pypdfocr error [ValueError: invalid literal for int() with base 10: ''] in '\pypdfocr_pdf", line 98, in overlay_hocr' #9
Assignees

Comments
|
Looks like I have issues with filenames that are just numbers. I'll have to change some internal temporary file naming to fix this. In the meantime, if you add some letters to your filename, it should work fine. |
|
Fixed in 0.6.1 |
|
I see the same issue in the latest version. Any idea?
|

|
@farrukhdGB , I know you asked about a year ago but for posterity: Edit: it's a reference to Issue #61. |
|
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
win7 x64 / pypdfocr-0.6 / ghostscript-9.10 / tesseract-3.02
Fail on all pdf files...
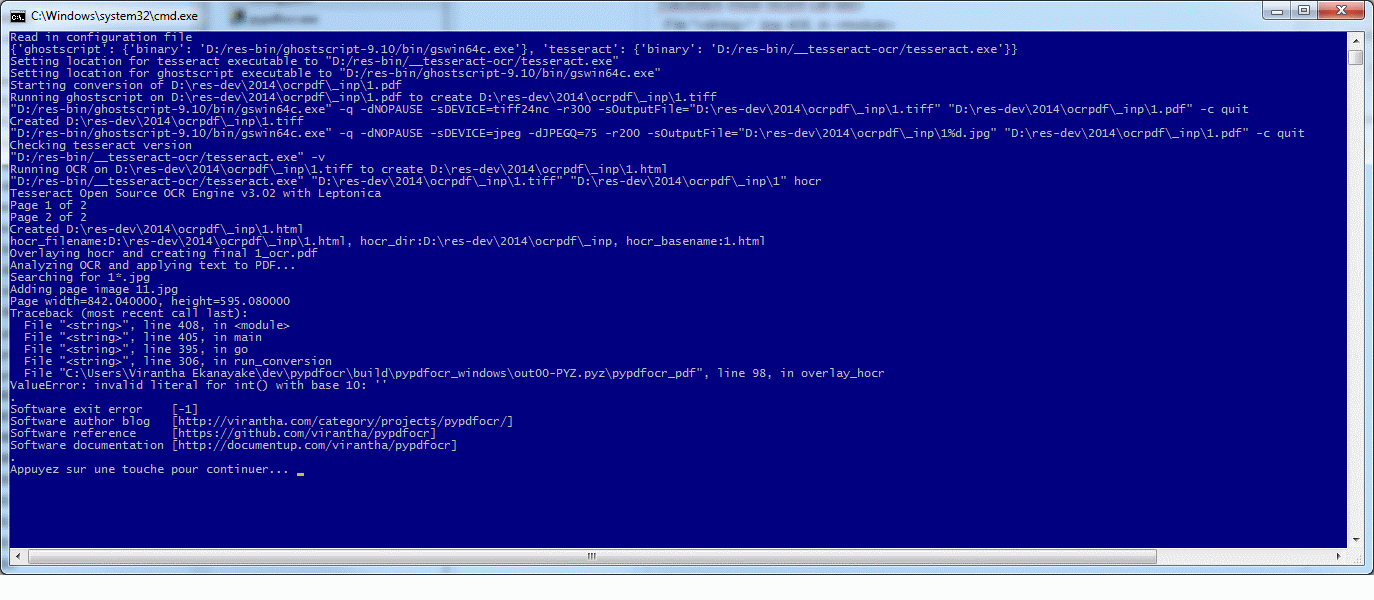
Read in configuration file
file 'pypdfocr_pdf.py' [ line 98 : 'pg_num = int(jpg_file.split(basename)[1].split('.')[0])' ]{'ghostscript': {'binary': 'D:/res-bin/ghostscript-9.10/bin/gswin64c.exe'}, 'tesseract': {'binary': 'D:/res-bin/__tesseract-ocr/tesseract.exe'}}
Setting location for tesseract executable to "D:/res-bin/__tesseract-ocr/tesseract.exe"
Setting location for ghostscript executable to "D:/res-bin/ghostscript-9.10/bin/gswin64c.exe"
Starting conversion of D:\res-dev\2014\ocrpdf_inp\1.pdf
Running ghostscript on D:\res-dev\2014\ocrpdf_inp\1.pdf to create D:\res-dev\2014\ocrpdf_inp\1.tiff
"D:/res-bin/ghostscript-9.10/bin/gswin64c.exe" -q -dNOPAUSE -sDEVICE=tiff24nc -r300 -sOutputFile="D:\res-dev\2014\ocrpdf_inp\1.tiff" "D:\res-dev\2014\ocrpdf_inp\1.pdf" -c quit
Created D:\res-dev\2014\ocrpdf_inp\1.tiff
"D:/res-bin/ghostscript-9.10/bin/gswin64c.exe" -q -dNOPAUSE -sDEVICE=jpeg -dJPEGQ=75 -r200 -sOutputFile="D:\res-dev\2014\ocrpdf_inp\1%d.jpg" "D:\res-dev\2014\ocrpdf_inp\1.pdf" -c quit
Checking tesseract version
"D:/res-bin/__tesseract-ocr/tesseract.exe" -v
Running OCR on D:\res-dev\2014\ocrpdf_inp\1.tiff to create D:\res-dev\2014\ocrpdf_inp\1.html
"D:/res-bin/__tesseract-ocr/tesseract.exe" "D:\res-dev\2014\ocrpdf_inp\1.tiff" "D:\res-dev\2014\ocrpdf_inp\1" hocr
Tesseract Open Source OCR Engine v3.02 with Leptonica
Page 1 of 2
Page 2 of 2
Created D:\res-dev\2014\ocrpdf_inp\1.html
hocr_filename:D:\res-dev\2014\ocrpdf_inp\1.html, hocr_dir:D:\res-dev\2014\ocrpdf_inp, hocr_basename:1.html
Overlaying hocr and creating final 1_ocr.pdf
Analyzing OCR and applying text to PDF...
Searching for 1*.jpg
Adding page image 11.jpg
Page width=842.040000, height=595.080000
Traceback (most recent call last):
File "", line 408, in
File "", line 405, in main
File "", line 395, in go
File "", line 306, in run_conversion
File "C:\Users\Virantha Ekanayake\dev\pypdfocr\build\pypdfocr_windows\out00-PYZ.pyz\pypdfocr_pdf", line 98, in overlay_hocr
ValueError: invalid literal for int() with base 10: ''
file 'config.yaml'
[
tesseract:
binary: D:/res-bin/__tesseract-ocr/tesseract.exe
ghostscript:
binary: D:/res-bin/ghostscript-9.10/bin/gswin64c.exe
]
The text was updated successfully, but these errors were encountered: