Repositório de documentação dos estudos de JPA com Hibernante
Existem dois padrões de projeto:
Mapeamento de dados dos atributos em relação às colunas. É o padrão utilizado pelo JPA. As informações a serem inseridas no banco podem estar dentro de um xml, json ou annotation.
Encontrado no Laravel, Ruby on Rails. O próprio objeto possui seus métodos necessários para sua persistência no banco de dados. Acontece através de herança. Por exemplo: Cliente herda da classe ActiveRecord. A classe representa a tabela e a instância representa uma linha.
ORM é o conceito que trata do mapeamento objeto-relacional. Basicamente é utilizado para transformarmos um objeto para um registro em um banco de dados relacional.
O mapeamento consiste na técnica de relacionar cada atributo á uma coluna bem como cada classe a uma tabela.
Para isso, no Java com JPA utilizaremos o conceito de Annotations
// Exemplo:
@Table(nome_tabela no banco)
public class Produto// Para mapear a chave primária da tabela:
@Id
// Para mapear as colunas
@ColumnDeve ser baixado o arquivo das classes do hibernate no hibernate.org.
Adicionar na pasta libs do meu projeto (se não tiver, criar folder)
Adicionar na pasta libs do meu projeto o SQL Connector do java
Selecionar todas as libs e dar build path
Aqui estarão configuradas as conexões com o banco de dados.
Arquivo utilizado na aula:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="exercicios-jpa">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<mapping-file>META-INF/consultas.xml</mapping-file>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost/curso_java"/>
<property name="javax.persistence.jdbc.user"
value="root"/>
<property name="javax.persistence.jdbc.password"
value="12345678"/>
<property name="hibernate.dialect"
value="org.hibernate.dialect.MySQL57Dialect"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
</properties>
</persistence-unit>
</persistence>Classe provedora da API. Deve estar adicionada na Lib.
Unidade de persistencia que o java vai utilizar para o acesso ao banco.
Podemos ter várias unidades de persistência.
.dialect: as linguagens sql variam de um banco para outro, por isso é acionado esse property
.show_sql: mostrar o sql gerado pelo hibernate no console
.format_sql: para formatar o sql
.hbm2ddl.auto: gerar a ddl no banco conforme é feita alterações nas classes model. Valores possíveis: none, update;
Para mapear uma entidade para o JPA, devemos adicionar ao menos duas annotations:
- Entity - Responsável por dizer ao JPA que a classe representa uma entidade no banco de dados.
- Id - Responsável por dizer ao JPA que o atributo é a chave primária da entidade do banco.
@Entity
@Table(name = "tbusuario")
public class Usuario {
@Id
@Column(name = "usucode")
private Long id;
@Column(name = "usuname", nullable = false, unique = true)
private String username;
@Column(name = "usumail", nullable = false, unique = true)
private String email;
@Column(name = "usupswd", nullable = false, unique = false)
private String password;
public Usuario() {
}
public Usuario(String username, String email, String password) {
super();
this.username = username;
this.email = email;
this.password = password;
}Para interagirmos com o banco de dados, temos duas interfaces principais do JPA que são necessárias:
- EntityManagerFactory - Tem o papel de criar EntityManagers - basicamente cada entityManager vai criar uma conexão com o banco de dados encapsulada, portanto, se eu tiver que ter várias conexões com o banco de dados, vou ter que ter vários EntityManager. Detalhe: no meu arquivo persistence.xml posso ter mais de uma unit de persistência, podendo assim separar os entityManager por unit de persistência.
- EntityManager - Classe responsável por criar uma conexão com o banco de dados e também responsável pelo CRUD = vai receber um objeto e entender que a classe daquele objeto tem um mapeamento para o banco de dados.
public class NovoUsuario {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();No parâmetro de criação do EntityManagerFactory é passado o nome da unit de persistência contida no arquivo persistence.xml.
