Computational Vision - the process of discovering from images what is present in the world and where. It is challenging because it tries to recover lost information when reversing the imaging process (imperfect imaging process, discretized continuous world)
Applications:
- Automated navigation with obstacle avoidance
- Scene recognition and target detection
- Document processing
- Human computer interfaces
Captured photons release energy which is used as electrical signals for us to see. A photocell in its membrane has ion channels through which ions can flow out. As the light interacts with cell's rhodopsins (type of receptor), the ion channels close and a build-up of electrons occurs in the cell. Such negative charge is captured as an electrical signal by the nerve.
Rod cells (120m) are responsible for vision at low light levees, cones (6m) are active at higher levels and are capable of color vision and have high spatial acuity. There's a 1-1 relationship of cones and neurons so we are able to resolve better, meanwhile many rods converge to one neuron.
Pupils dilate to accept as much light as needed to see clearly.
Receptive field - area on which light must fall for neuron to be stimulated. A receptive field of a Ganglion cell is formed from all photoreceptors that synapse with it.
Ganglion cells - photocells located in retina that process visual information that begins as light entering the eye and transmit it to the brain. There are 2 types of them.
- On-center - fire when light is on center
- Off-center - fire when light is somewhere around center
Ganglion cells allow transition of information about contrast. The size of the receptive field controls the spatial frequency information (e.g., small ones are stimulated by high frequencies for fine detail). Ganglion cells don't work binary (fire/not fire), the change the firing rate when there's light.
Trichromatic coding - any color can be reproduced using 3 primary colors (red, blue, green).
Retina contains only 8% of blue cones and equal proportion of red and green ones - they allow to discriminate colors
2nmin difference and allow to match multiple wavelengths to a single color (does not include blending though)
Wave frequency Hz) and energy J) can be calculated as follows (
Perceivable electromagnetic radiation wavelengths are within
380to760nm
Law of Geometric Optics:
- Light travels in straight lines
- Ray, its reflection and the normal are coplanar
- Ray is refracted when it transits medium
Snell's Law - wave crests cannot be created or destroyed at the interface, so to make the waves match up, the light has to change the direction. I.e., given refraction indices

Focal length m) - distance from lens to the point D) (~59D for human eye)

If the image plane is curved (e.g., back of an eye), then as the angle from optical center to real world object
$\tan\theta=\frac{h}{u}=\frac{h'}{v}$ gets larger (when it gets closer to the lens), it is approximated worse.
Intensity image - a matrix whose values correspond to pixels with intensities within some range. (imagesc in matlab displays intensity image).
Colormap - a matrix which maps every pixel to usually (most popular are RGB maps) 3 values to represent a single color. They're averaged to convert it to intensity value.
Image - a function x and y directions - this is captured by the gradien of intensity Jacobian vector:
Such gradient has x and y component, thus it has magnitude and direction:
Edge detection is useful for feature extraction for recognition algorithms
Edge descriptors:
- Edge direction - perpendicular to the direction of the highest change in intensity (to edge normal)
- Edge strength - contrast along the normal
- Edge position - image position where the edge is located
Edge detection steps:
- Smoothening - remove noise
- Enhancement - apply differentiation
- Thresholding - determine how intense are edges
- Localization - determine edge location
Optimal edge detection criteria:
- Detecting - minimize false positives and false negatives
- Localizing - detected edges should be close to true edges
- Single responding - minimize local maxima around the true edge
To approximate the gradient at the center point of 2-by-2 pixel area, for change in x - we sum the differences between values in rows; for change in y - the differences between column values. We can achieve the same by summing weighted pixels with horizontal and vertical weight matrices (by applying cross-correlation):
There are other ways to approximate the gradient (not necessarily at 2-by-2 regions): Roberts and Sobel (very popular):
After applying filters to compute the gradient matrices 2 to get the final output:
Note that given an intensity image
$$(I\otimes K){h,w}=\sum{n=-N}^N\sum_{m=-M}^MI_{h+n,w+m}K_{N+n,M+m}$$
We usually set a threshold for calculated gradient map to distinguish where the edge is. We may also upsample the image to enhance the features.
If we use noise smoothing filter, instead of looking for an image gradient after applying the noise filter, we can take the derivative of the noise filter and then convolve it (because mathematically it's the same):
We can apply Laplacian Operator - by applying the second derivative we can identify where the rate of change in intensity crosses
0, which shows exact edge.
