This demo was part of below technical webinar workshops
- "Real Time Monitoring with Hadoop" - Slides and webinar recording are available here
- "Search Workshop" - Slides and webinar recording are available here
Author: Ali Bajwa
With special thanks to:
- Guilherme Braccialli for helping to maintain the code and adding sentiment analysis component
- Tim Veil for developing the original banana dashboard
Purpose: Monitor Twitter stream for S&P 500 companies to identify & act on unexpected increases in tweet volume
-
Ingest: Listen for Twitter streams related to S&P 500 companies
-
Processing:
- Monitor tweets for unexpected volume
- Volume thresholds managed in HBASE
-
Persistence:
- HDFS (for future batch processing)
- Hive (for interactive query)
- HBase (for realtime alerts)
- Solr/Banana (for search and reports/dashboards)
- Audits in Ranger/Solr/Banana
- Authorization policies in Ranger
-
Refine:
- Update threshold values based on historical analysis of tweet volumes
-
Demo setup:
- Either download and start prebuilt VM
- Start HDP 2.4 sandbox and run provided scripts to setup demo
-
Previous versions
- Option 1: Setup demo using prebuilt VM based on HDP 2.3 sandbox
- Option 2: Setup demo via scripts on vanilla HDP 2.4 sandbox
- Kafka basics - optional
- Setup Eclipse
- Run demo to monitor Tweets about S&P 500 securities in realtime
- Stop demo
- Troubleshooting
- Observe results in HDFS, Hive, Solr/Banana, HBase
- Use Zeppelin to create charts to analyze tweets - optional
- Import data into BI tools - optional
- Other things to try - optional
- Reset demo
- Run demo on cluster
- Download VM from here. Import it into VMWare Fusion and start it up.
- Find the IP address of the VM and add an entry into your machines hosts file e.g.
192.168.191.241 sandbox.hortonworks.com sandbox
- Connect to the VM via SSH (password hadoop)
- Start the demo by
cd /root/hdp22-twitter-demo
./start-demo.sh
#once storm topology is submitted, press control-C
#start kafka twitter producer
./kafkaproducer/runkafkaproducer.sh
-
Observe results in HDFS, Hive, Solr/Banana, HBase
-
Troubleshooting: check the Storm webUI for any errors and try resetting using below script:
./reset-demo.sh
These setup steps are only needed first time and may take upto 30min to execute (depending on your internet connection)
-
While waiting on any step, if you don't already have Twitter credentials, follow steps here to get them
-
Download HDP 2.4 sandbox VM image file (Hortonworks_sanbox_with_hdp_2_4_vmware.ova) from Hortonworks website
-
Import the ova into VMWare Fusion and allocate at least 4cpus and 8GB RAM (its preferable to increase to 10GB+ RAM) and start the VM
-
Find the IP address of the VM and add an entry into your machines hosts file e.g.
192.168.191.241 sandbox.hortonworks.com sandbox
- Connect to the VM via SSH (password hadoop). You can also SSH via browser by clicking: http://sandbox.hortonworks.com:4200
- Download code as root user
cd
git clone https://github.com/hortonworks-gallery/hdp22-twitter-demo.git
- (Optional) To setup a development env on the sandbox to browse/modify the code, download Ambari service for VNC (details below). Not required if you just want to setup the demo
VERSION=`hdp-select status hadoop-client | sed 's/hadoop-client - \([0-9]\.[0-9]\).*/\1/'`
sudo git clone https://github.com/hortonworks-gallery/ambari-vnc-service.git /var/lib/ambari-server/resources/stacks/HDP/$VERSION/services/VNCSERVER
service ambari restart
- Setup demo:Run below to setup demo (one time): it will start Ambari/HBase/Kafka/Storm and install maven, solr, banana.
cd /root/hdp22-twitter-demo
./setup-demo.sh
- while it runs, proceed with installing VNC service per steps below
-
Once the status of HDFS/YARN has changed from a yellow question mark to a green check mark...
-
Setup Eclipse on the sandbox VM and remote desktop into it using an Ambari service for VNC
- In Ambari open, Admin > Stacks and Services tab.
- You can access this via http://sandbox.hortonworks.com:8080/#/main/admin/stack/services
- Deploy the service by selecting:
- VNC Server -> Add service -> Next -> Next -> Enter password (e.g. hadoop) -> Next -> Proceed Anyway -> Deploy
- Make sure the password is at least 6 characters or install will fail
- Connect to VNC from local laptop using a VNC viewer software (e.g. Tight VNC viewer or Chicken of the VNC or just your browser). Detailed steps here
- Import code into Eclipse using "Getting started with Storm and Maven in Eclipse environment" steps here
- Review Storm code in Eclipse under /root/hdp22-twitter-demo/stormtwitter-mvn/src/main/java/hellostorm:
- GNstorm.java: Main class, also where topology, KafkaSpout, HDFSBolts instatiated
- TwitterScheme.java: defines structure of a Tweet
- SolrBolt.java: writes to Solr
- TwitterRuleBolt.java: defines business logic of when a tweet should results in an alert
- In Ambari open, Admin > Stacks and Services tab.