→ Pode também ser passado como parâmetro um Map com as properties de conexão com o banco.
public class NovoUsuario {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
Usuario novoUsuario = new Usuario("MatheusBus","[email protected]","1234567");
em.getTransaction().begin();
em.persist(novoUsuario);
em.getTransaction().commit();
em.close();
emf.close();
}Observe que no método find, deve ser passado a Classe mapeada a qual se deseja consultar no banco:
public class ObterUsuario {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
Usuario usuario = em.find(Usuario.class, 1L);
System.out.println(usuario.getUsername());
String jpql = "select u from Usuario u";
TypedQuery<Usuario> query = em.createQuery(jpql, Usuario.class);
query.setMaxResults(5);
em.close();
emf.close();
}
}O framework JPA trabalha com a linguagem JPQL que é uma linguagem parecida com SQL porém no mundo dos objetos. Para realizarmos uma consulta que retorne vários registros, é necessário utilizar esse tipo de linguagem, com auxílio do framework, é claro.
JPQL = Java Persistence Query Language
Segue exemplo de recuperação de dados:
public class ObterUsuarios {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
/*
// Exemplo fazendo em várias linhas
String jpql = "select u from Usuario u"; // -> JQPL
TypedQuery<Usuario> query = em.createQuery(jpql, Usuario.class);
query.setMaxResults(5);
List<Usuario> usuarios = query.getResultList();
*/
// Exemplo fazendo tudo em uma linha
List<Usuario> usuarios = em
.createQuery("select u from Usuario u", Usuario.class)
.setMaxResults(5)
.getResultList();
for(Usuario usuario : usuarios) {
System.out.println("Id: "+usuario.getId()+" - Username: "+usuario.getUsername());
}
em.close();
emf.close();
}Para gerar um update com o JPA temos que considerar a existência do Estado Gerenciável do Objeto
💡 Estado gerenciável de um objeto: qualquer mudança que ser feita em um objeto em um contexto transacional, será “sincronizado” pelo JPA no banco de dados.🏆 **O mais recomendado é termos objetos que não assumem estados gerenciáveis e são atualizados somente em contexto transacional com a chamada do método merge.**Se um objeto estiver configurado para estado gerenciável, não precisamos chamar nenhum método para atualizá-lo no banco de dados pois o JPA fará isso para gente. Caso seja necessário ter um objeto que não assume o estado gerenciável, é possível configurar.
Exemplo utilizando merge:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
Usuario usuario = em.find(Usuario.class, 1L);
System.out.println(usuario);
usuario.setUsername("Matheus Alterado");
em.getTransaction().begin();
em.merge(usuario);
em.getTransaction().commit();
em.close();
emf.close();Exemplo considerando o contexto transacional e o estado gerenciável do objeto (não é preciso chamar o método MERGE:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
Usuario usuario = em.find(Usuario.class, 1L);
System.out.println(usuario);
usuario.setUsername("Matheus Arruda");
em.getTransaction().begin();
//em.merge(usuario); Altera mesmo sem chamar o método merge
em.getTransaction().commit();
em.close();
emf.close();detach: Método responsável por tornar um objeto não gerenciável.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
Usuario usuario = em.find(Usuario.class, 1L);
usuario.setUsername("João gomes");
em.detach(usuario); // Não irá mais atualizar automaticamente no banco de dados.
em.getTransaction().commit();Porém, posso chamar o detach e o merge logo após: para casos onde não quero a sincronia imediata, onde o JPA vai esperar um momento oportuno para atualizar os valores no banco de dados.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
Usuario usuario = em.find(Usuario.class, 1L);
usuario.setUsername("João gomes");
em.detach(usuario);
em.merge(usuario);
em.getTransaction().commit();- remove: método utilizado para remover um registro do banco de dados.
