This project enables users to upload PDF files, extract their content, and interact with the extracted data via a conversational interface powered by Google Generative AI (Gemini) and LangChain. Using Streamlit, this application allows you to ask questions about the contents of PDF documents, and it will generate detailed answers based on the PDF text.
Follow these steps to install and run the project:
-
Clone the repository:
git clone https://github.com/Rahul-404/Chat_With_Multiple_PDF_Using_LangChain_And_LLMs.git cd Chat_With_Multiple_PDF_Using_LangChain_And_LLMs -
Create and activate a virtual environment (recommended):
python -m venv venv source venv/bin/activate # On Windows: venv\Scripts\activate
-
Install dependencies:
pip install -r requirements.txt
-
Set up environment variables:
Ensure you have a
.envfile with the following content:GOOGLE_API_KEY=your_google_api_key_hereReplace
your_google_api_key_herewith your actual Google API key. You can obtain the key by visiting the Google AI Studio and enabling the Get API key.
The project is organized as follows:
Chat_With_Multiple_PDF_Using_LangChain_And_LLMs/
│
├── app.py # Streamlit frontend (User interface for interacting with PDFs)
├── logger.py # Logging utility
├── exception.py # Custom exceptions
├── requirements.txt # Python dependencies
├── .env # Environment variables (GOOGLE_API_KEY)
└── README.md # Project documentation
app.py: This file is the Streamlit-based frontend that allows users to upload PDFs, interact with the extracted data, and ask questions.logger.py: Contains logging utilities for debugging and tracking the application's execution.exception.py: Custom exceptions for error handling throughout the app.
Once the dependencies are installed, you can start the Streamlit-based app by running:
streamlit run app.pyThis will launch the app in your browser (usually at http://localhost:8501), where you can interact with the PDF files.
- PDF Upload and Text Extraction: Upload PDF files through the sidebar. The text content will be extracted using the PyMuPDF library.
- Text Chunking: Large documents are chunked into smaller parts to make it easier for the model to process.
- Google Generative AI (Gemini) for Conversational AI: Uses the Gemini model for answering questions based on the extracted PDF content.
- Embeddings and Vector Store: Converts the extracted text into embeddings using Google Generative AI Embeddings and stores the vectors in a FAISS index for fast similarity search.
- Question-Answering: Users can input questions related to the uploaded PDFs, and the app will generate detailed answers based on the context.
-
Upload a PDF:
- Go to the sidebar and click on the "Upload your PDF Files" button.
- Select the PDF file you want to interact with.
-
Submit and Process the PDF:
- After uploading the PDF, click on Submit & Process. The app will extract the text, chunk it, and generate embeddings using the Google Generative AI model.
-
Ask Questions:
- Once the PDF is processed, go to the main input area and type your question regarding the contents of the PDF.
- The app will use a Conversational Chain to process your question and generate an answer based on the context of the uploaded document.
-
View the Answer:
- The answer generated by the model will be displayed below the question input field.
- PDF Text Extraction: The
get_pdf_text()function uses thePyMuPDFlibrary (fitz) to read and extract text from each page of the PDF document. - Text Chunking: Large documents are split into smaller chunks using the
RecursiveCharacterTextSplitterfrom LangChain. - Embeddings Generation: Text chunks are converted into embeddings using Google Generative AI embeddings.
- Similarity Search: When a user asks a question, a similarity search is performed using the FAISS index to retrieve relevant context.
- Question Answering: The
get_conversational_chain()function sets up a prompt and uses Google Generative AI (Gemini) to answer the user's question based on the retrieved context.
- Logging: Logs are created for each step of the process (text extraction, chunking, embedding, question answering) for easier debugging and tracking.
- Error Handling: Custom exceptions are used throughout the app for better error handling. In case of an error, the system logs the exception and raises a custom exception for more details.
To understand how this project works, watch the demo video below, which walks through the entire process of uploading a PDF, processing it, and interacting with the extracted content.
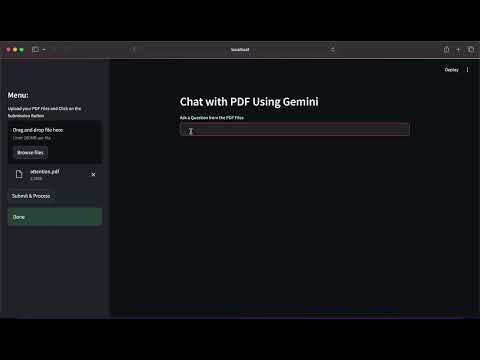
In this video, you'll see:
- How to upload a PDF and process it
- How the app extracts and chunks text from the document
- How users can ask questions and get answers based on the PDF content
We welcome contributions! If you'd like to contribute to this project, please follow these steps:
- Fork the repository.
- Clone your fork to your local machine.
- Create a new branch for your feature or bugfix.
- Make your changes and test them locally.
- Push your changes to your fork.
- Open a pull request with a clear description of your changes.
This project is licensed under the MIT License. See the LICENSE file for more information.