port of YCSB. It fully supports all YCSB generators and the Core workload so we can do the basic CRUD benchmarks with Go. Please follow [go-ycsb](https://github.com/pingcap/go-ycsb/blob/master/README.md) to understand it. There are different workloads can be used in the go-ycsb/workloads folder. The specific parameters can be changed if needed. | ||
|
|
||
| ## Build TinyEngine from Source | ||
|
|
||
| ### Prerequisites | ||
|
|
||
| * `git`: The source code of TinyEngine is hosted on GitHub as a git repository. To work with git repository, please [install `git`](https://git-scm.com/downloads). | ||
| * `go`: TinyEngine is a Go project. To build TinyEngine from source, please [install `go`](https://golang.org/doc/install) with version greater or equal to 1.13. | ||
| * `leveldb`: LevelDB is a storage engine of TinyEngine, please [install `leveldb`](https://github.com/google/leveldb) with version greater or equal to 1.7. | ||
| * `rocksdb`: RocksDB is also a storage engine of TinyEngine, please [install `rocksdb`](https://github.com/facebook/rocksdb) with version greater or equal to 5.16. | ||
|
|
||
| ### Clone | ||
|
|
||
| Clone the source code to your development machine. | ||
|
|
||
| ```bash | ||
| git clone https://github.com/QingyangZ/tinydb | ||
| ``` | ||
|
|
||
| ### Build | ||
|
|
||
| Build TinyEngine from the source code. | ||
|
|
||
| ```bash | ||
| cd tinydb | ||
| make | ||
| ``` | ||
|
|
||
| ### Go-ycsb Test | ||
|
|
||
| Build go-ycsb and test TinyEngine | ||
|
|
||
| ```bash | ||
| cd go-ycsb | ||
| make | ||
| ``` | ||
|
|
||
| #### Load | ||
|
|
||
| ```bash | ||
| ./bin/go-ycsb load tinydb -P workloads/workloada | ||
| ``` | ||
|
|
||
| #### Run | ||
| ```bash | ||
| ./bin/go-ycsb run tinydb -P workloads/workloada | ||
| ``` | ||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,55 @@ | ||
| # Project1 LSM Tree | ||
| In this project, you will learn the basic architecture of LSM tree and finish the implementation of LevelDB, a representative LSM-tree-based key/value storage engine. | ||
|
|
||
| The log-structured merge-tree (also known as LSM tree, or LSMT) is a data structure with performance characteristics that make it attractive for providing indexed access to files with high insert volume, such as transactional log data. LSM trees, like other search trees, maintain key-value pairs. LSM trees maintain data in two or more separate structures, each of which is optimized for its respective underlying storage medium; data is synchronized between the two structures efficiently, in batches. | ||
|
|
||
| LSM tree is widely used in mainstream persistent KV storage systems like LevelDB and RocksDB. RocksDB, which is used as TiKV's storage engine, borrows significant code from the open source [Leveldb](https://code.google.com/google/leveldb/) project and does a lot of performance optimization. However, RocksDB has a higher amount of code and is more difficult to learn. As a beginner's course for KV storage, this project is based on LevelDB. | ||
|
|
||
| ### Architecture | ||
|  | ||
|
|
||
| A brief introduction to the architecture of LSM tree is provided later in this article. For more details, you can also read our collection of documents at <https://github.com/iridiumine/USTC_ADSL_KVgroup_docs>. | ||
|
|
||
|
|
||
| #### Memtable | ||
| `Memtable` is an in-memory component in which the data incoming from client requests is first written, which is basically a skip-list, an ordered data structure. After the skip-list has got enough entries and has hit its threshold memory it is transformed into an immutable Memtable, and then it waits to be flushed to the Disk, sorted in form of `SSTable`. | ||
|
|
||
| #### SSTable | ||
| `SSTable` or sorted string table as the name explains contains the entry in sorted format on keys on disk. When the sorted data from RAM is flushed to disk it is stored in form of `SSTable`. SSTables are divided into different levels, with lower levels storing newer entries and higher levels storing older entries. The SSTable within each level are ordered(except Level0) and the SSTables between the different levels are disordered. After the memtable has reach its threshold size, it is first flushed to Level0. After a while the entries will be moved to a higher level by `compaction`. | ||
|
|
||
| #### Log | ||
| `Log` in LevelDB is a write ahead log. As mentioned earlier, entries written by LevelDB is first saved to MemTable. To prevent data loss due to downtime, data is persisted to the log file before being written to MemTable. After Memtable is flushed to the disk, related data can be deleted from the log. | ||