DEVE ESTAR EM CONTEXTO TRANSACIONAL
EntityManagerFactory emf = Persistence.createEntityManagerFactory("exercicios-jpa");
EntityManager em = emf.createEntityManager();
Usuario usuario = em.find(Usuario.class, 1L);
if(usuario != null) {
em.getTransaction().begin();
em.remove(usuario);
em.getTransaction().commit();
}
em.close();
emf.close();package infra;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import javax.persistence.TypedQuery;
public class dao<E> {
private static EntityManagerFactory emf;
private EntityManager em;
private Class<E> classe;
static {
try {
emf = Persistence.createEntityManagerFactory("exercicios-jpa");
} catch (Exception e) {
e.printStackTrace();
}
}
public dao() {
}
public dao(Class<E> classe) {
this.classe = classe;
em = emf.createEntityManager();
}
public dao<E> abrirTransacao(){
em.getTransaction().begin();
return this;
}
public dao<E> commitTransacao(){
em.getTransaction().commit();
return this;
}
public dao<E> incluir(E entidade){
em.persist(entidade);
return this;
}
public dao<E> incluirDireto(E entidade){
return this.abrirTransacao().incluir(entidade).commitTransacao();
}
public List<E> obterTodos(){
return this.obterTodos(10,0);
}
public List<E> obterTodos(int quantidade, int deslocamento){
if(classe == null) {
throw new UnsupportedOperationException("Classe nula");
}
String jpql = "select e from "+classe.getName() + " e";
TypedQuery<E> query = em.createQuery(jpql, classe);
query.setMaxResults(quantidade);
query.setFirstResult(deslocamento);
return query.getResultList();
}
public void fechar() {
em.close();
}
}ProdutoDAO:
package infra;
import modelo.basico.Produto;
public class ProdutoDAO extends DAO<Produto>{
public ProdutoDAO() {
super(Produto.class);
}
}Obtendo todos os produtos com o DAO:
package teste.basico;
import java.util.List;
import infra.ProdutoDAO;
import modelo.basico.Produto;
public class ObterProdutos {
public static void main(String[] args) {
ProdutoDAO dao = new ProdutoDAO();
List<Produto> produtos = dao.obterTodos();
for(Produto produto : produtos) {
System.out.println(produto.toString());
}
double valorTotalEmEstoque = produtos
.stream()
.map(p -> p.getPreco())
.reduce(0.0, (t, p) -> t + p)
.doubleValue();
System.out.println("O valor do estoque total é R$" +valorTotalEmEstoque);
dao.fechar();
}
}Assim como tenho os relacionamentos em um banco de dados (Entidade/Relacionamento), temos os relacionamento no mundo da Orientação à Objetos.
→ Na orientação à objetos o relacionamento ocorre por meio de atributos da minha classe referenciando outras classes.
@OneToOne
Object atritubo;
@OneToMany - @ManyToOne
List<Object> atributo2;
@ManyToMany
List<Object> atributo3;Para mim representar o relacionamento um para um, considerei duas classe:
- Cliente
- Assento
No contexto de que um cliente possui um assento e esse assento deve ser único (apontar apenas para um cliente).
Classe cliente:
@Entity
@Table(name = "tb_cliente")
public class Cliente {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome")
private String nome;
@OneToOne
@JoinColumn(name = "assento_id", unique = true) // Não posso usar o @Column
private Assento assento;
public Cliente() {
}
public Cliente(String nome, Assento assento) {
super();
this.nome = nome;
this.assento = assento;
}
// métodos getters and setters...
}Reparar que, para a coluna que referencia o assento eu tenho um objeto assento. E para o mesmo, é adicionado as annotations:
- OneToOne: responsável por dizer ao JPA que aquele atributo faz referência à um relacionamento um para um.
- JoinColumn: para ser possível adicionar a propriedade unique no atributo de assento.
Já a classe Assento, sem muitos segredos:
@Entity
@Table(name = "tb_assento")
public class Assento {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome")
private String nome;
public Assento() {
}
public Assento(String nome) {
super();
this.nome = nome;
}Manipulando os objetos e inserindo:
Reparar que eu posso inserir mais de um objeto em uma única transação. E estes devem seguir uma ordem lógica de inclusão. No caso, o assento deve ser inserido antes da inserção do cliente, pois o assento deve existir para que seja referenciado.
Manipulando os objetos e inserindo:
> Reparar que eu posso inserir mais de um objeto em uma única transação. E estes devem seguir uma ordem lógica de inclusão. No caso, o assento deve ser inserido antes da inserção do cliente, pois o assento deve existir para que seja referenciado.
>Importante ressaltar que EM CONTEXTO TRANSACIONAL não é estritamente necessário a inserção em ordem lógica como segue o banco de dados, o JPA ao perceber que há uma relação entre as entidades fará a manipulação e inserção correta. Porém, isso se dá apenas em contexto transacional.
Podemos declarar um atributo de uma classe, que referencia outra classe como um atributo que será manipulado no banco de dados toda vez que a classe ao qual ele está inserido for manipulada.
