From f46eceeb47a19a20172342baaefef17b4ab7d038 Mon Sep 17 00:00:00 2001
From: katjacksonWB <144173614+katjacksonWB@users.noreply.github.com>
Date: Thu, 25 Jul 2024 11:06:21 -0500
Subject: [PATCH] Adds new artifacts colab. (#526)
* Adds new artifacts colab.
* Finishes all the runs in the notebook.
* Adds new section.
* Adds a new section.
* Update colabs/artifact_basics/Artifact_Basics.ipynb
Co-authored-by: Noa <40642416+noaleetz@users.noreply.github.com>
* Added more specific text.
* Update colabs/artifact_basics/Artifact_Basics.ipynb
Co-authored-by: Noa <40642416+noaleetz@users.noreply.github.com>
* New header.
* Lineage changes.
* Update colabs/artifact_basics/Artifact_Basics.ipynb
Co-authored-by: Noa <40642416+noaleetz@users.noreply.github.com>
* Update colabs/artifact_basics/Artifact_Basics.ipynb
Co-authored-by: Noa <40642416+noaleetz@users.noreply.github.com>
* More contextual links.
* Technical changes.
* Grammar and technical corrections.
* Additional section.
* Code corrections.
* Updates to metadata section.
* Code edits.
* Addtional edits.
* New Artifact version section.
* addressing outstanding issues with the new basic Artifacts colab
* making the artifact-basics.ipynb colab environment agnostic
* removing output from the artifact-basics.ipynb colab
* Added Pandas import, removed extra img tags (#548)
* Fixed typo
* Renamed notebook
* clean up
---------
Co-authored-by: Noa <40642416+noaleetz@users.noreply.github.com>
Co-authored-by: Ryan McConville <ryan.mcconville@wandb.com>
Co-authored-by: Noah Luna <15202580+ngrayluna@users.noreply.github.com>
Co-authored-by: Thomas Capelle <tcapelle@pm.me>
---
.../Artifact_fundamentals.ipynb | 429 ++++++++++++++++++
1 file changed, 429 insertions(+)
create mode 100644 colabs/wandb-artifacts/Artifact_fundamentals.ipynb
diff --git a/colabs/wandb-artifacts/Artifact_fundamentals.ipynb b/colabs/wandb-artifacts/Artifact_fundamentals.ipynb
new file mode 100644
index 00000000..da426a18
--- /dev/null
+++ b/colabs/wandb-artifacts/Artifact_fundamentals.ipynb
@@ -0,0 +1,429 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<a href=\"https://colab.research.google.com/github/wandb/examples/blob/master/colabs/wandb-artifacts/Artifact_fundamentals.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>\n",
+ "<!--- @wandbcode{artifacts-fundamentals} -->"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "<img src=\"http://wandb.me/logo-im-png\" width=\"400\" alt=\"Weights & Biases\" />\n",
+ "\n",
+ "<!--- @wandbcode{artifacts-fundamentals} -->\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Use [Weights & Biases](https://wandb.com) for machine learning experiment tracking, dataset and model versioning and management, collaboration and more.\n",
+ "\n",
+ "<div><img /></div>\n",
+ "\n",
+ "<img src=\"https://wandb.me/mini-diagram\" width=\"650\" alt=\"Weights & Biases\" />\n",
+ "\n",
+ "<div><img /></div>\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "\n",
+ "Use W&B Artifacts to track and version data as the inputs and outputs of your W&B Runs. In addition to logging hyperparameters, metadata, and metrics to a run, you can use an artifact to log the dataset used to train the model as input and the resulting model checkpoints as outputs.\n",
+ "\n",
+ ""
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Set Up"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In order to use Weights & Biases, you will need the `wandb` package installed. You can install it as follows within Colab."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "!pip install wandb"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Once it is installed, the next step is to import it into your script or notebook with `import wandb`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import wandb"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "We also need to authenticate to the Weights & Biases server. There are various ways of doing this, including for [remote or non-interactice workflows](https://docs.wandb.ai/guides/track/environment-variables), but given this is running interactively, we can use `wandb.login()`.\n",
+ "\n",
+ "If we are not already authenticated, a link will appear which you can use to do so."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "wandb.login()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Create a Dataset\n",
+ "Let's create some datasets that we can work with in this example."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import numpy as np\n",
+ "import csv\n",
+ "\n",
+ "directory = \"dataset\"\n",
+ "os.makedirs(directory, exist_ok=True)\n",
+ "file1, file2 = os.path.join(directory, \"file1.csv\"), os.path.join(directory, \"file2.csv\")\n",