- Twitter4J requires you to have a Twitter account and obtain developer keys by registering an "app". Create a Twitter account and app and get your consumer key/token and access keys/tokens: https://apps.twitter.com > sign in > create new app > fill anything > create access tokens
- Then enter the 4 values into the file below in the sandbox
vi /root/hdp22-twitter-demo/kafkaproducer/twitter4j.properties
oauth.consumerKey=
oauth.consumerSecret=
oauth.accessToken=
oauth.accessTokenSecret=
- Once Kafka is started, run through the below commands to understand the basics
#check if kafka already started
ps -ef | grep kafka
#if not, start kafka
nohup /usr/hdp/current/kafka-broker/bin/kafka-server-start.sh /usr/hdp/current/kafka-broker/config/server.properties &
#create topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --zookeeper $(hostname -f):2181 --replication-factor 1 --partitions 1 --topic test
#list topic
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper $(hostname -f):2181 --list | grep test
#start a producer and enter text on few lines
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $(hostname -f):6667 --topic test
#start a consumer in a new terminal your text appears in the consumer
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --zookeeper $(hostname -f):2181 --topic test --from-beginning
#hit Control-C on both terminals to quit the consumer/producer
#delete topic (only works if delete.topic.enable and setup auto.create.topics.enable is set to true in Ambari > Kafka > Config)
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --zookeeper $(hostname -f):2181 --topic test
Most of the below steps are optional as they were already executed by the setup script above but are useful to understand the components of the demo:
-
Review the list of stock symbols whose Twitter mentiones we will be tracking http://en.wikipedia.org/wiki/List_of_S%26P_500_companies
-
Generate securities csv from above page and review the securities.csv generated. The last field is the generated tweet volume threshold
/root/hdp22-twitter-demo/fetchSecuritiesList/rungeneratecsv.sh
cat /root/hdp22-twitter-demo/fetchSecuritiesList/securities.csv
- (Optional) for future runs: you can add other stocks/hashtags to monitor to the csv (make sure no trailing spaces/new lines at the end of the file). Find these at http://mobile.twitter.com/trends
sed -i '1i$HDP,Hortonworks,Technology,Technology,Santa Clara CA,0000000001,5' /root/hdp22-twitter-demo/fetchSecuritiesList/securities.csv
sed -i '1i#hadoopsummit,Hadoop Summit,Hadoop,Hadoop,Santa Clara CA,0000000001,5' /root/hdp22-twitter-demo/fetchSecuritiesList/securities.csv