Por exemplo:
→ Eu quero inserir um objeto Cliente com um objeto Assento que não existe no banco de dados, então posso realizar com JPA a operação em CASCATA.
- OneToOne( cascade = {CasdcadeType.PERSIST, CascadeType.MERGE}) → Para persistir e atualizar em cascata;
- OneToOne( cascade = CascadeType.ALL ) → Para realizar todas as operações em cascata.
@Entity
@Table(name = "tb_cliente")
public class Cliente {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome")
private String nome;
@OneToOne(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
@JoinColumn(name = "assento_id", unique = true)
private Assento assento;
public Cliente() {
}Quanto tivermos duas classas Java que possuem relacionamento no qual cada uma das classes possui um atributo do tipo da outra classe, temos um relacionamento bidirecional no java, porém no banco de dados isso não irá ocorrer, portanto, em um dos atributos tenho que informar a cláusula:
- @OneToOne(MappedBy = ‘nomeAtributoMapeado’)
Informando que o relacionamento bidirecional já foi mapeado em outro atributo.
Exemplo:
Na classe Cliente, temos o atributo assento normalmente: ´´´java @Entity @Table(name = "tb_cliente") public class Cliente {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome")
private String nome;
@OneToOne(cascade = {CascadeType.PERSIST, CascadeType.MERGE})
@JoinColumn(name = "assento_id", unique = true)
private Assento assento;
public Cliente() {
}
´´´ Já na classe assento, teremos o atributo Cliente da seguinte forma: ´´´java @Entity @Table(name = "tb_assento") public class Assento {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome")
private String nome;
@OneToOne(mappedBy = "assento") // O nome deve ser o nome exato do atributo mapeado na classe Cliente.
private Cliente cliente;
´´´
Atenção: se não declarar o mappedBy, o JPA irá criar uma nova coluna na tabela da classe em questão.
@ManyToOne
´´´java
@Entity
@Table(name = "tbitempedido")
public class ItemPedido {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
private Pedido pedido;
@ManyToOne
private Produto produto;
@Column(nullable = false)
private int quantidade;
@Column(nullable = false)
private Double preco;
public ItemPedido() {
}
´´´ No exemplo, utilizo a classe ItemPedido, que poderá ter várias instâncias para um pedido.
Neste caso, a annotation quer dizer que há muitos (itempedido) para um (pedido).
´´´
´´´java
@Entity
@Table(name = "tbpedido")
public class Pedido {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "data_pedido", nullable = false)
private Date data;
public Pedido() {
this(new Date());
}
´´´
Note que até o momento tenho apenas o relacionamento de um lado. Mas, e se eu quiser saber todos os itempedido de um pedido? Então tenho que adicionar a annotation @OneToMany na classe Pedido.
Agora, adicionando a bidirecionalidade, o atributo na classe Pedido:
Adiciono a Annotation
- @OneToMany → Observar que One (Pedido) para Many (itensPedido)
Adiciono também (mappedBy = “pedido”), pois o atributo já foi mapeado na classe ItemPedido.
´´´java
@Entity
@Table(name = "tbpedido")
public class Pedido {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "data_pedido", nullable = false)
private Date data;
@OneToMany(mappedBy = "pedido")
private List<ItemPedido> itens;
public Pedido() {
this(new Date());
}
public Pedido(Date data) {
super();
this.data = data;
}
´´´
Obtendo todos os itens de um pedido:
Quando chamamos o getItens o JPA executa uma segunda consulta na tabela de itens para retornar todos os itens pertencentes ao produto.
´´´java
public static void main(String[] args) {
DAO<Pedido> dao = new DAO<>(Pedido.class);
Pedido pedido = dao.obterPorId(1L);
for(ItemPedido item : pedido.getItens()) {
System.out.println(item.toString());
}
dao.fechar();
}
´´´
Quanto há relacionamentos e anoto os atributos com OneToMany ou ManyToOne, há uma propriedade chamada Fetch. Ela serve para dizer ao JPA o tipo de consulta que irá ser feita levando em consideração o relacionamento. Há duas marcações:
fetch = FetchType.EAGER
fetch = FetchType.LAZY
O EAGER é um marcador para dizer ao JPA que ao trazer o registro do objeto em questão, todos os registros do atributo ao qual o relacionamento está anotado com o fecth serão trazidos na mesma consulta (Eager = ansioso), de modo apressado, ao mesmo tempo.