+ "\n",
+ "def generate_dummy_data(num_samples):\n",
+ " data = [\n",
+ " np.random.normal(50, 10, num_samples),\n",
+ " np.random.randint(1, 100, num_samples),\n",
+ " np.random.choice(['A', 'B', 'C', 'D'], num_samples),\n",
+ " np.random.uniform(0.0, 1.0, num_samples)\n",
+ " ]\n",
+ " return zip(*data)\n",
+ "\n",
+ "def save_to_csv(file, data):\n",
+ " with open(file, 'w', newline='') as f:\n",
+ " writer = csv.writer(f)\n",
+ " writer.writerow(['feature1', 'feature2', 'feature3', 'feature4'])\n",
+ " writer.writerows(data)\n",
+ "\n",
+ "num_samples = 100\n",
+ "save_to_csv(file1, generate_dummy_data(num_samples))\n",
+ "save_to_csv(file2, generate_dummy_data(num_samples))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Create An Artifact"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "The general workflow for creating an Artifact is:\n",
+ "\n",
+ "\n",
+ "1. Intialize a run.\n",
+ "2. Create an Artifact.\n",
+ "3. Add a any files or directories to the new Artifact that you want to track and version.\n",
+ "4. Log the artifact in the W&B platform.\n",
+ "\n",
+ "The most straightforward way of accomplishing this is the second line of code in the example below, which will log, track and version a new dataset (i.e. do points 2, 3, and 4 above in one step)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "run.log_artifact(artifact_or_path=f\"{directory}/file1.csv\", name=\"my_first_artifact\", type=\"dataset\")\n",
+ "run.finish()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the above example we first initalize a run using [`wandb.init()`](https://docs.wandb.ai/ref/python/init) the `artifact-basics` project. If this project doesn't exist, it will be created. If it alreadt exists, a new W&B Run will be added to it.\n",
+ "\n",
+ "\n",
+ "In the second line we actually log the Artifact with [`run.log_artifact()`](https://docs.wandb.ai/ref/python/public-api/run#log_artifact). In this example, we use three common arguments to the function.\n",
+ "1. With `artifact_or_path` we specifiy the path to where the data we want to version exists. Any file or directory can be added here.\n",
+ "2. with `name` we give the artifact a name within Weights & Biases that we will use to access it.\n",
+ "3. With `type` we give the artifact a higher level grouping. For example, we may have multiple artifacts of type data, and multiple artifacts of type model.\n",
+ "\n",
+ "\n",
+ "See the [Artifacts Reference](https://docs.wandb.ai/ref/python/artifact) guide for more information and other commonly used arguments, including how to store additional metadata.\n",
+ "\n",
+ "Each time the above `log_artifact` is executed, wandb will create a new version of the Artifact within Weights & Biases if the underlying data has changed.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "An alternative approach that offers more control (at the expense of more lines of code) can be seen below."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "\n",
+ "artifact = wandb.Artifact(\"my_first_artifact\", type=\"dataset\")\n",
+ "# the below will add two individual files to the artifact.\n",
+ "artifact.add_file(local_path=f\"{directory}/file1.csv\")\n",
+ "artifact.add_file(local_path=f\"{directory}/file2.csv\")\n",
+ "# or the below if you wanted to add the entire directory contents.\n",
+ "artifact.add_dir(local_path=f\"{directory}\")\n",
+ "# explictly log the artifact to Weights & Biases.\n",
+ "run.log_artifact(artifact)\n",
+ "\n",
+ "wandb.finish()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "In the above example, lines 3-5 will create a new Artifact within your Weights & Biases project. With the resulting artifact object, you can call the [`artifact.add_file`](https://docs.wandb.ai/ref/python/artifact#add_file) or [`artifact.add_dir`](https://docs.wandb.ai/ref/python/artifact#add_dir) functions in order to add as many files and directories to the Artifact as you want. Once added, the artifact must then be explictly logged to Weights & Biases."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Use an Artifact"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "When you want to use a specific version of an Artifact in a downstream task, you can specify the specific version you would like to use via either `v0`, `v1`, `v2` and so on, or via specific aliases you may have added. The `latest` alias always refers to the most recent version of the Artifact logged.\n",
+ "\n",
+ "The proceeding code snippet specifies that the W&B Run will use an artifact called `my_first_artifact` with the alias `latest`:\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "artifact = run.use_artifact(artifact_or_name=\"my_first_artifact:latest\") # this creates a reference within Weights & Biases that this artifact was used by this run.\n",