Laplacian - sum of second order derivatives (dot product):
For a finite difference approximation, we need a filter that is at least the size of 3-by-3. For change in x, we take the difference between the differences involving the center and adjacent pixels for that row, for change in y - involving center and adjacent pixels in that column. I. e., in 3-by-3 case:
$$(\nabla_{x^2}^2I){h,w}=(I{h,w+1}-I_{h,w}) - (I_{h,w} - I_{h,w-1})=I_{h,w-1}-2I_{h,w}+I_{h,w+1}$$
$$(\nabla_{y^2}^2I){h,w}=I{h-1,w}-2I_{h,w}+I_{h+1,w}$$
We just add the double derivative matrices together to get a final output. Again, we can calculate weights for these easily to represent the whole process as a cross-correlation (a more popular one is the one that accounts for diagonal edges):
We use a uniform filter (e.g., in 3-by-3 case all filter values are
Laplacian of Gaussian - Laplacian + Gaussian which smoothens the image (necessary before Laplacian operation) with Gaussian filter and calculates the edge with Laplacian Operator
Note the noise suppression-localization tradeoff: larger mask size reduces noise but adds uncertainty to edge location. Also note that the smoothness for Gaussian filters depends on
Canny has shown that the first derivative of the Gaussian provides an operator that optimizes signal-to-noise ratio and localization
Algorithm:
- Compute the image gradients
$\nabla_x f = f * \nabla_xG$ and$\nabla_y f = f * \nabla_yG$ where$G$ is the Gaussian function of which the kernels can be found by:$\nabla_xG(x, y)=-\frac{x}{\sigma^2}G(x, y)$ $\nabla_yG(x, y)=-\frac{y}{\sigma^2}G(x, y)$
- Compute image gradient magnitude and direction
- Apply non-maxima suppression
- Apply hysteresis thresholding
Non-maxima suppression - checking if gradient magnitude at a pixel location along the gradient direction (edge normal) is local maximum and setting to 0 if it is not
Hysteresis thresholding - a method that uses 2 threshold values, one for certain edges and one for certain non-edges (usually
For edge linking high thresholding is used to start curves and low to continue them. Edge direction is also utilized.
SIFT - an algorithm to detect and match the local features (should be invariant) in images. Invariance Types (and how to achieve them):
- Illumination - luminosity changes (solved by difference-based metrics)
- Scale - image size change, magnification change (solved by pyramids, scale space)
- Rotation - roll change along the
xaxis (solved by rotating to the most dominant gradient direction) - Affine - generalization of rotation, scaling, stretching etc (solved by normalizing through eigenvectors)
- Perspective - changes in view perspective (solved by rigid transform)
Pyramids - average pooling with stride
2multiple times
Scale Space - apply Pyramids but take DOGs (Differences of Gaussians) in between and keep features that are repeatedly persistent
By analyzing motion in the images, we look at part of the anatomy and see how it changes from subject to subject (e.g., through treatment). This can also be applied to tracking (e.g., monitor where people walk).
Optical flow - measurement of motion (direction and speed) at every pixel between 2 images to see how they change over time. Used in video mosaics (matching features between frames) and video compression (storing only moving information)
There are 4 options of dynamic nature of the vision:
- Static camera, static objects
- Static camera, moving objects
- Moving camera, static objects
- Moving camera, moving objects
Difference Picture - a simplistic approach for identifying a feature in the image
We also need to clean up the noise - pixels that are not part of a larger image . We use connectedness (more info at 1:05):
2pixels are both called 4-neighbors if they share an edge2pixels are both called 8-neighbors if they share an edge or a corner2pixels are4-connected if a path of 4-neighbors can be created from one to another2pixels are8-connected if a path of 8-neighbors can be created from one to another

Aperture problem - a pattern which appears to be moving in one direction but could be moving in other directions due to only seeing the local features movement. To solve this, we use Motion Correspondence (matching).