Já o LAZY é um marcador para dizer ao JPA que os registros do relacionamento não serão trazidos na mesma consulta ao objeto em questão (Lazy = preguiçoco).
→ Padrões: quando não informado o JPA assume alguns padrões, são eles:
Para relacionamentos que apontam para muitos (…ToMany) o padrão será o Lazy e o JPA não trará todos os registros do relacionamento na mesma consulta.
Para relacionamento que apontam para um (…ToOne) o padrão será o Eager e o JPA trará todos os registros do relacionamento na mesma consulta.
Esse controle é muito importante quando temos relacionamentos em cadeia, por exemplo uma tabela que faz relacionamento para muitos em outra tabela, e essa por sua vez faz relacionamento para muitos em outra tabela.
🏆 Recomendado: deixar no padrão e quando necessário criar uma consulta específica utilizando JPQL.Portanto, um exemplo utilizando o LAZY: (Observar que o JPA faz duas consultas ao banco de dados)
´´´
Hibernate:
select
pedido0_.id as id1_3_0_,
pedido0_.data_pedido as data_ped2_3_0_
from
tbpedido pedido0_
where
pedido0_.id=?
Hibernate:
select
itens0_.pedido_id as pedido_i4_2_0_,
itens0_.id as id1_2_0_,
itens0_.id as id1_2_1_,
itens0_.pedido_id as pedido_i4_2_1_,
itens0_.preco as preco2_2_1_,
itens0_.produto_id as produto_5_2_1_,
itens0_.quantidade as quantida3_2_1_,
produto1_.id as id1_4_2_,
produto1_.pddescri as pddescri2_4_2_,
produto1_.pdpreco as pdpreco3_4_2_,
produto1_.pdunidmed as pdunidme4_4_2_
from
tbitempedido itens0_
left outer join
tbproduto produto1_
on itens0_.produto_id=produto1_.id
where
itens0_.pedido_id=?
´´´
Já se utilizarmos o EAGER: (Observar que o JPA faz apenas uma consulta ao banco de dados)
´´´
Hibernate:
select
pedido0_.id as id1_3_0_,
pedido0_.data_pedido as data_ped2_3_0_,
itens1_.pedido_id as pedido_i4_2_1_,
itens1_.id as id1_2_1_,
itens1_.id as id1_2_2_,
itens1_.pedido_id as pedido_i4_2_2_,
itens1_.preco as preco2_2_2_,
itens1_.produto_id as produto_5_2_2_,
itens1_.quantidade as quantida3_2_2_,
produto2_.id as id1_4_3_,
produto2_.pddescri as pddescri2_4_3_,
produto2_.pdpreco as pdpreco3_4_3_,
produto2_.pdunidmed as pdunidme4_4_3_
from
tbpedido pedido0_
left outer join
tbitempedido itens1_
on pedido0_.id=itens1_.pedido_id
left outer join
tbproduto produto2_
on itens1_.produto_id=produto2_.id
where
pedido0_.id=?
´´´
Dica: se na minha aplicação eu tiver um caso em que na maior parte das vezes em que eu acesso um registro pai, eu preciso acessar os registros filhos, então faz mais sentido trazer tudo em uma query só → Utilizando assim o EAGER.
Para os relacionamentos muitos para muitos utilizamos a annotation:
- @ManyToMany
A única questão que deve ser levantada aqui é que dependendo da classe em que a relação for mapeada, que se dará o nome da tabela (em casos em que o JPA possui permissão para alterar o banco de dados).
No exemplo abaixo, foi feito uma estrutura de Tios e Sobrinhos. Um sobrinho possui vários tios e um Tio possui vários sobrinhos.
O atributo mapeado foi na classe de Tio:
@Entity
public class Tio {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome", nullable = false)
private String nome;
@ManyToMany
private List<Sobrinho> sobrinhos = new ArrayList<>();
public Tio() {
}
public Tio(String nome) {
super();
this.nome = nome;
}Já na classe Sobrinho, marco com o MappedBy:
@Entity
public class Sobrinho {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "nome", nullable = false)
private String nome;
@ManyToMany(mappedBy = "sobrinhos") // Isso quer dizer que na classe de Tio é que está mapeada a relação.
private List<Tio> tios = new ArrayList<>();
public Sobrinho() {
}
public Sobrinho(String nome) {
super();
this.nome = nome;
}Portanto, ao criar a tabela no banco de dados, o JPA assumirá o nome de “tio_sobrinho” (claro que dá para alterar e personalizar o nome a ser criado).