- Open connection to HBase via Phoenix and check you can list tables. Notice securities data was imported and alerts table is empty
/usr/hdp/current/phoenix-client/bin/sqlline.py localhost:2181:/hbase-unsecure
!tables
select * from securities;
select * from alerts;
select * from dictionary;
!q
- check Hive table schema where we will store the tweets for later analysis
hive -e 'desc tweets_text_partition'
- Start Storm Twitter topology to generate alerts into an HBase table for stocks whose tweet volume is higher than threshold this will also read tweets into Hive/HDFS/local disk/Solr/Banana. The first time you run below, maven will take 15min to download dependent jars
cd /root/hdp22-twitter-demo
./start-demo.sh
#once storm topology is submitted, press control-C
- (Optional) Other modes the topology could be started in future runs if you want to clean the setup or run locally (not on the storm running on the sandbox)
cd /root/hdp22-twitter-demo/stormtwitter-mvn
./runtopology.sh runOnCluster clean
./runtopology.sh runLocally skipclean
- If you see errors like below, double check in Ambari that Storm is still up
Caused by: java.net.ConnectException: Connection refused
Could not find leader nimbus from seed hosts [sandbox.hortonworks.com]. Did you specify a valid list of nimbus hosts for config nimbus.seeds
-
open storm UI and confirm topology was created using either:
-
Start Kafka producer: In a new terminal, compile and run kafka producer to start producing tweets containing first 400 stock symbols values from csv
/root/hdp22-twitter-demo/kafkaproducer/runkafkaproducer.sh
-
To stop producing tweets, press Control-C in the terminal you ran runkafkaproducer.sh
-
kill the storm topology to stop processing tweets
storm kill Twittertopology
-
If Storm webUI shows topology errors...
-
Check the Storm webUI for any errors and try resetting using below script:
./reset-demo.sh
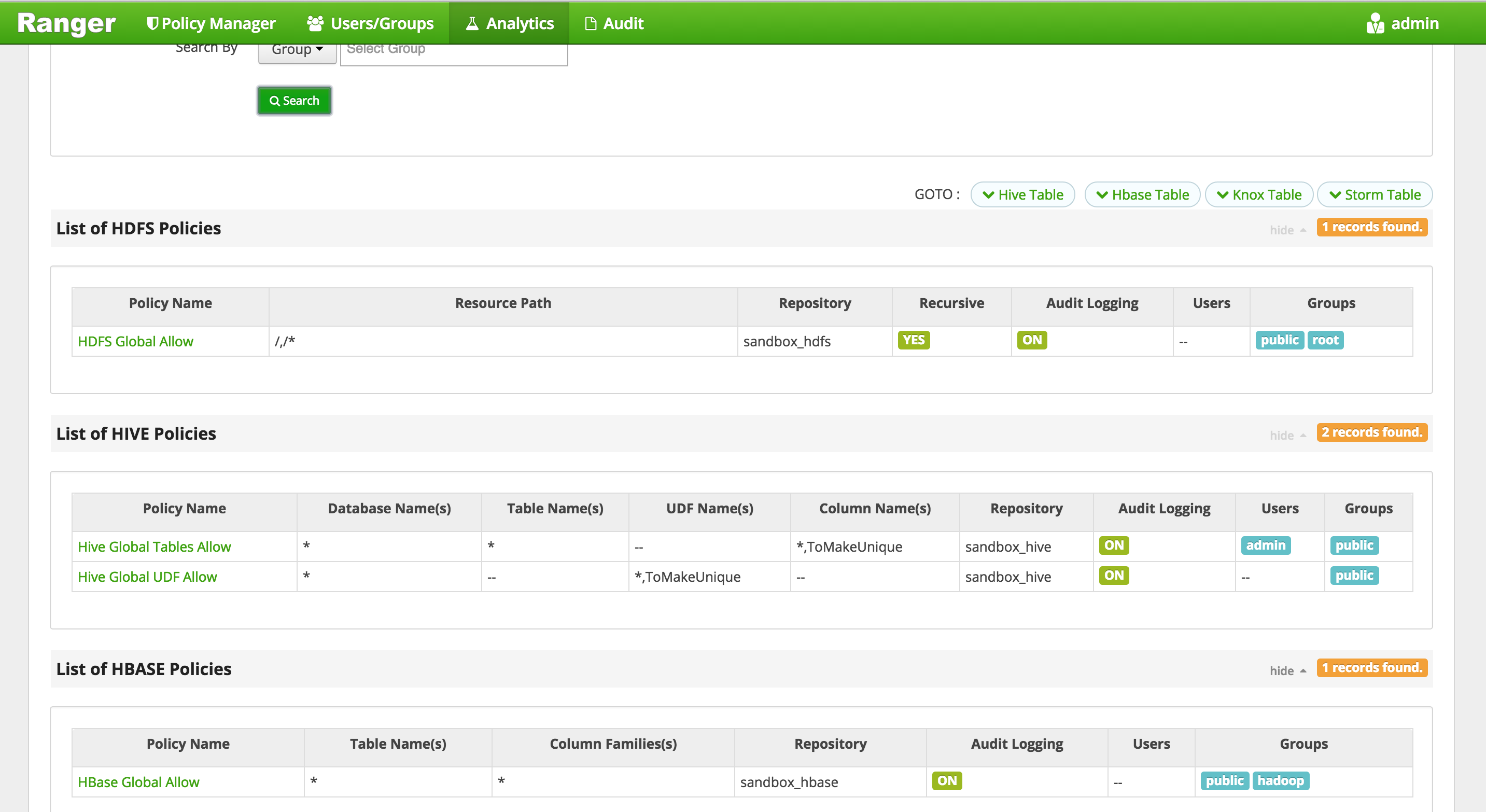
- (Optional): In case of Ranger authorization errors, add users to global allow policies
- Start Ranger and login to http://sandbox.hortonworks.com:6080 (admin/admin)
service ranger-admin start- "HDFS Global Allow": add group root to this policy - by opening http://sandbox.hortonworks.com:6080/#!/hdfs/1/policy/2
- "HBase Global Allow": add group hadoop to this policy - by opening http://sandbox.hortonworks.com:6080/#!/hbase/3/policy/8
- "Hive Global Tables Allow": add user admin to this policy - by opening http://sandbox.hortonworks.com:6080/#!/hive/2/policy/5
- Note you will need to first create an admin user - by opening http://sandbox.hortonworks.com:6080/#!/users/usertab

-
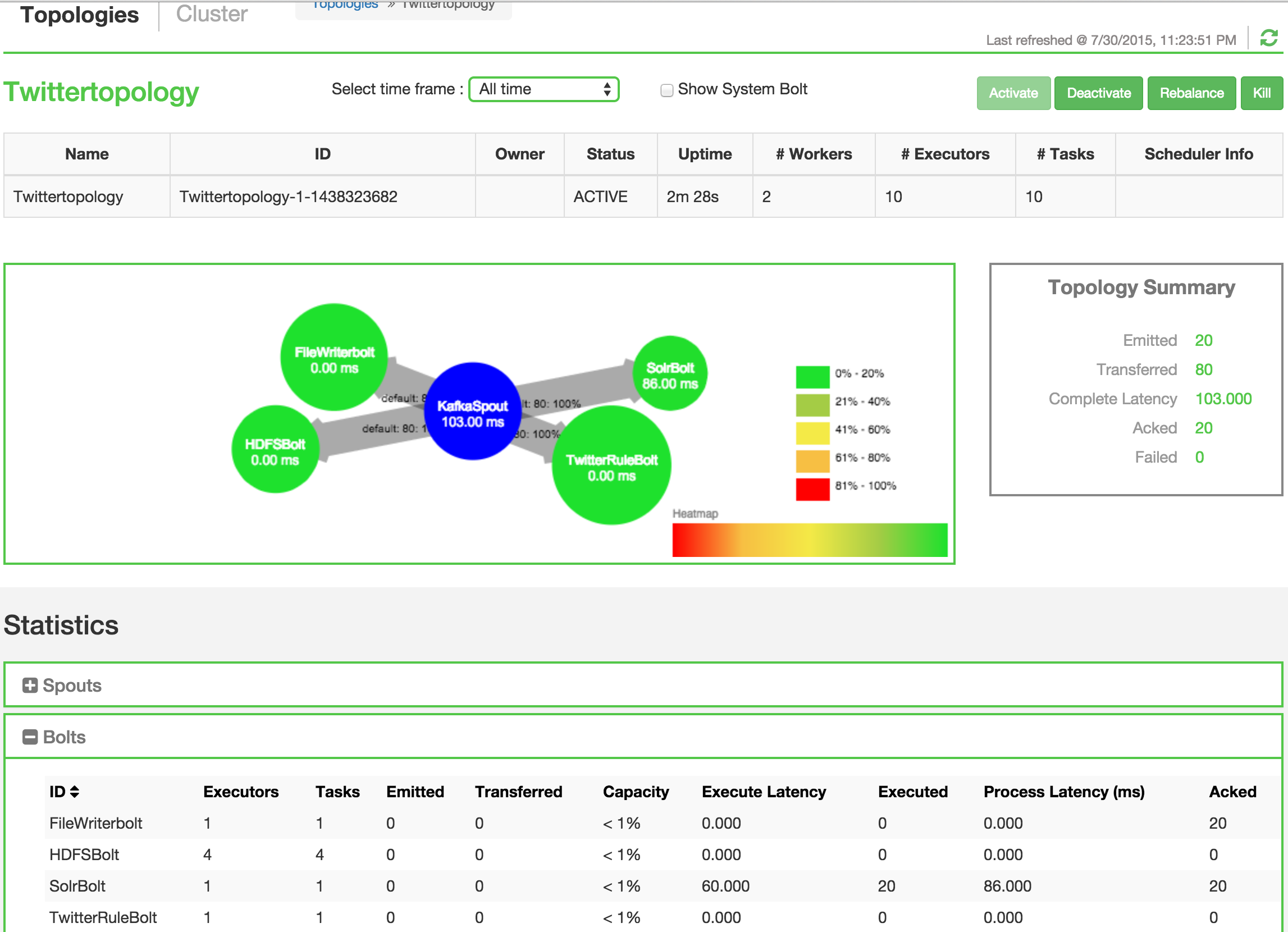
Open the new Storm View and check the statistics for each Bolt: 'Acked' columns should start increasing.