+ "path = artifact.download() # this downloads the artifact from Weights & Biases to your local system where the code is executing.\n",
+ "print(f\"Data directory located at {path}\")\n",
+ "run.finish()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "For more information on ways to customize your Artifact download, including via the command line, see the [Download and Usage guide](https://docs.wandb.ai/guides/artifacts/download-and-use-an-artifact)."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Create a new Artifact version"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Let's say we want to modify our dataset while also tracking and versioning these changes. In the below example we will subsample our dataset and save it as a new file. We will use the [Pandas](https://pandas.pydata.org/pandas-docs/stable/index.html) library to read our CSV file.\n",
+ "\n",
+ "In the second block of code we will log it to Weights & Biases under the same Artifact name (*my_first_artifact*) so that Weights & Biases knows that this is a new version of an existing artifact."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import pandas\n",
+ "df = pandas.read_csv(f\"{directory}/file1.csv\")\n",
+ "# subsample to 50% of the original size\n",
+ "df_subsampled = df.sample(frac=0.5, random_state=1)\n",
+ "# save the subsampled dataframe to a new file.\n",
+ "df_subsampled.to_csv(f\"{directory}/file1.csv\", index=False)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now we have a new subsampled version of our dataset locally, we can log the new version to Weights & Biases."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "run.log_artifact(artifact_or_path=f\"{directory}/file1.csv\", name=\"my_first_artifact\", type=\"dataset\", aliases =[\"subsampled\"])\n",
+ "run.finish()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Now the sampled dataset will be logged to the `my_first_artifact` Artifact as a new version.\n",
+ "\n",
+ "The Artifact has also been given a custom `alias`, which is a unique label for this Artifact version. While the `alias` is currently `subsampled`, the default aliases is `vN`, where `N` is the number of versions the Artifact has. This increments automatically. You can always access specific versions of an Artifact by using an alias."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Update Artifact version metadata"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can update the `description`, `metadata`, and `alias` of an artifact on the W&B platform during or outside a W&B Run.\n",
+ "\n",
+ "\n",
+ "This example changes the `description` of the `my_first_artifact` artifact inside a run:"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "artifact = run.use_artifact(artifact_or_name=\"my_first_artifact:subsampled\")\n",
+ "artifact.description = \"This is an edited description.\"\n",
+ "artifact.metadata = {\"source\": \"local disk\", \"internal data owner\": \"platform team\"}\n",
+ "artifact.save() # persists changes to an Artifact's properties\n",
+ "run.finish()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Use the Artifact within your pipelines\n",
+ "Once the artifact is tracked and versioned within Weights & Biases it's now easy to integrate it into your ML workflows."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "run = wandb.init(project=\"artifact-basics\")\n",
+ "artifact = run.use_artifact(artifact_or_name=\"my_first_artifact:latest\")\n",
+ "# the below is left as an exercise to the reader\n",
+ "# train model\n",
+ "# log model as artifact\n",
+ "run.finish()\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Navigate the Artifacts UI"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "You can also manage your Artifacts via the W&B platform. This can give you insight into your model's performance or dataset versioning. To navigate to the relevant information, click this [link](https://wandb.ai/wandb/artifact-basics/overview), then click on the **Artifacts** tab.\n",
+ "\n",
+ "Navigating to the **Lineage** section in the tab will show the dependency graph formed by calling `run.use_artifact()` when an Artifact is an input to a run, and `run.log_artifact()` when an Artifact is output to a run. This helps visualize the relationship between different model versions and other objects like datasets and jobs in your project. Click [this](https://wandb.ai/wandb/artifact-basics/artifacts/dataset/my_first_artifact/v0/lineage) link to navigate to the project's lineage page."