Inserindo as relações no banco de dados:
public class NovoTioSobrinho {
public static void main(String[] args) {
Tio tio = new Tio("Vitor");
Tio tia = new Tio("Joana");
Sobrinho sobrinho = new Sobrinho("Matheus");
Sobrinho sobrinha = new Sobrinho("Franciele");
// Relacionando todos com todos.
tio.getSobrinhos().add(sobrinho);
tio.getSobrinhos().add(sobrinha);
tia.getSobrinhos().add(sobrinho);
tia.getSobrinhos().add(sobrinha);
sobrinho.getTios().add(tio);
sobrinho.getTios().add(tia);
sobrinha.getTios().add(tio);
sobrinha.getTios().add(tia);
DAO<Object> dao = new DAO<>();
dao.abrirTransacao()
.incluir(tio)
.incluir(tia)
.incluir(sobrinho)
.incluir(sobrinha)
.commitTransacao()
.fechar();
}
}E no fim, fica assim o banco de dados, com a tabela de relacionamento de muitos para muitos:

Neste caso, utilizo a propriedade @JoinTable:
@Entity
@Table(name = "tbfilme")
public class Filme {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "fil_nome", nullable = false)
private String nome;
@ManyToMany
@JoinTable(
name = "tbatores_filmes",
joinColumns = @JoinColumn(name = "filme_id", referencedColumnName = "id"),
inverseJoinColumns = @JoinColumn(name = "ator_id", referencedColumnName = "id")
)
private List<Ator> atores;
@Column(name = "fil_nota")
private double nota;
public Filme() {
super();
}Onde:
- name: nome da minha tabela que fará o relacionamento.
- joinColumns: colunas que farão fk para a minha classe atual (que contém o atributo)
- inverseJoinColumns: colunas que farão fk para a outra classe mapeada (que contém o mappedBy)
- @JoinColumn: para declarar o campo
- name: nome do campo na tabela a ser criada
- referencedColumnName: nome do campo na tabela que fará fk (no caso, filme e ator)
public class NovoFilmeAtor {
public static void main(String[] args) {
Filme filmeA = new Filme("As cronicas de Nárnia", 9.9);
Filme filmeB = new Filme("007", 7.5);
Ator atorA = new Ator("Vin Diesel");
Ator atorB = new Ator("Angelina Julie");
filmeA.adicionarAtor(atorA);
filmeA.adicionarAtor(atorB);
filmeB.adicionarAtor(atorB);
DAO<Filme> dao = new DAO<>();
dao.incluirDireto(filmeA);
// Aqui o JPA vai persistir todos os objetos no banco de dados, devido ao Cascade
// na classe Filme e na classe Ator.
}
}Consultas nomeadas.
Em JPA posso ter consultas prontas utilizando Annotation como @NamedQuery.
Exemplo na classe:
@Entity
@NamedQuery(name = "ObterFilmesComNotaMenorQue", query = "select f from Filme f where f.nota < :nota")
@Table(name = "tbfilme")
public class Filme {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "fil_nome", nullable = false)
private String nome;
@ManyToMany(cascade = CascadeType.PERSIST) // No momento de inserção de um filme, irá inserir também os atores.
