Home
实现一个简单的文件系统对于加深理解 Linux 具有很大的帮助。使用 fuse 能够让我们避免直接面向 VFS 层编写代码,前者能够让开发者尽早地获取反馈,让 bug 能够更早地暴露出来。在实现文件系统的过程中,持久化数据能够让系统 crash 掉之后复现现场,为此,笔者选取了 RocksDB 来存储这个文件系统的数据。
作为一个 key-value 数据库, RocksDB 提供的模型为扁平结构。于是,将树形结构映射到 key-value 模型即为文件系统数据结构的组织方式。为了更好地实现文件系统的各种操作,一个比较合适的设计为:索引 -> inode, inode -> 文件属性, inode -> 文件数据,将这三者分别存储在不同的 ColumnFamily 中, 此时硬链接也可以简单地使用同一个 inode。
索引的组织方法又是一个值得思考的问题。举例来说,在文件系统中如果存储了一个目录和两个普通文件,并且假设二者的 inode 分别为 2 、3 和 4:
/
└── dir
└──file1
└──file2
本工程早期将每个文件的完整文件名直接映射到 inode,此时,三个 ColumnFamily 数据库中以这种方式存储:
| Index | Attribute | Data | |||
|---|---|---|---|---|---|
| filename -> inode | inode -> attr | inode -> data | |||
| /dir | 2 | 2 | "dir attr" | ||
| /dir/file1 | 3 | 3 | "file3 attr" | 3 | "file3 data" |
| /dir/file22 | 4 | 4 | "file4 attr" | 4 | "file4 data" |
这种情况下,每个文件从路径到索引的时间复杂度都为 O(1) ,但是执行 rename 的时间复杂度却变成了O(n) ——当存储大量文件时,rename 一个顶层目录的执行时间将很可能变得不可接受。 下面我们换一种方法:
| Index | Attribute | Data | |||
|---|---|---|---|---|---|
| index -> inode | inode -> attr | inode -> data | |||
| 1:dir | 2 | 2 | "dir attr" | ||
| 2:file1 | 3 | 3 | "file3 attr" | 3 | "file3 data" |
| 2:file2 | 4 | 4 | "file4 attr" | 4 | "file4 data" |
将文件的组织打散,每个目录的索引由它们的父目录的 inode + 文件名组成,此时索引文件的复杂度变成了O(n), 但是所有基于 inode 的时间复杂度操作都可以变成 O(1),配合 fuse 可以缓存已打开的文件的 inode,rename 的瓶颈将不复存在。注意,作为 (u)int64 表示一个数字, inode 的编码方式应当以大端模式,存储在 RocksDB 中保证数据的有序存储。
此处 inode 没有从零开始的原因是:使用底层 api 时, fuse 使用 inode = 0 表示 inode 失效条目, inode = 1 表示根目录。
事实上,这种依赖 inode 的树形文件系统,它更适合使用 low-level api。未来,本工程可能会使用 fuse 的 low-api 重写。
由于 RocksDB 的 Value 是只读的,此时,将每个文件的所有数据写入单个 value 也是不合理的——这将产生两个问题:
- 修改一部分数据必须重写整个文件
- 读取文件时将增加磁盘 io 负担。
于是,将 data 分解为固定大小的数据块将有效缓解这个问题,此时, Data 中的索引长度变为 16 个字节——前八个字节的 inode 以及后八个字节的数据块序号,二者都以大端保存以保证数据的有序组织。此时文件空洞将自然被支持——文件系统只需要维护实际写入的数据,而对于未存储的数据可以直接填充零并返回。
