In this assignment, we'll implement and test two basic data structures:
1. Queue
A queue works like a line for an amusement park ride -- people enter at the end of the queue and leave from the front (FIFO: first in, first out).
Issuing instructions to your sandwich-making robot.
- Implement a queue with the following methods:
enqueue(element)- Adds an element to the back of the queuedequeue()- Remove and return the element at the front of the queuesize()- Return the number of items in the queuefront()- Return the element at the front of the queueisEmpty()- Returns true or false whether the queue has elementsprintQueue()- Prints all the elements of the queue
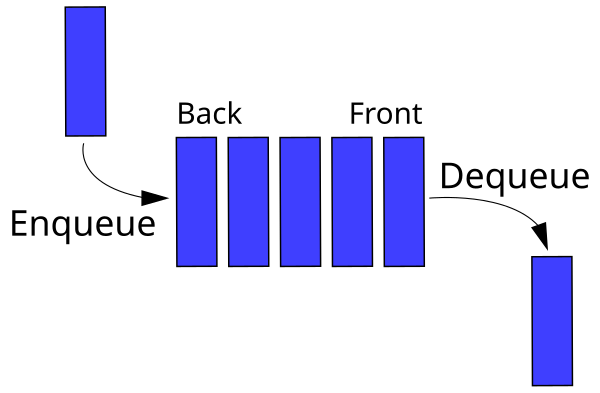
2. Stack
A stack works like a stack of plates -- plates are added and removed from the the top of the stack (LIFO: last in, first out).

Implementing your browser's back button.
- Implement a stack with the following methods:
push(element)- Add an element to the top of the stackpop()- Remove and return the element on the top of the stacksize()- Return the number of items on the stackpeek()- Return the top element on the stack, but it won't remove it (the waypop()does)isEmpty()- Returns whether or not the Stack is emptyprintStack()- Prints all the elements of a queue
Implement both stack and queue data structures in each of the instantiation styles. The functional style is stubbed out in src/functional/queue.js and src/functional/stack.js to get you started.
- No arrays! Instead, use an object with numeric keys
-
Pass all the tests. To run all the tests, first run
npm startin your terminal from the sprint's root directory. You'll know if this step completed successfully when you see the following output in your terminal:Serving "/Users/.../your-sprint-folder" at http://127.0.0.1:xxxxNow, navigate to the
http://127.0.0.1:xxxxlink in your browser (don't forget to include the colon and extra numbers at the end), and open theSpecRunner.htmlfile.
-
Implement a stack with the following methods:
push(string)- Add a string to the top of the stackpop()- Remove and return the string on the top of the stacksize()- Return the number of items on the stack
-
Implement a queue with the following methods:
enqueue(string)- Add a string to the back of the queuedequeue()- Remove and return the string at the front of the queuesize()- Return the number of items in the queue
-
Functional instantiation: a simple "maker" pattern
- Do:
- Work within the
src/functional/folder - Define all functions and properties within the maker function
- Capitalize the maker function name
- Work within the
- Don't:
- Use the keyword
new, the keywordthis, or anyprototypechains
- Use the keyword
- Example: The provided classes
StackandQueuealready follow this pattern
- Do:
-
Functional instantiation with shared methods: same as step 1, but with shared methods
- Do:
- Work within the
src/functional-shared/folder - Create an object that holds the methods that will be shared by all instances of the class
- Use the keyword
thisin your methods - Use
_.extendto copy the methods onto the instance
- Work within the
- Don't:
- Use the keyword
neworprototypechains
- Use the keyword
- Example: functional instantiation example
- Do:
-
Prototypal instantiation: using
Object.create- Do:
- Work within the
src/protoypal/folder. - Use
Object.createwith the object from step 2 to create instances of your class
- Work within the
- Don't:
- Use the keyword
new
- Use the keyword
- Example: prototypal instantiation example
- Do:
-
Pseudoclassical instantiation: create instances with the keyword
new- Do:
- Work within the
src/pseudoclassical/folder - Capitalize your function name to indicate to others that it is intended to be run with the keyword
new - Use the keyword
newwhen instantiating your class - Use the keyword
thisin your constructor
- Work within the
- Don't:
- Declare the instance explicitly
- Return the instance explicitly
- Example: pseudoclassical instantiation example
- Do:
-
ES6 instantiation: declare classes with the keyword
class- Do:
- Work within the
src/es6/folder - Capitalize your function name to indicate to others that it is intended to be run with the keyword
new - Use the keyword
newwhen instantiating your class - Use the keyword
thisin your constructor - Explicitly declare a class method named
constructor - Declare all other class methods within the class declaration
- Work within the
- Don't:
- Declare the instance explicitly
- Return the instance explicitly
- Add class methods to the class prototype directly
- Example: es6 instantiation example
- Do:
This repo holds a mostly-empty Mocha test suite. To run all the tests, first run npm start in your terminal from the sprint's root directory. You'll know if this step completed successfully when you see the following output in your terminal:
Serving "/Users/.../your-sprint-folder" at http://127.0.0.1:xxxx
Now, navigate to the http://127.0.0.1:xxxx link in your browser (don't forget to include the colon and extra numbers at the end), and open the SpecRunner.html file.
