Capacity Expansion
In heterogeneous memory systems, each type of memory has its own performance characteristics so improper data placement can lead to significant performance degradation. HMSDK provides a way to manage tiered memory systems expanding memory capacity. This is supported via DAMON framework in the Linux kernel and its DAMON-based Operation Schemes, called DAMOS. The DAMON monitors data access in a lightweight way, then DAMOS applies some useful memory management actions based on the data access patterns collected by DAMON.
HMSDK supports two DAMOS actions; migrate_cold for demotion from fast tiers and migrate_hot for promotion from slow tiers. The fast and slow tiers can be thought of as local DRAM and CXL/PCIe-attached DRAM, which will simply be referred to as CXL memory.
This prevents hot pages from being stuck on slow tiers, which makes performance degradation and cold pages can be proactively demoted to slow tiers so that the system can increase the chance to allocate more hot pages to fast tiers.
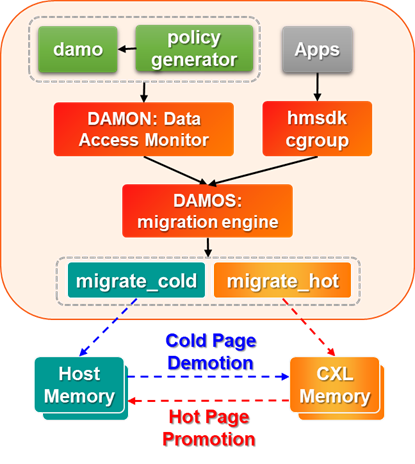
The damo user space tool helps enabling DAMON and applying those DAMOS actions based on the given yaml config file generated by tools/gen_migpol.py. This can be especially useful when the tiered memory system has high memory pressure on its first tier DRAM NUMA nodes by efficiently utilizing the second tier CXL NUMA nodes.
This section describes the HMSDK components.
linux: Linux kernel for HMSDK support
- page demotion and promotion implementation in DAMON(Data Access MONitor).
damo: userspace tool for tiered memory management
- user space tool that enables migration between fast and slow memory tiers.
tools: HMSDK tools contain
-
gen_migpol.pythat generates a damo migration policy for tiered memory management scheme.
You can download HMSDK repository from GitHub. Make sure to run git clone with
--recursive since HMSDK includes additional repositories as submodules.
$ git clone --recursive https://github.com/skhynix/hmsdk.git
$ cd hmsdk
This includes downloading the entire linux git history, so git cloning with
--shallow-submodules will significantly reduce the download time.
Please read this link for the general linux kernel build.
Since HMSDK takes advantages of DAMON in Linux kernel, additional DAMON related build configurations have to be enabled as follows.
$ cd hmsdk/linux
$ cp /boot/config-$(uname -r) .config
$ echo 'CONFIG_DAMON=y' >> .config
$ echo 'CONFIG_DAMON_VADDR=y' >> .config
$ echo 'CONFIG_DAMON_PADDR=y' >> .config
$ echo 'CONFIG_DAMON_SYSFS=y' >> .config
$ echo 'CONFIG_MEMCG=y' >> .config
$ echo 'CONFIG_MEMORY_HOTPLUG=y' >> .config
$ make menuconfig
$ make -j$(nproc)
$ sudo make INSTALL_MOD_STRIP=1 modules_install
$ sudo make headers_install
$ sudo make install
After rebooting the machine, you can run uname -r to verify if the kernel has been installed correctly.
$ uname -r
6.12
Regarding the damo usage, please refer to damo usage.
gen_migpol.py is a python script that can generate a proper damo config file
for HMSDK tiered memory management scheme.
For example, if the system contains a CXL memory recognized as NUMA node 1 as the hardware topology shown in the following example.
$ numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
node 0 size: 515401 MB
node 0 free: 379471 MB
node 1 cpus:
node 1 size: 96761 MB
node 1 free: 96659 MB
node distances:
node 0 1
0: 10 14
1: 14 10
Its topology looks as follows.
$ lstopo-no-graphics -p | grep -E 'Machine|Package|NUMANode'
Machine (599GB total)
Package P#0
NUMANode P#0 (503GB)
NUMANode P#1 (96GB)
Then a config file can be generated that demotes cold pages from node 0 to 1 and promotes hot pages from node 1 to 0 as follows.
$ sudo ./tools/gen_migpol.py --demote 0 1 --promote 1 0 -o hmsdk.yaml
Please note that the generated hmsdk.yaml contains cgroup filter under the
cgroup name as "hmsdk" by default.
If you want to apply HMSDK globally, use -g/--global option when running
gen_migpol.py as follows.
$ sudo ./tools/gen_migpol.py -d 0 1 -p 1 0 -g -o hmsdk.yaml
Please note that -d and -p are short options of --demote and --promote.
HMSDK offers support for hot/cold memory tiering through the use of DAMON and its userspace tool, damo. To begin using HMSDK, ensure that you have installed the HMSDK kernel along with DAMON. To check if DMAON is properly installed, enter the following command:
$ if grep CONFIG_DAMON /boot/config-$(uname -r); then echo "installed"; fi
To start HMSDK, you can use the damo tool. Before starting, ensure that you have a proper configuration file.
# The -d/--demote and -p/--promote options can be used multiple times.
# The SRC and DEST are migration source node id and destination node id.
$ sudo ./tools/gen_migpol.py -d SRC DEST -p SRC DEST -o hmsdk.yaml
# Enable demotion to slow tier. This prevents from swapping out from fast tier.
$ echo true | sudo tee /sys/kernel/mm/numa/demotion_enabled
# make sure cgroup2 is mounted under /sys/fs/cgroup, then create "hmsdk" directory below.
$ sudo mount -t cgroup2 none /sys/fs/cgroup
$ echo '+memory' | sudo tee /sys/fs/cgroup/cgroup.subtree_control
$ sudo mkdir -p /sys/fs/cgroup/hmsdk
# Start HMSDK based on hmsdk.yaml.
$ sudo ./damo/damo start hmsdk.yamlPlease refer to the detail usage of gen_migpol.py at Tools section below.