-
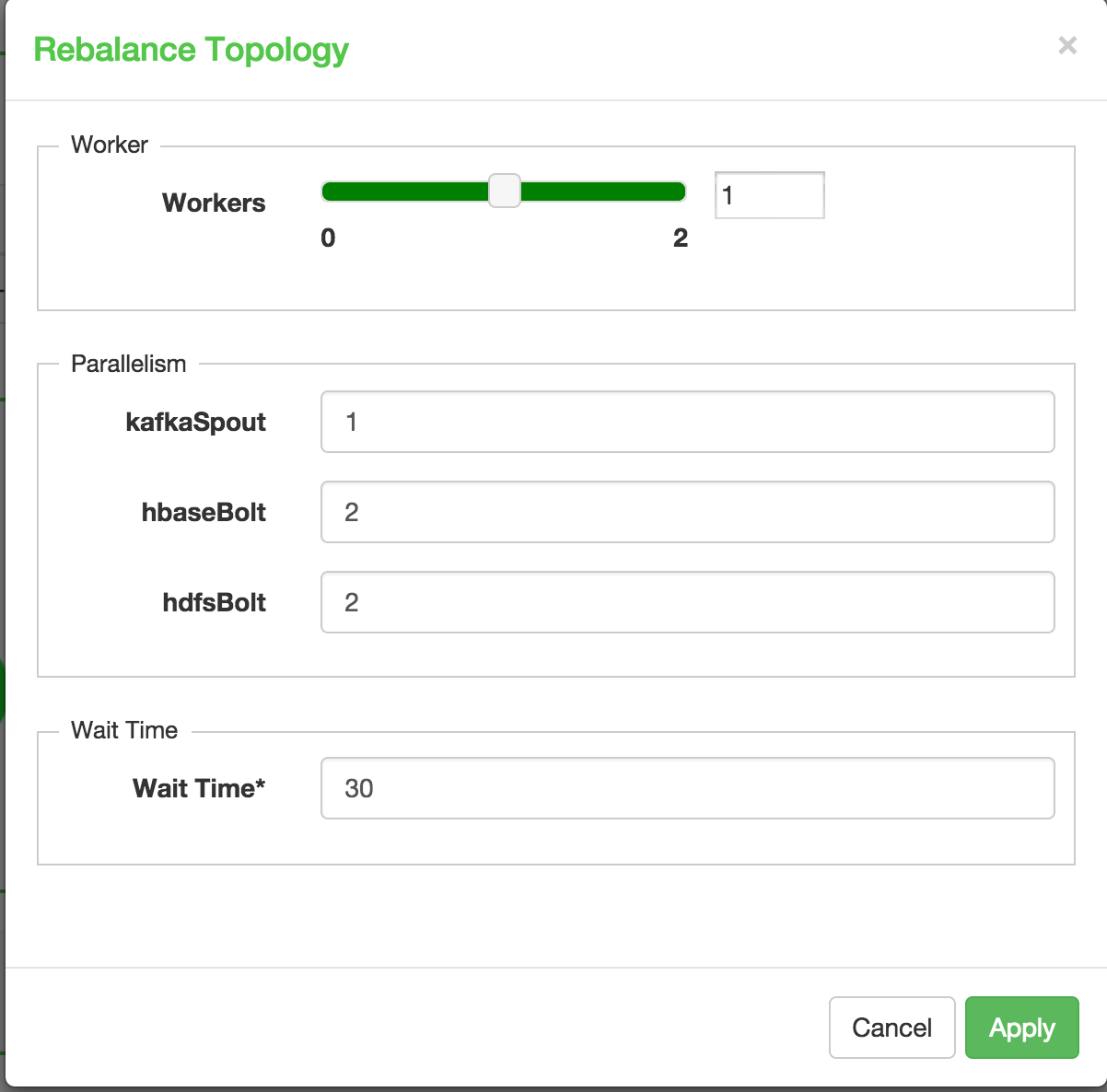
The Storm view also allows you to rebalance the topology:

-
The statistics also available via the Storm UI http://sandbox.hortonworks.com:8744/
-
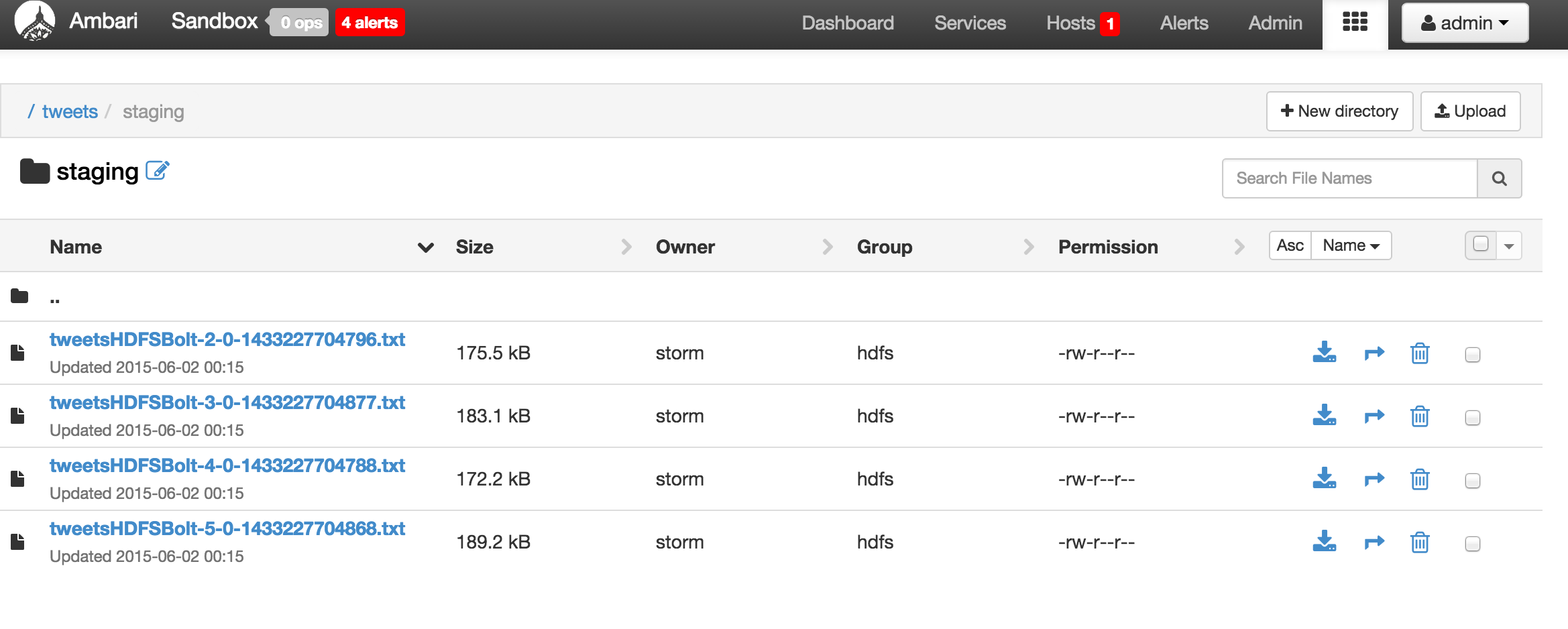
Open Files view and see the tweets getting stored: http://sandbox.hortonworks.com:8080/#/main/views/FILES/1.0.0/Files
- Open Hive table via Hive view. Notice tweets appear in the Hive table that was created: http://sandbox.hortonworks.com:8080/#/main/views/HIVE/1.0.0/Hive

-
Open Banana UI and view/search tweet summary and alerts: http://sandbox.hortonworks.com:8983/solr/banana/index.html

- You can also access the UI via Ambari view by following steps here and replacing the url with http://sandbox.hortonworks.com:8983/solr/banana/index.html
- For more details on the Banana dashboard panels are built, refer to the underlying json file that defines all the panels
- In case you don't see any tweets, try changing to a different timeframe on timeline (e.g. by clicking 24 hours, 7 days etc). If there is a time mismatch between the VM and your machine, the tweets may appear at a different place on the timeline than expected.