Some failing specs are included. You're welcome! You should make them pass, then write more specs and more code.
1. Linked List
A linked list is a dynamic data structure that allows for constant time insertion and removal at any point in the linked list (compare this to an array which on average has linear time insertion and removal operations). In exchange for this insertion and removal speed, linked lists are not indexed and any find operations on a link list require the linear time operation of traversing the entire linked-list from the beginning.

An itinerary you expect to add and remove destinations to and from.
- A
linkedListclass, in functional style, with the following properties:-
.headproperty, alinkedListNodeinstance -
.tailproperty, alinkedListNodeinstance -
.addToTail()method, takes a value and adds it to the end of the list -
.removeHead()method, removes the first node from the list and returns its value -
.contains()method, returns boolean reflecting whether or not the passed-in value is in the linked list - What is the time complexity of the above functions?
-
2. Tree
A tree is a hierarchical data structure consisting of a node (potentially) with children. The children are trees unto themselves, that is, nodes with (potential) children. For this reason the tree is referred to as a recursive data structure.

Making a family tree.
- A
treeclass, in functional with shared methods style, with the following properties:-
.childrenproperty, an array containing a number of subtrees -
.addChild()method, takes any value, sets that as the target of a node, and adds that node as a child of the tree - A
.contains()method, takes any input and returns a boolean reflecting whether it can be found as the value of the target node or any descendant node - What is the time complexity of the above functions?
-
3. Graph
Graphs consist of nodes (often referred to as vertices) and edges (often referred to as arcs) that connect the nodes. Unlike trees, graphs are not necessarily hierarchical. Graphs can be undirected, which means that the relationship of any 2 nodes connected by an edge is a symmetrical relationship, or they can be directed, which means there is an asymmetrical relationship between nodes that are connected by an edge. You will be implementing an undirected graph.

Representing how a collection of websites (or the entire world wide web) link to each other, and many other things
- Implement a
graphclass, in pseudoclassical style, with the following properties:- It is an undirected graph. It does not have to be 'connected'.
- An
.addNode()method that takes a new node and adds it to the graph - A
.contains()method that takes any node and returns a boolean reflecting whether it can be found in the graph - A
.removeNode()method that takes any node and removes it from the graph, if present. All edges connected to that Node are removed as well. - An
.addEdge()method that creates a edge (connection) between two nodes if they both are present within the graph - A
.hasEdge()method that returns a boolean reflecting whether or not two nodes are connected - A
.removeEdge()method that removes the connection between two nodes - A
.forEachNode()method that traverses through the graph, calling a passed in function once on each node - What is the time complexity of the above functions?
4. Set
Sets contain unique values in no particular order.
A raffle, where all the tickets are unique and you just want to randomly pick one (or several) out of them all.
- A
setclass, in prototypal style, with the following properties:- An
.add()method, takes any string and adds it to the set - A
.contains()method, takes any string and returns a boolean reflecting whether it can be found in the set - A
.remove()method, takes any string and removes it from the set, if present - What is the time complexity of the above functions?
- Note: Sets should not use up any more space than necessary. Once a value is added to a set, adding it a second time should not increase the size of the set.
