-
Notifications
You must be signed in to change notification settings - Fork 106
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Merge pull request #32 from roboflow/feature/foundations_of_training_…
…readme updated project `README` to showcase new project profile
- Loading branch information
Showing
1 changed file
with
13 additions
and
120 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,142 +1,35 @@ | ||
|
|
||
| <div align="center"> | ||
|
|
||
| <h1>multimodal-maestro</h1> | ||
| <h1>maestro</h1> | ||
|
|
||
| <br> | ||
|
|
||
| [](https://badge.fury.io/py/maestro) | ||
| [](https://github.com/roboflow/multimodal-maestro/blob/main/LICENSE) | ||
| [](https://badge.fury.io/py/maestro) | ||
| [](https://huggingface.co/spaces/Roboflow/SoM) | ||
| [](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/multimodal_maestro_gpt_4_vision.ipynb) | ||
| <p>coming: when it's ready...</p> | ||
|
|
||
| </div> | ||
|
|
||
| ## 👋 hello | ||
|
|
||
| Multimodal-Maestro gives you more control over large multimodal models to get the | ||
| outputs you want. With more effective prompting tactics, you can get multimodal models | ||
| to do tasks you didn't know (or think!) were possible. Curious how it works? Try our | ||
| [HF space](https://huggingface.co/spaces/Roboflow/SoM)! | ||
| **maestro** is a tool designed to streamline and accelerate the fine-tuning process for | ||
| multimodal models. It provides ready-to-use recipes for fine-tuning popular | ||
| vision-language models (VLMs) such as **Florence-2**, **PaliGemma**, and | ||
| **Phi-3.5 Vision** on downstream vision-language tasks. | ||
|
|
||
| ## 💻 install | ||
|
|
||
| ⚠️ Our package has been renamed to `maestro`. Install the package in a | ||
| [**3.11>=Python>=3.8**](https://www.python.org/) environment. | ||
| Pip install the supervision package in a | ||
| [**Python>=3.8**](https://www.python.org/) environment. | ||
|
|
||
| ```bash | ||
| pip install maestro | ||
| ``` | ||
|
|
||
| ## 🔌 API | ||
|
|
||
| 🚧 The project is still under construction. The redesigned API is coming soon. | ||
|
|
||
| 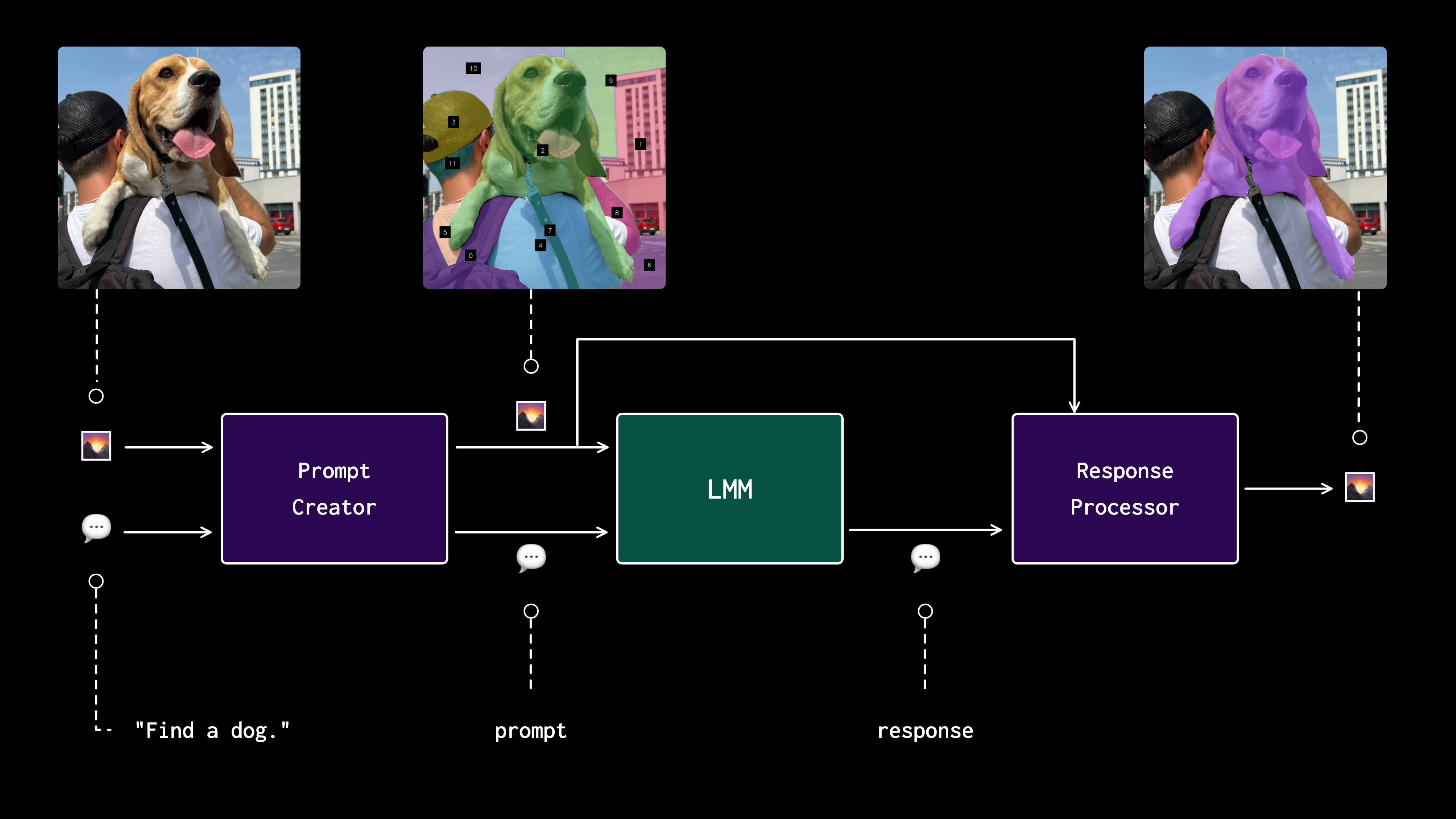 | ||
|
|
||
| ## 🧑🍳 prompting cookbooks | ||
|
|
||
| | Description | Colab | | ||
| |:----------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:| | ||
| | Prompt LMMs with Multimodal Maestro | [](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/multimodal_maestro_gpt_4_vision.ipynb) | | ||
| | Manually annotate ONE image and let GPT-4V annotate ALL of them | [](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/grounding_dino_and_gpt4_vision.ipynb) | | ||
|
|
||
|
|
||
| ## 🚀 example | ||
|
|
||
| ``` | ||
| Find dog. | ||
| >>> The dog is prominently featured in the center of the image with the label [9]. | ||
| ``` | ||
|
|
||
| <details close> | ||
| <summary>👉 read more</summary> | ||
|
|
||
| <br> | ||
|
|
||
| - **load image** | ||
|
|