-
Run a query in Solr to look at tweets/hashtags/alerts. Click on 'Query' and enter a query under 'q'. Examples are doctype_s:tweet and text_t:AAPL. You can choose an output format under 'wt' and click 'Execute Query'. http://sandbox.hortonworks.com:8983/solr/#/tweets

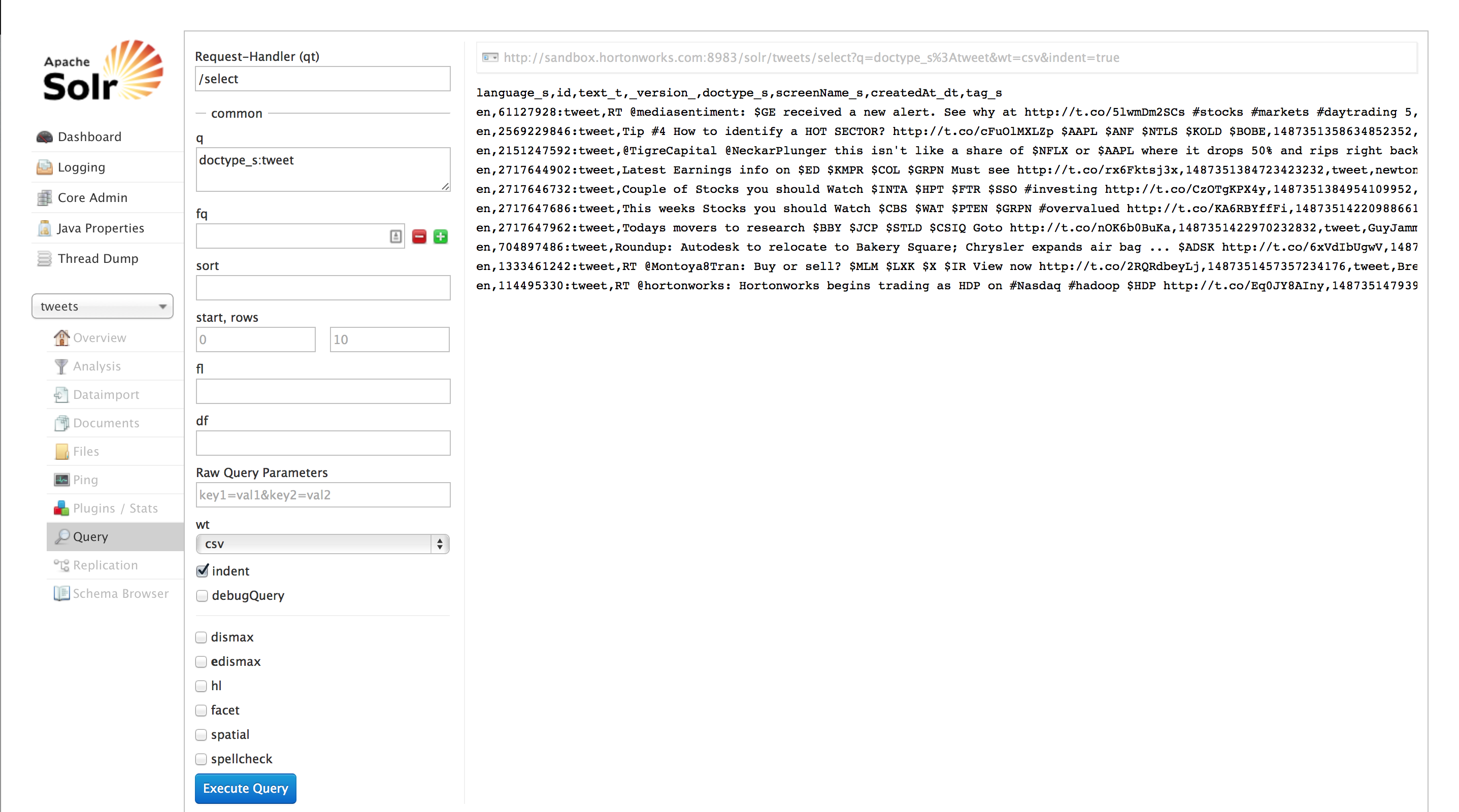
-
You can also search using Solr's APIs. The below displays all alerts in JSON format http://sandbox.hortonworks.com:8983/solr/tweets/select?q=*%3A*&df=id&wt=json&fq=doctype_s:alert
- The SolrBolt code showing how the data gets into Solr is shown here

- The SolrBolt code showing how the data gets into Solr is shown here
-
Open connection to HBase via Phoenix and notice alerts were generated

/usr/hdp/current/phoenix-client/bin/sqlline.py localhost:2181:/hbase-unsecure
select * from alerts

- Notice tweets written to sandbox filesystem via FileSystem bolt
vi /tmp/Tweets.xls
- Open Hive view and query the tweets table:

-
Apache Zeppelin can also be installed on the cluster/sandbox to generate charts for analysis using:
- Spark
- SparkSQL
- Hive
- Flink
-
The Zeppelin Ambari service can be used to easily install/manage Zeppelin on HDP cluster
-
Sample queries and charts:


- Create ORC table and copy the tweets over:
hive -f /root/hdp22-twitter-demo/stormtwitter-mvn/createORC.sql
- View the contents of the ORC table created: http://sandbox.hortonworks.com:8000/beeswax/table/default/tweets_orc_partition_single
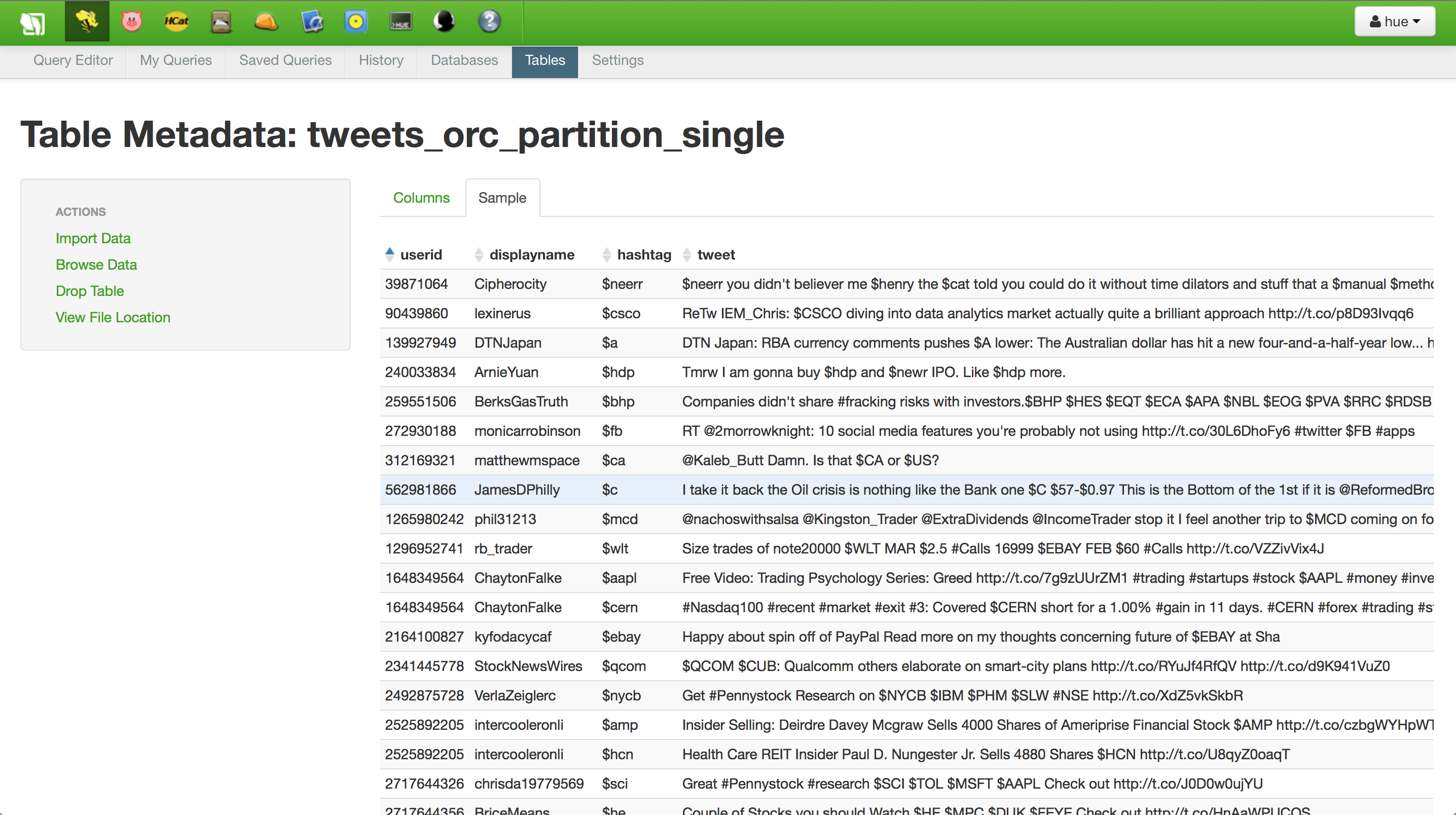
- Grant select access to user hive to the ORC table
hive -e 'grant SELECT on table tweets_orc_partition_single to user hive'
- On windows VM create an ODBC connector called sandbox with below settings:
Host=<IP address of sandbox VM>
port=10000
database=default
Hive Server type=Hive Server 2
Mechanism=User Name
UserName=hive
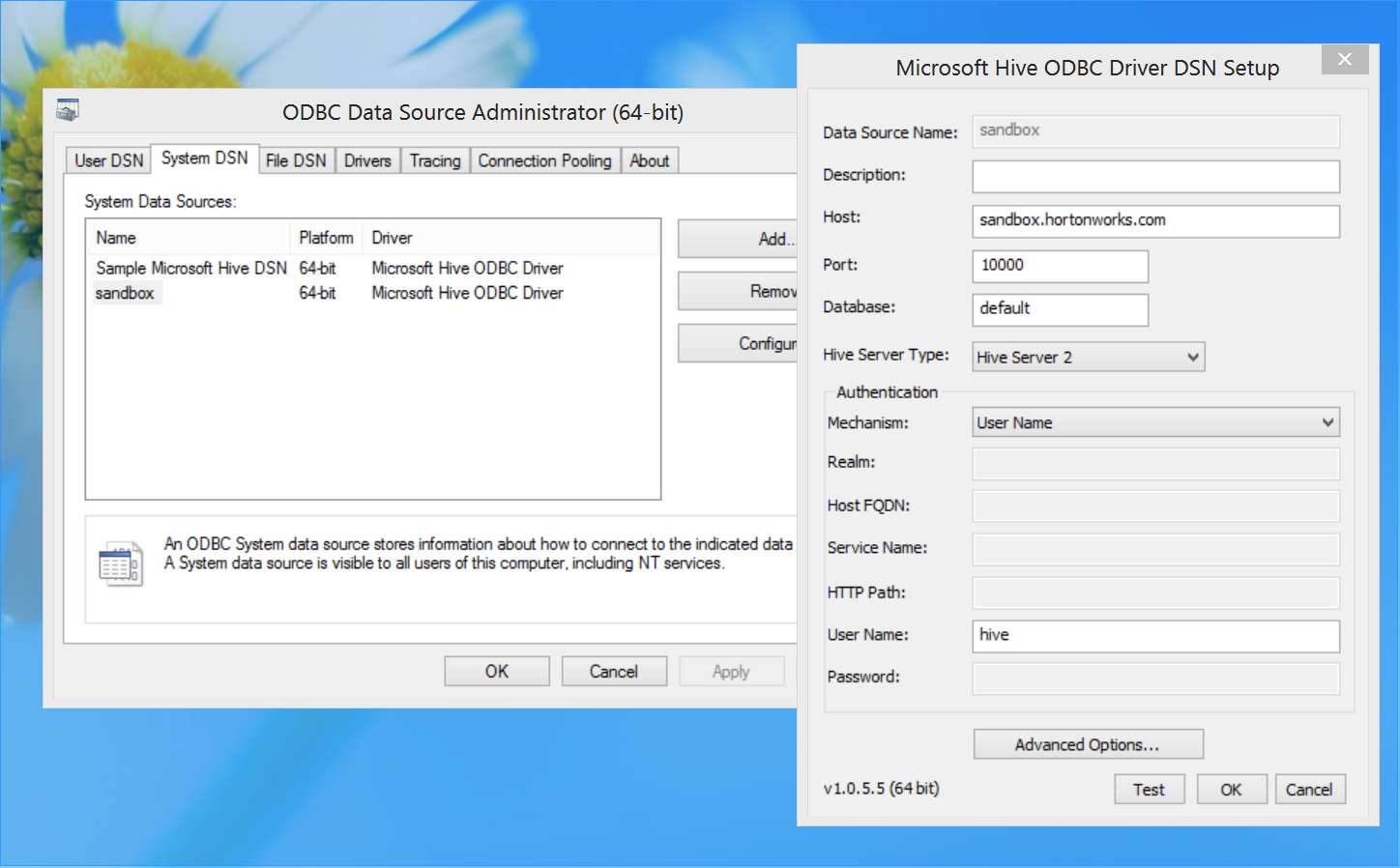
- Import data from tweets_orc_partition_single table into Excel over ODBC Data > From other Datasources > From dataconnection wizard > ODBC DSN > sandbox > tweets_orc_partition_single > Finish > Yes > OK
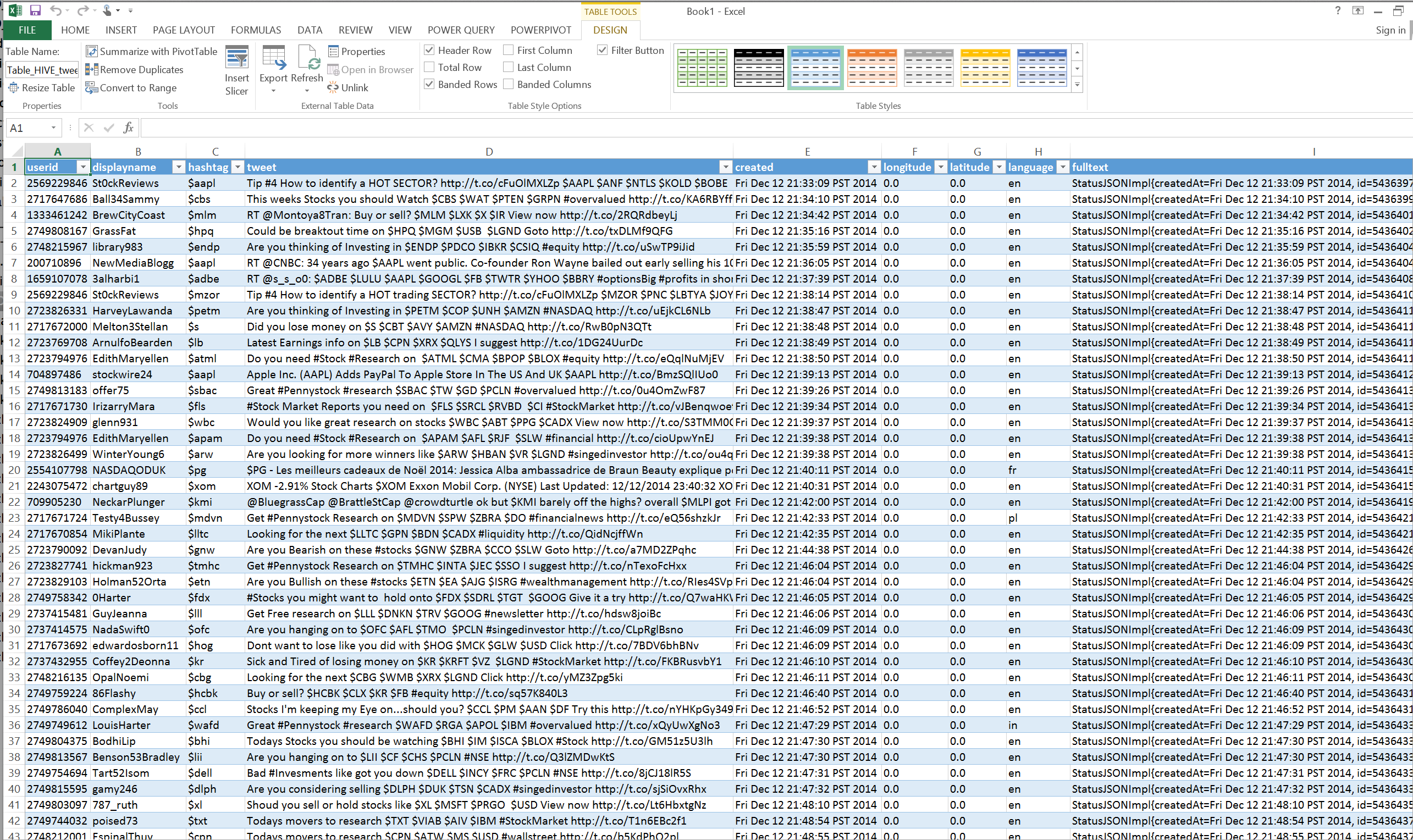
- Create some visualizations using PowerCharts (e.g. plotting tweets with coordinates on map)

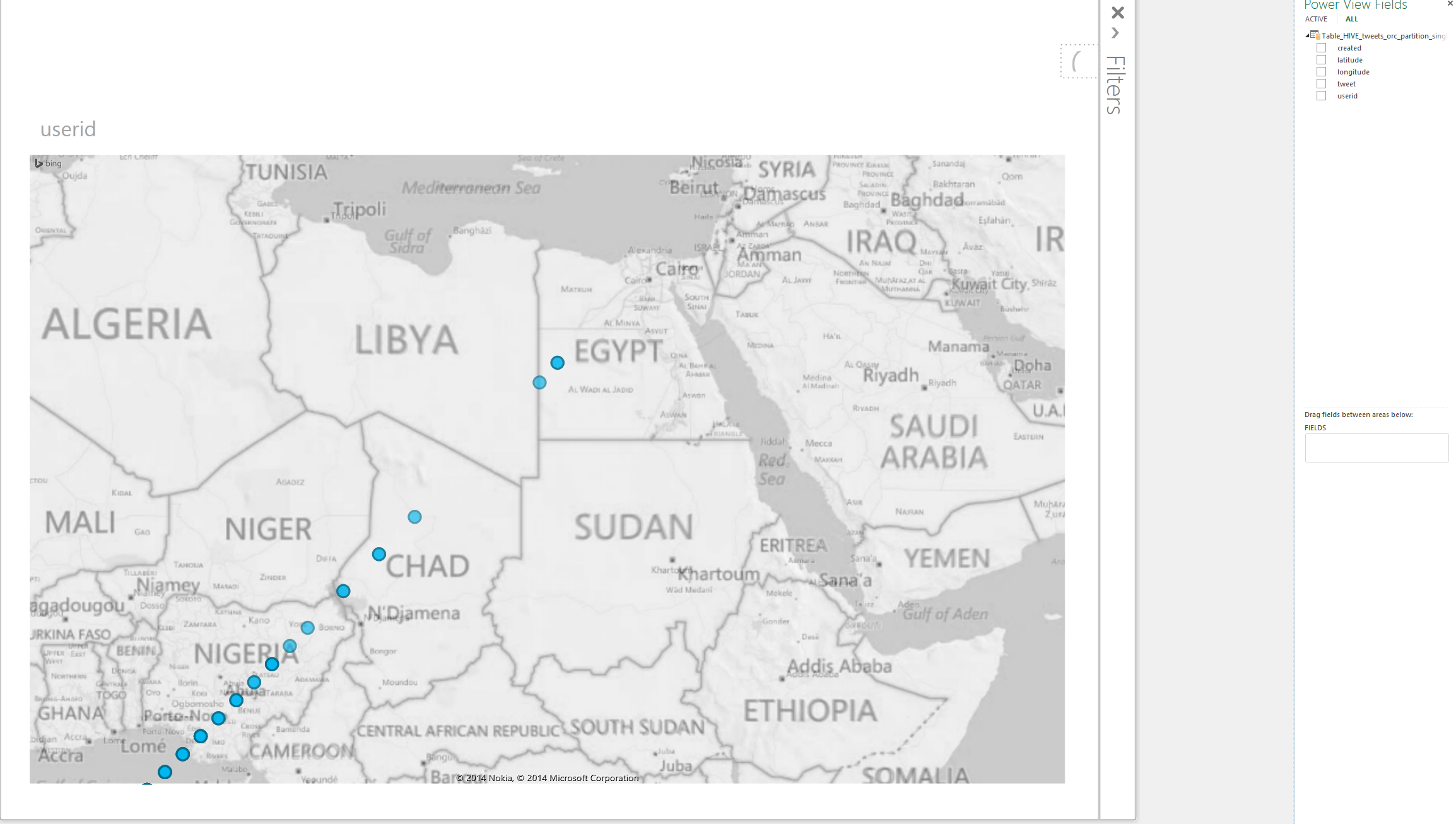
- Instead of filtering on tweets from certain stocks/hashtags, you can also consume all tweets returned by TwitterStream API and re-run runkafkaproducer.sh Note that in this mode a large