- Note: Until the advanced section, your sets should handle only string values.
- Note: This is a rather simple data structure. Take a look at the Wikipedia entry. Which native Javascript type fits the requirements best?
- An
5. Hash Table
Hash tables (sometimes called hash maps) store key value pairs. They do so in a memory efficient way by using a 'hashing function' that translates keys into numerical indices located within a fixed block of memory (think about the contiguous blocks of memory used in arrays). Hash tables only increase their size in memory when necessary, and reduce their size in memory when possible.
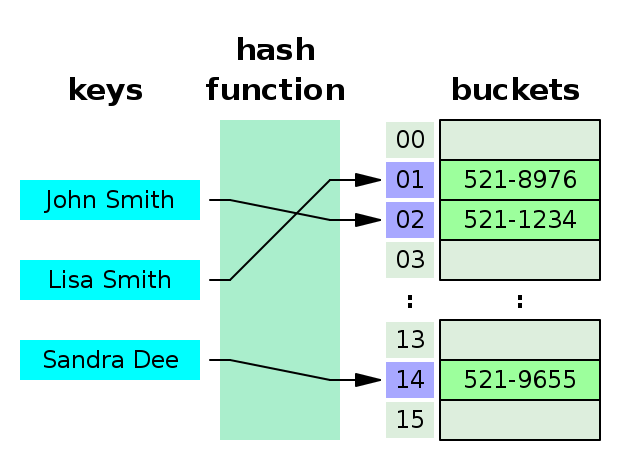
A contact list you might add to or remove from over time.
- A
hashTableclass, in pseudoclassical style:- First: Play with each of the helper functions provided to get a sense of what they do.
- You will use the provided hash function to convert any key into an array index. Try interacting with it from the console first.
- A
limitedArrayhelper has been provided for you, check out the source code for it insrc/hashTableHelpers.js. Use it to store all inserted values rather than using a plain JavaScript array. ThelimitedArray, as you will see in the source code, providesget,set, andeachmethods which you should use in order to interact with it. Do not use the typical bracket notation for arrays when interacting with alimitedArrayinstance. Try interacting with it from the console first.
- Make the following properties appear on all instances:
- An
.insert()method - A
.retrieve()method - A
.remove()method
- An
- What is the time complexity of the above functions?
- First: Play with each of the helper functions provided to get a sense of what they do.
- Using your understanding of hash tables, refactor your set implementation from above to run in constant time
On Objects and Hash Tables: An astute hacker might find themself wondering "Is it not so that a JavaScript object is a hash table?" or even further, "Why would I ever need to create a hash table in JavaScript?" While it is true that objects and hash tables are functionally similar, knowing how a hash table works is hugely important as they are an incredibly useful and fundamental data structure. To have detailed knowledge of how a hash table is constructed will give you valuable insight on your path to code mastery. Additionally, other languages might not provide the convenience of JavaScript's object class, meaning you may someday have to put your hash table construction abilities to good use.
**Interesting Aside: JavaScript objects aren't necessarily backed by hash tables. Despite the similarities, the ECMA-262 standard makes no restrictions on how JavaScript objects are implmented. The V8 JavaScript engine, which is used in Chrome, implements objects in a way that is significantly faster than using a hash table.
Binary trees are trees that can only have 0, 1, or 2 children. Remember that trees are recursive data structures and therefore a tree's children are themselves trees and can each have 0, 1, or 2 children. In a binary search tree, one child (out of potentially two) will always be less than the node's value (based on whatever sorting condition you wish) and the other child will always be greater than the node's value. Whether it is the 'left' or the 'right' child which is greater or lesser is consistent throughout the binary search tree. This structure results in particularly fast find operations. You'll be asked to answer just how fast yourself.

A dictionary of all English words.
- Implement a
binarySearchTreeclass with the following properties:- A
.leftproperty, a binary search tree (BST) where all values are lower than the current value. - A
.rightproperty, a BST where all values are higher than the current value. - A
.insert()method, which accepts a value and places it in the tree in the correct position. - A
.contains()method, which accepts a value and returns a boolean reflecting whether or not the value is contained in the tree. - A
.depthFirstLog()method, which accepts a callback and executes it on every value contained in the tree. - What is the time complexity of the above functions?
