- 支持去除提取视频后的水印文本信息
- 采用CNOCR,无需设置调用任何API,不需要接入百度、阿里等OCR服务即可本地完成文本识别
- 无需用户手动设置字幕区域,该项目引入CTPN自动检测字幕区域
- 下载项目文件,将工作目录切换到项目文件所在目录
cd video-subtitle-extractor- 在右侧release中下载模型文件ctpn_50000.ckpt.data-00000-of-00001,将其放置checkpoints_mlt文件夹中
https://www.anaconda.com/products/individual#Downloads
conda create --name videoEnv python=3.6
conda activate videoEnv - Mac用户:
pip install -r requirements(mac).txt- Windows用户:
pip install -r requirements(win).txtcd utils/bbox
chmod +x make.sh
./make.sh如果你仅仅编译CPU版本的tensorflow (i.e. mac用户),你需要进入到utils\bbox文件夹,然后终端运行:
python setup.py build_ext --inplace
mac/linux 用户运行demo.py
python ./main/demo.pywindows 用户运行demo_windows.py (由zamlean提供)
python ./main/demo_windows.pypython ./main/accuracyCal.py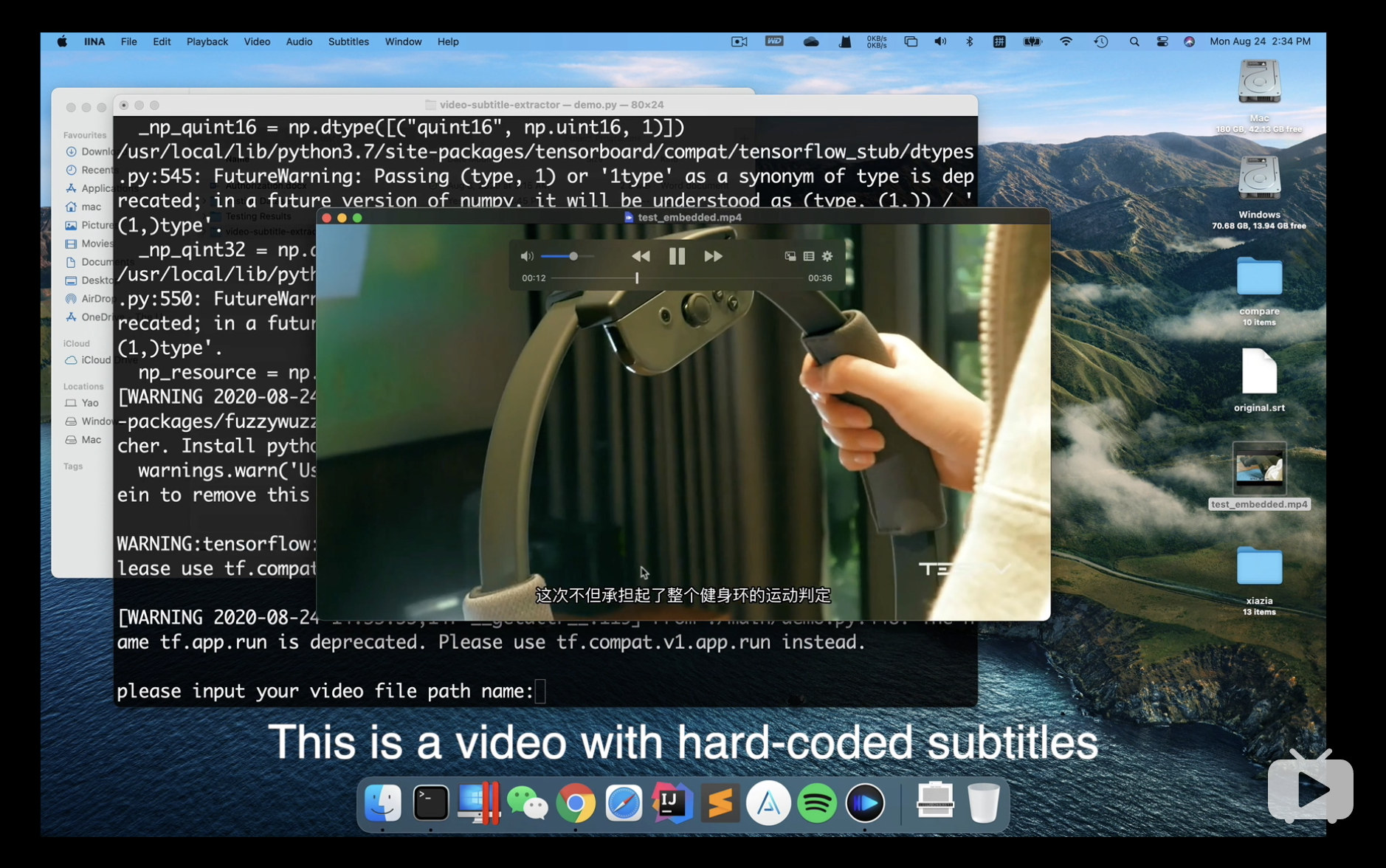
- 【window下】Value Error: Buffer dtype mismatch, expected 'int_t' but got 'long long'
- 解决方法:将
utils\bbox\中的nms.pyx替换为debug文件夹中的nms.pyx, 然后重新编译bbox文件
- 为什么不把Bbox, nms直接写成py,而是写成c,还要编译?
- 因为python是解释性质语言,像非极大值抑制算法的在字幕提取的过程中需要经常调用,因此写成c编译成机器码执行效率更高
- tricks
- 建议更具实际情况使用sys.intern()方法,interning之后的两个字符串可以直接用is比较是否相等,多次比较多个字幕行是否相等时可以进一步提升效率
- 可以采取试探法,一个大视频先测一小段,然后获取到一个大概的字幕区域,然后剩下的视频帧都只检测这个大概的区域,这样相比每一帧都检测完整能进一步提升效率
PS:
- install requirements before running
- download trained model files from: (other Supplementary material also can be found here) https://drive.google.com/drive/folders/1AuthnUK7bqYOlLcKi1GkoLyHbq3GyjfX?usp=sharing
- unzip checkpoints_mlt.zip and put it into the checkpoints_mlt directory
- This project is based on eragonruan's code: https://github.com/eragonruan/text-detection-ctpn
- cnocr: https://github.com/breezedeus/cnocr