volume of tweets is generated so you should stop the kafka producer after 20-30s to avoid overloading the system It also may take a few minutes after stopping the kafka producer before all the tweets show up in Banana/Hive
mv /root/hdp22-twitter-demo/fetchSecuritiesList/securities.csv /root/hdp22-twitter-demo/fetchSecuritiesList/securities.csv.bak
- To filter tweets based on geography open below file and uncomment this line and re-run runkafkaproducer.sh
vi /root/hdp22-twitter-demo/kafkaproducer/TestProducer.java
/root/hdp22-twitter-demo/kafkaproducer/runkafkaproducer.sh
- This empties out the demo related HDFS folders, Hive table, Solr core, Banana webapp and stops the storm topoogy
/root/hdp22-twitter-demo/reset-demo.sh
- If kafka keeps sending your topology old tweets, you can also clear kafka queue
zookeeper-client
rmr /group1
- To run on actual cluster instead of sandbox, there are a few things that need to be changed before compiling/starting the demo:
-
when running kafka/Hbase shell, change the zookeeper connect strings to use localhost instead of sandbox
-
/root/hdp22-twitter-demo/solrconfig.xml: change sandbox reference to HDFS location of solr user e.g. hdfs://summit-twitterdemo01.cloud.hortonworks.com:8020/user/solr
-
/root/hdp22-twitter-demo/default.json: change sandbox to Solr server (e.g. summit-twitterdemo01.cloud.hortonworks.com)
-
/root/hdp22-twitter-demo/stormtwitter-mvn/src/main/java/hellostorm/GNstorm.java: change zookeeper host, NN url, Hive metastore
BrokerHosts hosts = new ZkHosts("localhost:2181”);String fsUrl = "hdfs://summit-twitterdemo01.cloud.hortonworks.com:8020";String sourceMetastoreUrl = "thrift://summit-twitterdemo02.cloud.hortonworks.com:9083”;
-
/root/hdp22-twitter-demo/stormtwitter-mvn/src/main/java/hellostorm/SolrBolt.java: change Solr collection url reference and zookeeper host reference
server = new HttpSolrServer("http://summit-twitterdemo01.cloud.hortonworks.com:8983/solr/tweets");conn = phoenixDriver.connect("jdbc:phoenix:localhost:2181:/hbase-unsecure",new Properties());
-
/root/hdp22-twitter-demo/stormtwitter-mvn/src/main/java/hellostorm/TwitterRuleBolt.java: change Solr collection url reference and zookeeper host reference
conn = phoenixDriver.connect("jdbc:phoenix:localhost:2181:/hbase-unsecure",new Properties());SolrServer server = new HttpSolrServer("http://summit-twitterdemo01.cloud.hortonworks.com:8983/solr/tweets");
-