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "Naturally, as you integrate W&B Artifacts into your workflow, lineage graphs such as [this interactive example](https://wandb.ai/wandb-smle/artifact_workflow/artifacts/model/quant_model/v16/lineage) will be built up over time, giving you reproducibility, governance, and auditability.\n",
+ "\n",
+ "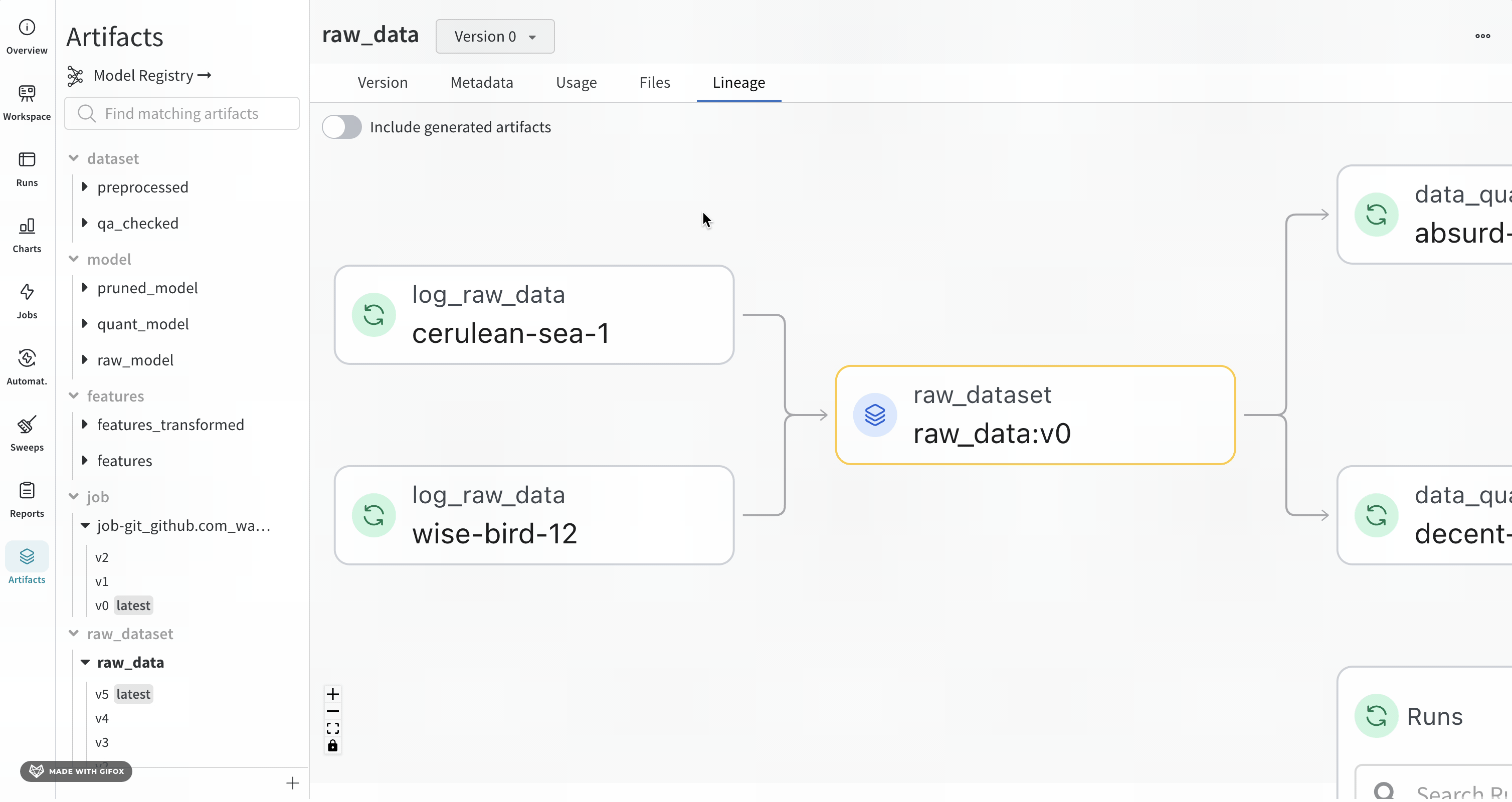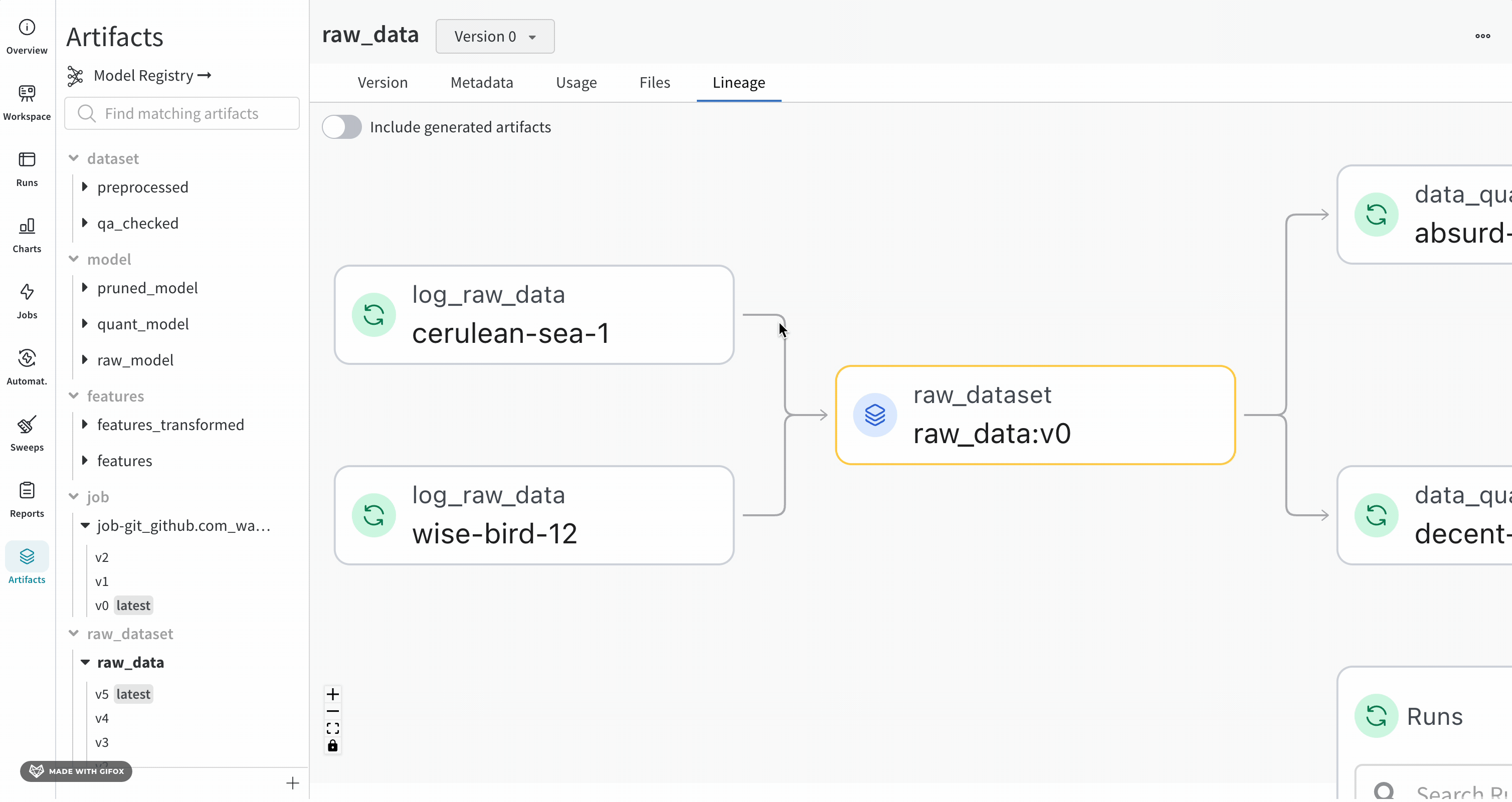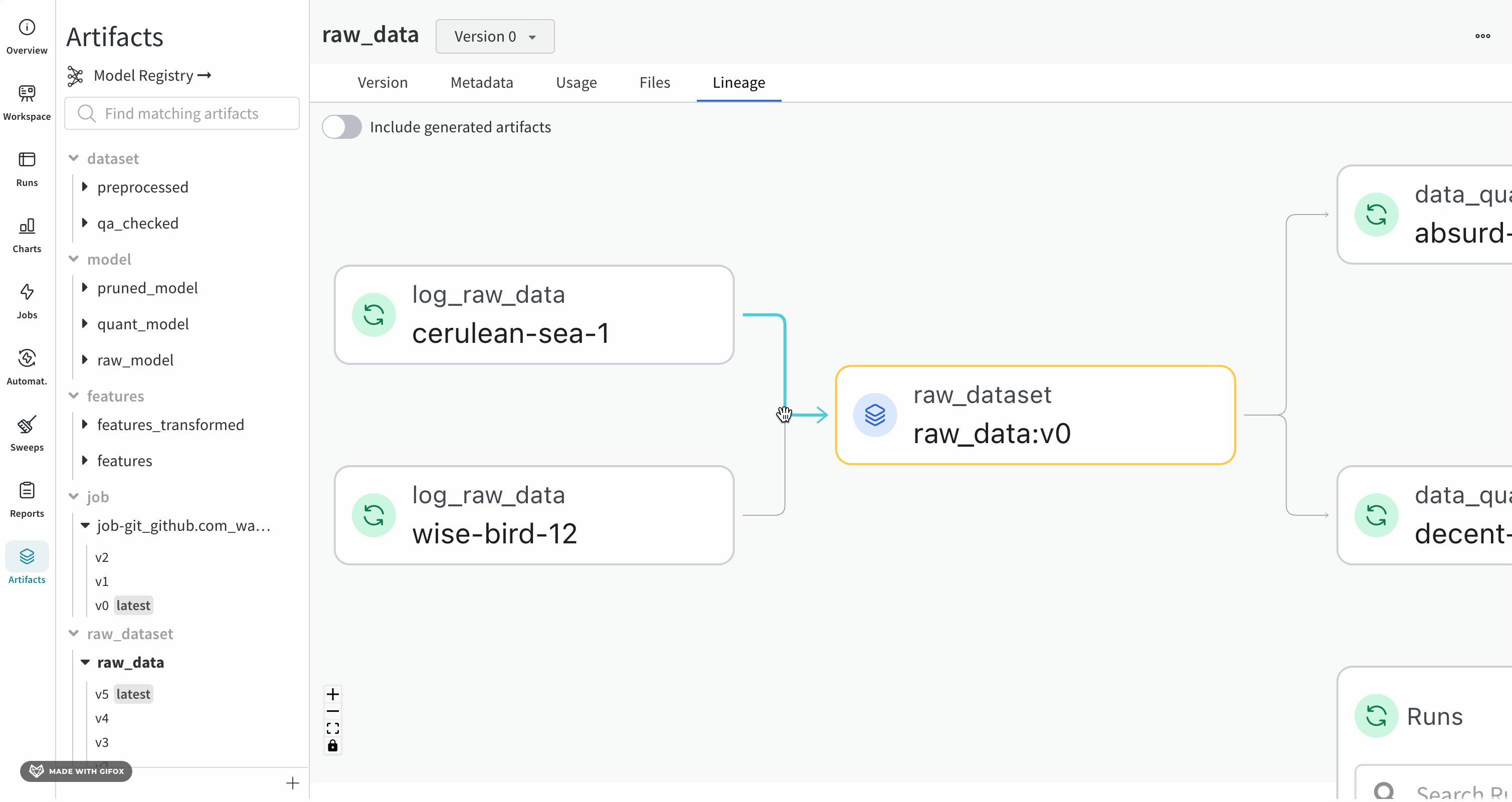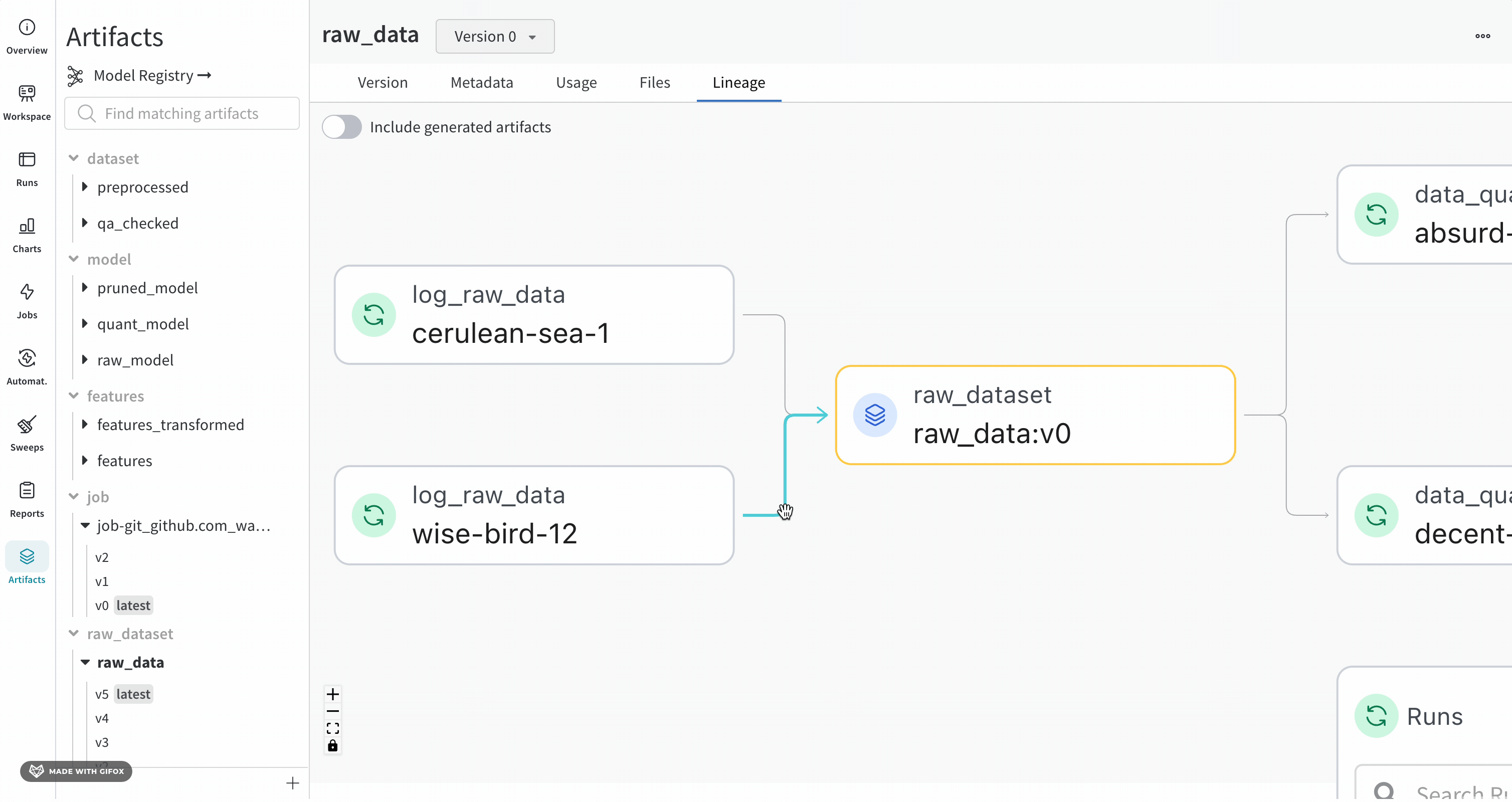\n",
+ "\n",
+ "\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Next steps\n",
+ "1. [Artifacts Python reference documentation](https://docs.wandb.ai/ref/python/artifact): Deep dive into artifact parameters and advanced methods.\n",
+ "2. [Lineage](https://docs.wandb.ai/guides/artifacts/explore-and-traverse-an-artifact-graph): View lineage graphs, which are automatically built when using W&B artifact system, providing an auditable visual overview of the relationships between specific artifact versions, datasets models and runs.\n",
+ "3. [Model Registry](https://docs.wandb.ai/guides/model_registry): Learn how to centralize your best artifact versions in a shared registry.\n",
+ "4. [Artifact Automations](https://docs.wandb.ai/guides/artifacts/project-scoped-automations): Automatically run specific Weights & Biases jobs based on changes to your artifacts, such as automatically training a new model each time a new version of the training data is logged.\n",
+ "5. [Reference Artifacts](https://docs.wandb.ai/guides/artifacts/track-external-files#download-a-reference-artifact): Track files saved outside the W&B server, like Amazon S3 buckets, GCS buckets, Azure blobs, and more."
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "include_colab_link": true,
+ "provenance": [],
+ "toc_visible": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 4
+}