||
| ```python | ||
| import cv2 | ||
|
|
||
| image = cv2.imread("...") | ||
| ``` | ||
|
|
||
| - **create and refine marks** | ||
|
|
||
| ```python | ||
| import maestro | ||
|
|
||
| generator = maestro.SegmentAnythingMarkGenerator(device='cuda') | ||
| marks = generator.generate(image=image) | ||
| marks = maestro.refine_marks(marks=marks) | ||
| ``` | ||
|
|
||
| - **visualize marks** | ||
|
|
||
| ```python | ||
| mark_visualizer = maestro.MarkVisualizer() | ||
| marked_image = mark_visualizer.visualize(image=image, marks=marks) | ||
| ``` | ||
|  | ||
|
|
||
| - **prompt** | ||
|
|
||
| ```python | ||
| prompt = "Find dog." | ||
|
|
||
| response = maestro.prompt_image(api_key=api_key, image=marked_image, prompt=prompt) | ||
| ``` | ||
|
|
||
| ``` | ||
| >>> "The dog is prominently featured in the center of the image with the label [9]." | ||
| ``` | ||
|
|
||
| - **extract related marks** | ||
|
|
||
| ```python | ||
| masks = maestro.extract_relevant_masks(text=response, detections=refined_marks) | ||
| ``` | ||
|
|
||
| ``` | ||
| >>> {'6': array([ | ||
| ... [False, False, False, ..., False, False, False], | ||
| ... [False, False, False, ..., False, False, False], | ||
| ... [False, False, False, ..., False, False, False], | ||
| ... ..., | ||
| ... [ True, True, True, ..., False, False, False], | ||
| ... [ True, True, True, ..., False, False, False], | ||
| ... [ True, True, True, ..., False, False, False]]) | ||
| ... } | ||
| ``` | ||
|
|
||
| </details> | ||
|
|
||
|  | ||
| Documentation and Florence-2 fine-tuning examples for object detection and VQA coming | ||
| soon. | ||
|
|
||
| ## 🚧 roadmap | ||
|
|
||
| - [ ] Rewriting the `maestro` API. | ||
| - [ ] Update [HF space](https://huggingface.co/spaces/Roboflow/SoM). | ||
| - [ ] Documentation page. | ||
| - [ ] Add GroundingDINO prompting strategy. | ||
| - [ ] CovVLM demo. | ||
| - [ ] Qwen-VL demo. | ||
|
|
||
| ## 💜 acknowledgement | ||
|
|
||
| - [Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding | ||
| in GPT-4V](https://arxiv.org/abs/2310.11441) by Jianwei Yang, Hao Zhang, Feng Li, Xueyan | ||
| Zou, Chunyuan Li, Jianfeng Gao. | ||
| - [The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)](https://arxiv.org/abs/2309.17421) | ||
| by Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, | ||
| Lijuan Wang | ||
|
|
||
| ## 🦸 contribution | ||
|
|
||
| We would love your help in making this repository even better! If you noticed any bug, | ||
| or if you have any suggestions for improvement, feel free to open an | ||
| [issue](https://github.com/roboflow/multimodal-maestro/issues) or submit a | ||
| [pull request](https://github.com/roboflow/multimodal-maestro/pulls). | ||
| - [ ] Release a CLI for predefined fine-tuning recipes. | ||
| - [ ] Multi-GPU fine-tuning support. | ||
| - [ ] Allow multi-dataset fine-tuning and support multiple tasks at the same time. |