无论是最底层 CPU 基于硬件的流水线提交,还是 C++ 程序编写过程中的异常安全,再到分布式事务的最终一致性,都离不开事务模型来保证正确性: 某一系列任务的执行,如果提交成功,那么对外暴露的状态更新必须是原子的;如果提交失败,执行者应当回滚操作保证状态不变。
如果前者无法保证,可能出现竞态条件漏洞,这篇文章 展示了利用竞态条件实现三星 S8 的 root 提权方法; 缺少后者很容易产生错误数据数据,下面这段 Python 代码的运行效果展示了没有回退操作的问题。
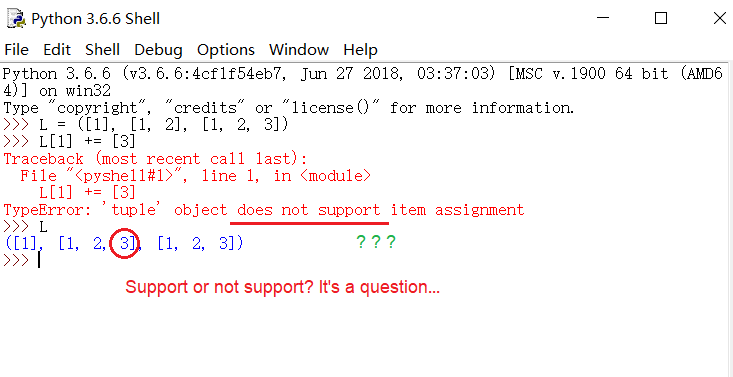
同样,文件系统的大部分操作(除了某些读取行为)都是事务性的,RocksDB 中的 TransationDB 为使用者提供了一系列事务性操作,方便使用者完成事务性的任务提交。
并发事务模型的最终实现必然要经过锁,于是死锁就是一个不可忽略的问题。虽然 RocksDB 为用户提供了死锁检测的选项,由于在文件系统的操作中,所有申请锁定的资源(即要锁定的 key) 都是可以预期的,此时 key 的锁定可以手动排序来避免这个问题。最为典型的例子就是 rename 操作:实现时有必要同时锁定"原父目录"、"目标父目录"、"原文件索引"、"目标文件索引"这四个跨 ColumnFamily 的键。
普通文件的删除动作在 fuse 中对应着 unlink 。和 Windows 锁定文件不同, Linux 允许在其他进程尚未关闭文件时删除文件。因此,文件系统需要维护文件打开的引用计数,并且在最后一个进程关闭文件时删除这个引用计数为零的文件。考虑到文件系统的进程也是可能在执行过程中 crash 掉的,为了防止 inode 泄露,可以使用以下方式保证删除动作的有效性:
-
unlink删除文件的索引并减少文件的引用计数, 如果这个文件没有被打开并且引用计数为零,那么就真正删除这个文件 - 如果文件使用者的计数不为零, 持久化记录这个待执行的删除行为
- 如果最后一个文件的使用者检测 inode 的引用计数, 如果为零则删除文件并清理上一条中的删除动作
- 文件系统重启时检测步骤 2 中记录但未能完成删除动作的文件,由于此时持有未关闭文件进程的 handle 必然失效,此时文件系统可以放心清理这些文件。
面向文件系统的测试工具中,大部分的测试工具面向文件系统的性能和稳定性,面向文件系统的正确性测试少之又少,能够独立针对每个 fuse api 实现的正确性的可配置测试工具则几乎没有。一个退而求其次的方法是使用 LTP (Linux Test Project) 中 fs 下的测试脚本进行修改,删除其中依赖其它 api 的部分测试 case (如依赖管道文件和 tcp 文件的测试项目)。
- 在默认的配置下,若删除或重命名某个未关闭的文件,fuse 将会把这个文件重命名成一个隐藏文件(*.fuse_hiddenXXX),此时如果创建一个与被删除文件的同名文件将导致死锁,解决方案是:在 init 函数中设置
fuse_config.hard_remove项 - fuse 会使用 fork 来完整到守护进程的切换,为了避免 fork 造成 RocksDB 无法使用,可以使用
fuse_opt_add_arg(&args, "-f")让 fuse 在前台运行,并且在 RocksDB 加载之前完成到守护进程的切换 - 如果使用上层 api 实现文件系统,为了保证底层 api 中的
setattr正确工作,必须实现四个函数:chmod,chown,truncate,utime,否则fuse会返回ENOSYS错误。 - fuse 默认不授予其他用户文件系统的使用权限(包括 root 用户),在 /etc/fuse.conf (3.2.6中为 /usr/local/etc/fuse.conf) 中取消
allow_other的注释可以允许其他用户访问我们的文件系统