|
|
||
| ### The Code | ||
| In this part, you will finish the implementation of LevelDB, which involves three important operations in LSM tree: Get/Compaction/Scan. It maintains a simple database of key/value pairs. Keys and values are strings. `Get` queries the database and fetches the newest value for a key. There may be multiple versions of the same key in the database because of the append nature of the LSM tree. `Compaction` merges some files into the next layer and does garbage collection. `Scan` fetches the current value for a series of keys. | ||
|
|
||
| #### 1. Get | ||
| The code you need to implement is in `db/db_impl.cc` and `db/version_set.cc`. | ||
| - Inside `db/db_impl.cc`, you need to complete the function `DBImpl::Get`(Blank1.1), which searches Memtable, immutable Memtable, and SSTable until the key is found and returns the value. | ||
| - Inside `db/version_set.cc`, you need to complete the function `Version::ForEachOverlapping`(Blank1.2) and the function `Version::Get`(Blank1.3). | ||
|
|
||
| #### 2. Compaction | ||
| In this part, the code you need to implement is in `db/db_impl.cc` and `db/version_set.cc`. | ||
| - Inside `db/db_impl.cc`, you need to complete the function `DBImpl::BackgroundCompaction`(Blank2.1) and the function `DBImpl::InstallCompactionResults`(Blank2.2). | ||
| - Inside `db/version_set.cc`, you need to complete the function `VersionSet::Finalize`(Blank2.3) and the function `VersionSet::PickCompaction`(Blank2.4) | ||
|
|
||
| #### 3. Scan | ||
| In this part, the code you need to implement is in `db/version_set.cc` and `table/merger.cc`. | ||
| - Inside `db/version_set.cc`, you need to complete the function `Version::AddIterators`(Blank3.1). | ||
| - Inside `table/merger.cc`, you need to complete the function `Seek`(Blank3.2). | ||
|
|
||
| ### Test | ||
|
|
||
| Make: | ||
| ```bash | ||
| cd leveldb | ||
| mkdir -p build && cd build | ||
| cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build . | ||
| ``` | ||
| Please see the CMake documentation and `CMakeLists.txt` for more advanced usage. | ||
|
|
||
| Test: | ||
| ```bash | ||
| ./db_bench | ||
| ``` | ||
| Please see the CMake documentation and `leveldb/benchmarks/db_bench.cc` for more advanced usage. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,45 @@ | ||
| # Project 1: KV Separation | ||
|
|
||
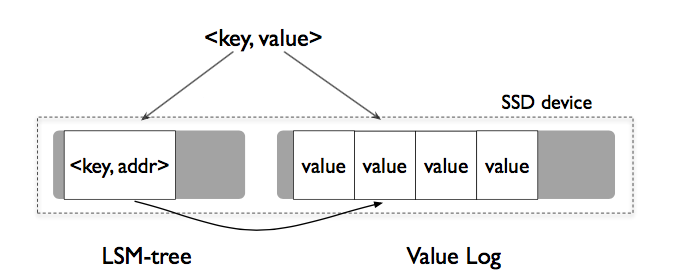
| KV Separation is inspired by the paper WiscKey published in the FAST Conference, whose main idea is to separate the keys from values to minimize the I/O amplification. It is the first project you need to implement. | ||
|  | ||
|
|
||
| ## Features | ||
| * WiscKey writes faster than LevelDB because the KV separation reduces write magnification and makes the compaction much more efficient, especially when KV size is large. | ||
| * The read performance of WiscKey may be a little poor than LevelDB, because KV Separation has the disadvantage of requiring one more operation to read value from disk. However, KV Separation allows the SST file to store more KV records, which greatly reduces the number of SST files. As a result, more KV records can be stored by the tablecache and blockcache. In conclusion, the read performance of KV Separation is not as bad as expected. | ||
| * The range operations become inefficient, because it changes from a sequential read to a sequential read plus multiple random reads. With the parallel IO capability of SSD, this loss can be offset as much as possible, which is due to the strong random access performance of SSD. | ||
|
|
||
| ## Code Guidance | ||
| Here are some steps to implement this project. (You can also complete this project in your own way) | ||
|
|
||
| ### Prerequisites | ||
| `leveldb`: the basic storage engine of TinyDB. Please learn the architecture of LSM-Tree by its wiki or readme text. In terms of code, you should at least know the implemetation of Read(function `DBImpl::Get` in `leveldb/db/db_impl.cc`), Write(function `DBImpl::Write` in `leveldb/db/db_impl.cc`) and Compaction (function `DBImpl::BackgroundCompaction` in `leveldb/db/db_impl.cc`). | ||
|
|
||
| `rocksdb`: if you already have a good understanding of leveldb and plan to implement the project on rocksdb, please learn the implemetation of its Read(function `DBImpl::Get` in `rocksdb/db/db_impl/db_impl.cc`), Write(function `DBImpl::WriteImpl` in `rocksdb/db/db_impl/db_impl_write.cc`) and Compaction(function `DBImpl::BackgroundCompaction` in `rocksdb/db/db_impl/db_impl_compaction_flush.cc`). | ||
|
|
||
| ### Initialization | ||
| First, you need to initialize a vLog file to store values. For convenience, the original log file structure of leveldb and rocksdb can be use for reference. Take leveldb as an example. The original log file is initialized when the database is opened in the function `DB::Open` (`leveldb/db/db_impl.cc`). Please implement a function to initialize a new vLog file. | ||
|
|
||
| ### Write | ||
| Unlike LevelDB, the KV pairs are first written to the vLog file. The record written to the memtable and SST files is actually <key,address>. The address points to the offset of the KV pairs in the vLog file. Therefore, the function `DBImpl::Write` (`leveldb/db/db_impl.cc`) needs to be modified. First, write the value into the vLog file and get the address. Then write key, address and log_number into LSM tree. | ||
|
|
||
| ### Read | ||
| The result read from a memtable or SST file is actually an address pointing to a location in the vLog file. As a result, the function `DBImpl::Get` (`leveldb/db/db_impl.cc`) alse needs to be modified. After getting the address and log_number from LSM tree, the real value needs to be read from the vLog file pointed from the address. | ||
|
|
||
| ### Crash Consistency | ||
| In LevelDB's implementation, when immemtbale is flushed into the SST files successfully and the change is already logged in the manifest file (VersionSet::LogAndApply succeeds), the LOG file will be deleted. Otherwise, the database will replay the log file during recovery. | ||
|
|
||
| However, vLog file cannot be deleted in KV Separation, because the contents of each value are still stored here. So what to do when recovering from failure? It is impossible to replay the vLog file from beginning to end. WiscKey's approach is to add `HeadInfo:pos` to VersionEdit before immemtable being flushed. `HeadInfo:pos` means the checkpoint in vLog, which means that the KV record before `HeadInfo:pos` has been successfully written to the SST files. When recovering, `VersionSet::Recover` (`leveldb/db/version_set.cc`) will replay the edit record, get the HeadInfo. After getting the `HeadInfo:pos`, it will replay the vLog file from the pos location. | ||
|
|
||
| ### Garbage Collection | ||
| Key-value stores based on standard LSM-trees do not immediately reclaim free space when a key-value pair is deleted or overwritten. During compaction, if data relating to a deleted or overwritten key-value pair is found, the data is discarded and space is reclaimed. In WiscKey, only invalid keys are reclaimed by the LSM tree compaction. Since WiscKey does not compact values, it needs a special garbage collector to reclaim free space in the vLog. | ||
|
|
||
|  | ||
|
|
||
| WiscKey targets a lightweight and online garbage collector. To make this possible, WiscKey introduces a new data layout as shown in the figure above: the tuple (key size, value size, key, value) is stored in the vLog. | ||
|
|
||
| During garbage collection, WiscKey first reads a chunk of key-value pairs (e.g., several MBs) from the tail of the vLog, then finds which of those values are valid (not yet overwritten or deleted) by querying the LSM-tree. WiscKey then appends valid values back to the head of the vLog. Finally, it frees the space occupied previously by the chunk, and updates the tail accordingly. | ||
|
|
||
| Please implement a garbage collection function which should be called when appropriate. For example, you can record `drop_count` which means the number of invalid keys during compactions (function `DBImpl::BackgroundCompaction` in `leveldb/db/db_impl.cc`). When `drop_count` reaches a certain threshold, garbage collection is triggered. | ||
|
|
||
| ## Optimizations | ||
| The above implementation still has many shortcomings. The paper also mentions some optimizations you can implement. Moreover, it is better if you have other optimization ideas and implement them, which will get you a higher score. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Oops, something went wrong.
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
There was a problem hiding this comment.
Choose a reason for hiding this comment
The reason will be displayed to describe this comment to others. Learn more.
You can file another PR to https://github.com/pingcap/go-ycsb?