- Use case: Given a list of a million numbers, write a function that takes a new number and returns the closest number in the list using your BST. Profile this against the same operation using an array.
- A
- For each of the data structures you have implemented, go back and add at least one additional unit test. If possible, try to add a test that will require you improve your implementation in order to make the test pass.
tl;dr: prefix private properties and methods with an underscore
APIs are more than just URLs that return data; API is a general term that refers to the visible surface of any system, object, or library with which your code interacts. E.g., an airplane has an API that consists of knobs, dials, pedals, and a yoke which allow the pilot to make use of the airplane's underlying implementation--an engine, wings, and rudders. Importantly, the next model of airplane will probably have improvements to the engine, but the pilot need not know about this, as the controls will remain basically unchanged.
This relationship between APIs and implementations--that they remain independent--is what keeps the towering stacks of software we use everyday from falling over.
In JavaScript, because there is no concept of private variables (except through closure), sometimes API and implementation are both visible. If it's impossible to distinguish between API and implementation, you might depend upon a piece of implementation that later changes and breaks your code.
To prevent this from happening to your collaborators and consumers, indicate private properties and methods by prefixing them with an underscore. This is how we do.
Our advanced content is intended to throw you in over your head, requiring you to solve problems with very little support or oversight, much like you would as a mid or senior level engineer.
- Use the [Chrome profiling tools] to compare the performance of each instantiation pattern.
- Create a new HTML page with your data structures and an additional profiling script. It should instantiate and use a large number of stacks and queues
- Reload the page with the CPU profiler running to investigate the runtime of your functions
- Take a heap snapshot to investigate object allocations and memory use
- Optionally, reload the page with the heap profiler running to investigate garbage collection behavior
- Do this for each of the instantiation styles, record, and compare the results. Write a brief analysis you could share with a supervisor who needs the information you have in order to make wise decisions about the design of an upcoming project.
Note: The following prompts have varying levels of difficulty and you may not wish to complete all of them in entirety. In order to decide how to allocate your time, please read the descriptions of all of them before starting.
Implement the following data structures and improvements. Use any instantiataion style you like.
Optional, but highly recommended: Use TDD.
- Create a
doubly-linked-list, with all the methods of your linked list, and add the following properties:- An
.addToHead()method which takes a value and adds it to the front of the list. - A
.removeTail()method which removes the last node from the list and returns its value.
- Note: each
nodeobject will need to have a new.previousproperty pointing to the node behind it (or tonullwhen appropriate); this is what makes it a doubly-linked list.
- An
- Add parent links to your
tree- A
.parentproperty, which refers to the parent node or null when there is no node - A
.removeFromParent()method, which disassociates the tree with its parent (in both directions)
- A
- To prevent excessive collisions, make your
hashTabledouble in size as soon as 75 percent of the spaces have been filled - To save space, make sure the
hashTablehalves in size when space usage falls below 25 percent - Implement a
.traverse()method on yourtree. Your.traverse()should accept a callback and execute it on every value contained in the tree -
.breadthFirstLog()method forbinarySearchTee, logs the nodes contained in the tree using a breadth-first approach - Make your
setcapable of handling numbers as well as strings - Make your
setcapable of handling input objects of any type - Make your
binarySearchTreerebalance as soon as the max depth is more than twice the minimum depth
- Implement a
bloomFilter:- Read the Wikipedia article about Bloom Filters and/or BillMill.org's Bloom Filters by Example. tl;dr: It's a probabalistic data structure that efficiently determines whether or not an element is contained in a set. The downside is that is can report false positives. Use cases are often for checking against a giant list locally and only doing a full lookup when the local one comes back positive.
- Create an "m=18, k=3" bloom filter. This means 18 slots, with 3 hash functions.
- Run a small loop that runs 10,000 trials of trying to retreive a mix of items that are in the filter and not in the filter.
- Record the empirical rate of false-positives by comparing your result with what you know to be true from the inputs you selected.
- Compare that rate with the approximation given for Bloom filters, which is approximated as
(1- e^(-kn/m))^k
Note: Please feel free to attempt the following in any order you would like.
