{kind=link}
{kind=link}
{kind=link}
{kind=link}
A personal project on Facial Expression Recognition where I created a Flask backend website which uses OpenCV to capture video through (server) webcam, detects the face in the frames and classifies the frame to the expression displayed.
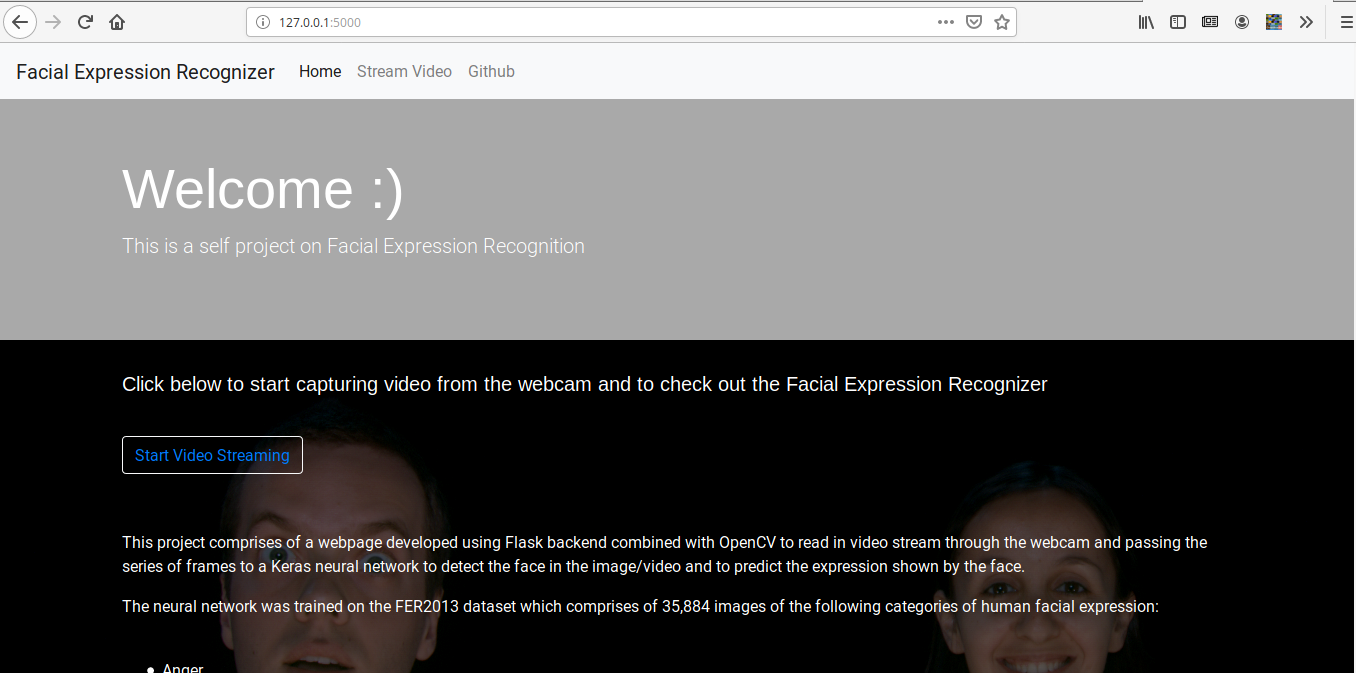


As you can see, the project consists of a flask web app where user can start a live stream from the (server) webcam. This was made possible through OpenCV. OpenCV captures video which is basically a series of frames. These frames are passed to a neural network which was trained on the FER2013 dataset. Using OpenCV and the Haar-Cascade files we can detect the faces too.
I used the FER2013 dataset which can be found in this link to train the model. Human expressions can be classified into 7 categories: Angry, Happy, Disgust, Fear, Neutral, Sad, Surprised. The dataset comprises of a CSV file which contains all the pixel values of the images in rows and a value which represents the expression diplayed in the corresponding image. The images are all 48x48 large and are grayscale.
I have added a python script to read the csv file and to create the images in separate expression directories. You can find the link here. We use a tensorflow.keras model to train on the dataset. Although this dataset contains a large number of images, the quality of the images makes it really hard to achieve any good validation/training accuracy. Credits to Furkan Kinli for his article in Medium and we use the specified architecture for our neural network as given in the said article.
Model architecture:
-
[2 x CONV (3x3)] — MAXP (2x2) — DROPOUT (0.5)
-
[2 x CONV (3x3)] — MAXP (2x2) — DROPOUT (0.5)
-
[2 x CONV (3x3)] — MAXP (2x2) — DROPOUT (0.5)
-
[2 x CONV (3x3)] — MAXP (2x2) — DROPOUT (0.5)
-
Dense (512) — DROPOUT (0.5)
-
Dense (256) — DROPOUT (0.5)
-
Dense (128) — DROPOUT (0.5)
This model does relatively well. I got a 65% accuracy on my training and validation dataset after training it for 100 epochs. After training the model was saved.
Model accuracy graph:

Face detection was done with the help of Haar Cascade files (I have uploaded them in the repository) and OpenCV. After starting the video capture using OpenCV which automatically starts after user clicks on "Start Video Streaming" link, the frames are passed to detect any faces and if any, it draws a rectangle over the face. The region of interest, that is, the face alone is then cropped out and reshaped into 48x48 to pass it to our trained model which predicts the expression.
Basic HTML and CSS coding was done to create the webpages. Multiple background images were used to make the background. The HTML and the CSS files for the site can be found in the templates and static directory. The MainApp.py is the server script. The background images in the Home Page were used from this dataset.