$ sudo ./damo/damo stop
If the target workloads are bandwidth hungry, then hot data is better to be distributed in DRAM and CXL memory and that is bandwidth expansion mode.
However, if the target workloads are not bandwidth hungry and rather capacity hungry, then hot data shouldn't reside on CXL memory because it will make performance degradation due to the PCIe protocol overheads.
If the target workload can fully fit in DRAM, then it's always better to use DRAM only. But the workload cannot fully fit in DRAM at fast tier, then some hot data can be allocated in CXL memory at slow tier if the DRAM capacity is mostly occupied by some other data and some amount of them can be cold data as TMO and TPP papers mentioned. That means there are enough chances the target workloads of our interest can be mainly allocated on CXL memory unfortunately.
The effectiveness of HMSDK's tiered memory management scheme can be useful in this kind of memory pressured situation so our experimental environment allocates some amount of cold data before running and measuring the target workload's execution time.
The experimental setup consists of two NUMA nodes, node0 in 512GB of DRAM and node1 in 96GB of CXL memory node, which is a cpuless NUMA node.
The evaluation was done using a widely used in-memory database redis and YCSB for generating memory access patterns.
In order to make the memory pressured environment, the cold data is generated using mmap and memset, then the redis-YCSB workloads are executed.
The YCSB execution time was measured multiple times by gradually increasing 10GB of cold data each execution. In other words, the free space in DRAM gets decreased for each evaluation and that makes more redis data is allocated on CXL memory due to insufficient free space at DRAM.
The HMSDK is compared with 4 different settings as follows:
| Case | Description |
|---|---|
| DRAM-only | redis-server uses only local DRAM memory. |
| CXL-only | redis-server uses only CXL memory. |
| Default | default memory policy(MPOL_DEFAULT). numa balancing disabled. |
| HMSDK | DAMON enabled with migrate_cold for DRAM node and migrate_hot for CXL node. |
All the result values are normalized to the execution time of DRAM-only. The DRAM-only execution time is the ideal result without being affected by the performance gap between DRAM and CXL.
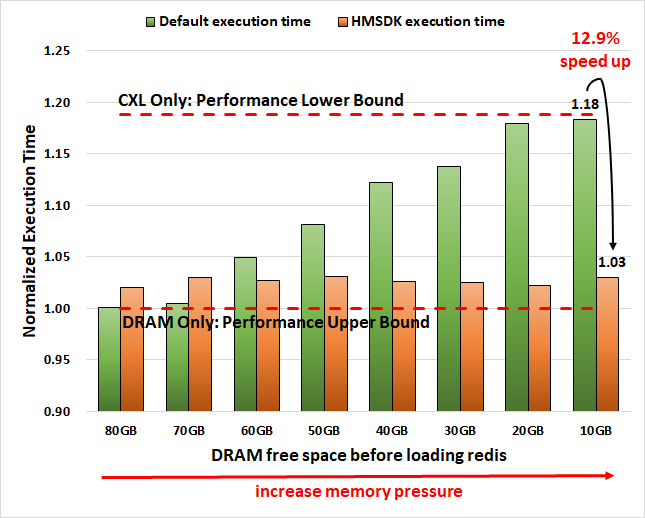
The above results show that the "Default" execution time increases as DRAM free space decreases from 80GB to 10GB. This is because, as memory pressure increases, more CXL memory is utilized for the target Redis workload.
However, the HMSDK results show less slowdown because the migrate_cold action at the DRAM node proactively demotes pre-allocated cold data to the CXL node, increasing free space in the DRAM. This creates more opportunities to allocate hot or warm pages of the redis server to the faster DRAM node. Furthermore, the migrate_hot action at the CXL node actively promotes hot pages of the redis-server to the DRAM node. As a result, the performance gap between "Default" and "HMSDK" widens as memory pressure increases.
The following result shows the same information but in a table format.
| 80GB | 70GB | 60GB | 50GB | 40GB | 30GB | 20GB | 10GB | ||
|---|---|---|---|---|---|---|---|---|---|
| DRAM-only | 1.00 | - | - | - | - | - | - | - | - |
| CXL-only | 1.19 | - | - | - | - | - | - | - | - |
| Default | - | 1.00 | 1.00 | 1.05 | 1.08 | 1.12 | 1.14 | 1.18 | 1.18 |
| HMSDK | - | 1.02 | 1.03 | 1.03 | 1.03 | 1.03 | 1.02 | 1.02 | 1.03 |
Please note that the "HMSDK" results of 80GB and 70GB are a bit worse than "Default" because almost all of redis data is already allocated at the fast DRAM node even for "Default" while "HMSDK" monitoring and migration overheads make it a little bit slower.
The results from 60GB to 10GB clearly show the slowdown of "Default" compared to DRAM grows linearly from 5%, 8%, 12%, 14%, 18%, 18%, but the slowdown of "HMSDK" stays 2% ~ 3% in all the cases. In terms of speedup at the highest memory pressured environment, "HMSDK" shows 12.9% speedup at the worst case compared to the "Default" result.
As a result, having HMSDK's migrate_cold and migrate_hot actions can enhance the efficiency of tiered memory systems, particularly under high memory pressures, by utilizing HMSDK's operation schemes.