PyTorch implementation of Stacked Capsule Auto-Encoders [1].
Ported from official implementation with TensorFlow v1. The architecture of model and hyper-parameters are kept same. However, some parts are refactored for ease of use.
Please, open an issue for bugs and inconsistencies with original implementation.
⚠️ : The performance of this implementation is inferior than the original due to an unknown bug. There is already an open issue for this, but it has been resolved yet.
# clone project
git clone https://github.com/bdsaglam/torch-scae
# install project
cd torch-scae
pip install -e .It uses PyTorch Lightning for training and Hydra for configuration management.
# CPU
python -m torch_scae_experiments.mnist.train
# GPU
python -m torch_scae_experiments.mnist.train +trainer.gpus=1You can customize model hyperparameters and training with Hydra syntax.
python -m torch_scae_experiments.mnist.train \
data_loader.batch_size=32 \
optimizer.learning_rate=1e-4 \
model.n_part_caps=16 \
trainer.max_epochs=100 After training for 5 epochs
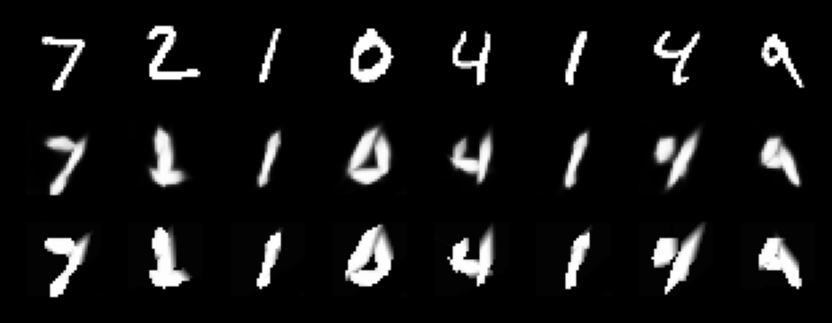
Fig 1. Rows: original image, bottom-up reconstructions and top-down reconstructions
- Kosiorek, A. R., Sabour, S., Teh, Y. W., & Hinton, G. E. (2019). Stacked Capsule Autoencoders. NeurIPS. http://arxiv.org/abs/1906.06818