I wrote a blog post with some additional information on the project here https://traintestsplit.com/twitter-sentiment-analysis-in-python-with-code/
Data Pipeline Architecture of Streaming Twitter Data into Apache Kafka cluster, performing simple sentiment analysis with TextBlob module, and subsequently storing the data into MongoDB. Finally, the results are presented in a dashboard that updates live built with Plotly and Dash. The high level architecture can be seen in the following picture.
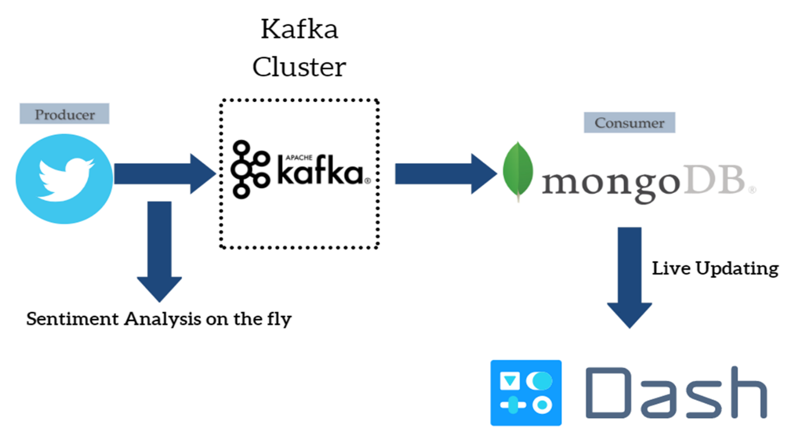
The pipeline makes use of the twitter streaming API in order to stream tweets in Python in real time, according to specified keywords. The tweets are pushed into a topic in the Kafka cluster by the aforementioned twitter producer. The streaming twitter data are in JSON format.
A selection of the relevant fields, as well as simple sentiment analysis, are done during the streaming process. The code is implemented in such a way that the text field of tweets, as well as retweets, is not truncated.
On the other end, a MongoDB consumer consumes the streaming data and stores them in MongoDB for future use. MongoDB was chosen because of the JSON format of the data.
Finally, the text of the tweets, as well as simple statistics are presented in an interactive Dash dashboard that works with live updates.
The kafkaTwitterStreaming.py script implements the twitter producer. The kafkaMongoConsumer.py implements the MongoDB consumer. Finally, the DashboardFinal.py script connects to the Mongo database and presents live results on a simple web dashboard.
The following steps should be followed in order to run the code:
- Install and configure Apache Kafka.
- Install and configure MongoDB.
- Install and configure Python 3.
- Start zookeeper on one terminal.
- Start kafka on another.
- Create a kafka topic with desired number of partitions and other configurations.
- Start mongo on a third terminal.
- Run the mongodb consumer on one console, specifying the name of the topic you created, on the script.
- Run the twitter stream producer on a second console, after specifying the desired keyword list to fetch tweets by in the script. At this point, the tweets should be streaming from twitter into the Kafka topic and subsequently getting stored into MongoDB.
- Run the dashboard script. The results should be showing on an interactive webpage.