- Write a
prefixTreethat can handle autocomplete for T9-style texting - Write a
bTree - Write a
redBlackTree - Design a data structure that finds every English word that can be made from a given bag of Scrabble letters
- Optimize the algorithm and the data structure to return the set of words as quickly as possible
- Your priority for this task is to optimize for time complexity, but do try to avoid wasted space in your solution
- You can assume you have all the time required to do preprocessing on a dictionary of English words
- Optimize the algorithm and the data structure to return the set of words as quickly as possible
- Advanced
graphwork using Node.js (see section below)
For this exercise you will work with adjacency list representations of graphs using Node.js, which will allow you to interact with your file system. You'll learn a ton about node later in the course, but this is advanced content so why not get started early.
-
Create a basic JavaScript file that logs something to the console
-
In the terminal, in the directory of the file you just created (for this example let's say it's called
test.js) run the commandnode test.js. You just ran JavaScript with the node interpreter and should see whatever you logged to the console in the terminal -
Familiarize yourself with Adajency Lists and Adjacency Matrices
-
Whiteboard either a directed or an undirected graph and then translate it into an adjacency list text file
-
Write a function to return how many nodes your graph has. In order to accomplish this you will need to use node's
fsmodule to read your adjacency list text file and split it into lines. You'll learn how to do this later in the course, but for now, feel free to use the following code:// this line lets you access the file system. You'll learn more about it later in the course var fs = require('fs'); // read the `adjacency-list` file in this directory (you might have named the file differently) and split it on new lines into an array var fileLines = fs.readFileSync('./adjacency-list').toString().split('\n'); // you may have to do this 0 or more times, to remove blank lines from fileLines fileLines.pop(); fileLines.forEach(function(line) { // here you have access to each line of the adjacency list console.log(line); });
-
Write a function to peform a depth first search (DFS) on your graph and output the node values in depth first order
- Write Unit Tests for your DFS function
-
Try running your DFS function on a larger adjacency list
- Find, or create, a data set that will result in your exceeding the maximum call stack size, and then, refactor your DFS function to use tail-call recursion which is now possible in JavaScript on account of new language features introduced in the ES6 specification.
-
Implement Karger's Algorithm to identify the Minimum Cut for the minimum number of edges in an undirected graph
- Write Unit Tests for your implementation
- Start with a small undirected graph (in adjacency list format) of your own making, then give it a go with a larger adjacency list
- Try really hard to break your implementation so you are forced to improve it
-
Use Kosaraju's Algorithm to identify the greatest strongly connected component (SCC) of a directed graph
- Write Unit Tests for your implementation
- Start with a small directed graph (in adjacency list format) of your own making, then give it a go with a larger adjacency list
- Try really hard to break your implementation so you are forced to improve it
-
Build a web crawler (see the Nightmare Mode content from the Recursion Review repo), to crawl the webgraph, and utilize your implementation of Kosaraju's Algorithm to identify clusters of strongly connected web sites. Present your findings in a way that is easy for humans to understand.
- Make your web crawler robust enough to run overnight, recovering from failures, so that you can return in the morning with massive amounts of meaningful data.
- As your web crawler runs, store all the information it gathers in redis. You will have to use the Node.js redis client in order to do this.
- Data structure coverage in Wikipedia is no joke. Consider heading to Wikipedia when you have questions about data structures you are working with, or want to start learning about new ones.
- VisuAlgo is an incredible sight with clean visualizations of all kinds of data structures and algorithms.
- functional instantiation example
- prototypal instantiation example
- pseudoclassical instantiation example
- es6 instantiation example
- Object.create
- _.extend
- Mocha
- Chrome profiling tools
- Node.js
- Stack
- Queue
- Array
- Array methods
- Linked List
- Doubly Linked List
- Set
- Tree
- Binary Search Tree
- Graph
- Graph Examples
- Hash Table
- prefixTree
- bTree
- redBlackTree
- adjacencyMatrix
- adjacencyList
- depthFirstSearch
- largeDataSets
- minimumCut
- kargersAlgorithm
- kosarajusAlgorithm
- SCC