@JoinTable(
name = "tbatores_filmes",
joinColumns = @JoinColumn(name = "filme_id", referencedColumnName = "id"),
inverseJoinColumns = @JoinColumn(name = "ator_id", referencedColumnName = "id")
)
private List<Ator> atores;
@Column(name = "fil_nota")
private double nota;
public Filme() {
super();
}É possível ter também, um arquivo xml com várias namedQueries:
💡 Criar no META-INF um arquivo do tipo JPA ORM Mapping File<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings version="2.2" xmlns="http://xmlns.jcp.org/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence/orm http://xmlns.jcp.org/xml/ns/persistence/orm_2_2.xsd">
<named-query name="obterFilmesComNotaMaiorQue">
<query>
select distinct f
from Filme f
join fetch f.atores
where f.nota > :nota
</query>
</named-query>
<named-query name="obterFilmesComNotaIgual">
<query>
select distinct f
from Filme f
join fetch f.atores
where f.nota = :nota
</query>
</named-query>
</entity-mappings>Para utilizar a consulta, criei um método na classe DAO:
public List<E> consultar(String nomeDaConsulta, Object... params){
TypedQuery<E> query = em.createNamedQuery(nomeDaConsulta, classe);
for(int i = 0; i < params.length; i += 2) {
query.setParameter(params[i].toString(), params[i + 1]);
}
return query.getResultList();
}Utilizando um array de Object recebendo um tipo de “chave e valor”, onde a chave vai ser a coluna do filtro e o valor será o valor a ser filtrado.
Utilizando o método:
public class ObterFilmes {
public static void main(String[] args) {
DAO<Filme> dao = new DAO<>(Filme.class);
// List<Filme> filmes = dao.consultar("obterFilmesComNotaMaiorQue", "nota", 8.5);
//List<Filme> filmes = dao.consultar("obterFilmesComNotaIgual", "nota", 7.5);
List<Filme> filmes = dao.consultar("ObterFilmesComNotaMenorQue", "nota", 10D);
for(Filme filme : filmes) {
System.out.println(filme.getNome());
for(Ator ator : filme.getAtores()) {
System.out.println(ator.getNome());
}
}
}
}Geralmente, em nossos programas é necessários que façamos consultas nativas e específicas e que provavelmente teremos de colocar em uma classe que não seja uma entidade, por exemplo um relatório.
As consultas nativas podem ser escritas em SQL e não JPQL.
Primeiro, deve ser criada uma classe modelo que irá receber o retorno da consulta:
package modelo.consulta;
// Exemplo da aula de named native query - jpa
public class NotaFilme {
private double media;
public NotaFilme(double media) {
super();
this.media = media;
}
public double getMedia() {
return media;
}
public void setMedia(double media) {
this.media = media;
}
}Em seguida, adiciono os seguintes atributos no arquivo consultas.xml:
<named-native-query name="obterMediaGeralDosFilmes"
result-set-mapping="NotaFilmeMap">
<query>
select avg(fil_nota) as media from tbfilme
</query>
</named-native-query>
<sql-result-set-mapping name="NotaFilmeMap">
<constructor-result target-class="modelo.consulta.NotaFilme">
<column name="media" class="java.lang.Double"/>
</constructor-result>
</sql-result-set-mapping>Criando um novo método no DAO para Consultar apenas um:
public E consultarUm(String nomeDaConsulta, Object... params) {
List<E> lista = consultar(nomeDaConsulta, params);
return lista.isEmpty() ? null : lista.get(0);
}Consultando e imprimindo a média:
public class ObterMediaFilmes {
public static void main(String[] args) {
DAO<NotaFilme> dao = new DAO<>(NotaFilme.class);
NotaFilme nota = dao.consultarUm("obterMediaGeralDosFilmes");
System.out.println("Média dos filmes utilizando named-native-query: " + nota.getMedia());
dao.fechar();
}
}O @Embeddable é utilizado para anotar classes que fazem parte de uma composição no java, na qual essas não são entidades do banco de dados, mas terão atributos que serão persistidos na tabela da entidade que possui como atributo a classe marcada com o Embeddable.
Abaixo um exemplo, onde temos a classe Fornecedor, Funcionario e Endereco:
💡 **Endereco** é uma classe que possui logradouro e complemento, esta classe não será uma entidade do banco de dados, mas seus atributos serão persistidos. 💡 **Fornecedor** é uma classe que possui um atributo do tipo **endereco** e é mapeada para o banco de dados. 💡 **Funcionario** é uma classe que possui um atributo do tipo **endereco** e é mapeada para o banco de dados.Clase Endereco:
@Embeddable
public class Endereco {
private String logradouro;
private String complemento;
public Endereco() {
super();
}Classe Funcionario:
@Entity
@Table(name = "tb_funcionario")
public class Funcionario {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nome;
private Endereco endereco;
public Funcionario() {
super();
// TODO Auto-generated constructor stub
}Classe Fornecedor:
@Entity
@Table(name = "tb_fornecedor")
public class Fornecedor {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String nome;
private Endereco endereco;
public Fornecedor() {
super();
}Inserindo no banco de dados:
public class NovoFuncFornEndereco {
public static void main(String[] args) {
DAO<Object> dao = new DAO<>();
Endereco end1 = new Endereco("Rua", "Em frente ao supermercado");
Endereco end2 = new Endereco("Morro", "morro da cruz");
Funcionario func = new Funcionario("Matheus", end1);
Fornecedor forn = new Fornecedor("Santa Cruz Bebidas", end2);
dao.abrirTransacao()
.incluir(func)
.incluir(forn)
.commitTransacao()
.fechar();
}
}Ao inserir, o banco ficará da seguinte forma:

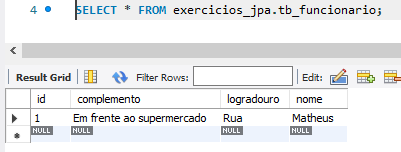
Percebe-se que não foi criada uma entidade para endereço, e sim, foi adicionado em colunas (os atributos da classe Endereço) nas entidades fornecedor e funcionario.
Deve ser adicionado em nossas classes a annotation:
- @Inheritance: para representar uma herança.
Para utilizar herança com JPA, há três diferentes estratégias que podem ser adotadas e devem ser passadas como stragety da annotation inheritance:
-
strategy = ingheritanceType.JOINED: Irá ser mapeado para o banco de dados uma tabela para cada herança, através de PFK, por exemplo:
- No exemplo de Aluno e Aluno Bolsista, terei uma tabela para Aluno e uma tabela para AlunoBolsista, que irá carregar a PK de Aluno como PFK e terá apenas o atributo da classe AlunoBolsista em sua entidade.
-
strategy = inheritanceType.SINGLE_TABLE: Irá ser mapeado para o banco de dados uma única tabela contendo os atributos de todas as classes da herança, utilizando do mesmo exemplo:
- Criará uma tabela única para Aluno, que conterá os atributos da classe Aluno e os atributos da classe AlunoBolsista.
-
strategy = inheritanceType.TABLE_PER_CLASS: Irá ser mapeado para o banco de dados uma tabela para cada classe da herança:
- Criará uma tabela para Aluno contendo os atributos de Aluno e criará uma tabela para AlunoBolsista contendo os atributos de Aluno e AlunoBolsista. Uma estratégia que talvez não seja tão interessante adotar, já que fere uma
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
public class Aluno {
@Id
private Long matricula;
private String nome;
public Aluno() {
super();
// TODO Auto-generated constructor stub
}
@Entity
public class AlunoBolsista extends Aluno {
// O Id vai ser detectado pelo JPA através da herança
private double valorBolsa;
public AlunoBolsista() {
}Tabelas geradas:


Quando utilizo o SINGLE_TABLE preciso especificar um discriminador para diferenciar a qual classe ou tipo pertence cada instância na minha tabela do banco de dados:
Para isso, utiliza-se:
- @DiscriminatorColumn: Para mapear a coluna que vai diferenciar a que tipo de instância pertence determinado registro.
- @DiscriminatorValue: mapeado em cada classe da herança para dizer o valor que será inserido na tabela quando um objeto do tipo da classe for inserido no banco
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "tipo", length = 2, discriminatorType = DiscriminatorType.STRING)
@DiscriminatorValue("AL")
public class Aluno {
@Id
private Long matricula;
private String nome;
public Aluno() {
super();
// TODO Auto-generated constructor stub
}
public Aluno(Long matricula, String nome) {
super();
this.matricula = matricula;
this.nome = nome;
}
------------------------------------------------------------
@Entity
@DiscriminatorValue("AB")
public class AlunoBolsista extends Aluno {
// O Id vai ser detectado pelo JPA através da herança
private double valorBolsa;
public AlunoBolsista() {
}
public AlunoBolsista(Long matricula, String nome, double valorBolsa) {
super(matricula, nome);
this.valorBolsa = valorBolsa;
}Ao inserir no banco de dados:

Utilizado para criar cada entidade com todos os campos da herança (duplica campos no banco de dados).