Motion Correspondence - finding a set of interesting features and matching them from one image to another (guided by 3 principles/measures):
- Discreteness - distinctiveness of individual points (easily identifiable features)
- Similarity - how closely
2points resemble one another (nearby features also have similar motion) - Consistency - how well a match conforms with other matches (moving points have a consistent motion measured by similarity)
Most popular features are corners, detected by Moravec Operator (paper) (doesn't work on small objects). A mask is placed over a region and moved in 8 directions to calculate intensity changes (with the biggest changes indicating a potential corner)
Algorithm of Motion Correspondence:
- Pair one image's points of interest with another image's within some distance
- Calculate degree of similarity for each match and the likelihood
- Revise likelihood using nearby matches
Degree of similarity 2 patches
A point can be represented as a coordinate (Cartesian space) or as a point from the origin at some angle (Polar space). It has many lines going through and each line can be described as a vector by angle and magnitude
Hough Space - a plane defined by
Hough Transform - picking the "most voted" intersections of lines in the Hough Space which represent line in the image space passing through the original points (sinusoids in Hough Space)
Algorithm:
- Create
$\theta$ and$w$ for all possible lines and initialize0-matrix$A$ indexed by$\theta$ and$w$ - For each point
$(x, y)$ and its every angle$\theta$ calculate$w$ and add vote at$A[\theta, w]+=1$ - Return a line where
$A>\text{Threshold}$
There are generalized versions for ellipses, circles etc. (change equation
$w$ ). We also still need to suppress non-local maxima
Image Registration - geometric and photometric alignment of one image to another. It is a process of estimating an optimal transformation between 2 images.
Image registration cases:
- Individual - align new with past image (e.g, rash and no rash) for progress inspection; align similar sort images (e.g., MRI and CT) for data fusion.
- Groups - many-to-many alignment (e.g., patients and normals) for statistical variation; many-to-one alignment (e.g., thousands of subjects with different sorts) for data fusion
Image Registration problem can be expressed as finding transformation
$$\mathbf{p}^=\operatorname{argmin}\mathbf{p} \sum{k=1}^K\underbrace{\text{sim}\left(I(x_k), J(T_{\mathbf{p}}(x_k))\right)}_{{\text{similarity function}}}$$
We may want to match landmarks (control points), pixel values, feature maps or a mix of those.
Transformations include affine, rigid, spline etc. Most popular:
- Rigid - composed of
3rotations and3translations (so no distortion). Transforms are linear and can be4x4matrices (1 translation and 3 rotation). - Affine - composed of
3rotations,3translations,3scales and3shears. Transforms are also linear and can be represented as4x4matrices - Piecewise Affine - same as affine except applied to different components (local zones) of the image, i.e., a piecewise transform of
2images. - Non-rigid (Elastic) - transforming via
2forces - external (deformation) and internal (constraints) - every pixel moves by different amount (non-linear).
Conservation of Intensity - pixel-wise MSE/SSD. If resolution is different, we have to interpolate missing values which results in poor similarity
Mutual Information - maximize the clustering of the Joint Histogram (maximize information which is mutual between 2 images):
- Image Histogram (
hist) - a normalized histogram (y- num pixels,x- intensity) representing a discrete PDF where peaks represent some regions. - Joint Histogram (
histogram2) - same as histogram, except pairs of intensities are counted (x,y- intensities,color- num pixel pairs). Sharp heatmap = high similarity.
Where
Normalized Cross-Correlation - assumes there is a linear relationship between intensity values in the image - the similarity measure is the coefficient (
More details: correlation, normalized correlation, correlation coefficient, covariance vs correlation, correlation as a similarity measure
Image Segmentation - partitioning image to its meaningful regions (e.g., based on measurements on brightness, color, motion etc.). Non-automated segmentation (by hand) require expertise; Automated segmentation (by models) are currently researched
Image representation:
- Dimensionality: 2D (
x,y), 3D (x,y,z), 3D (x,y,t), ND (x,y,z,b2, ...,bn) - Resolution: spatial (pixels/inch), intensity (bits/pixel), time (FPS), spectral (bandwidth)
Image characterization:
- As signals: e.g., frequency distribution, signal-to-noise-ratio
- As objects: e.g., individual cells, parts of anatomy
Segmentation techniques
- Region-based: global (single pixels - thresholding), local (pixel groups - clustering, PCA )
- Boundary-based: gradients (finding contour energy), models (matching shape boundaries)
Thresholding - classifying pixels to "objects" or "background" depending on a threshold
Otsu threshold - calculating variance between 2 objects for exhaustive number of thresholds and selecting the one that maximizes inter-class intensity variance (biggest variation for 2 different objects and minimal variation for 1 object)
Smoothing the image before selecting the threshold also works. Mathematical Morphology techniques can be used to clean up the output of thresholding.
Mathematical Morphology (MM) - technique for the analysis and processing of geometrical structures, mainly based on set theory and topology. It's based on 2 operations - dilation (adding pixels to objects) and erosion (removing pixels from objects).
An operation of MM deals with large set of points (image) and a small set (structuring element). A structuring element is applied as a convolution to touch up the image based on its form.
Applying dilation and erosion multiple times lets to close the holes in segments

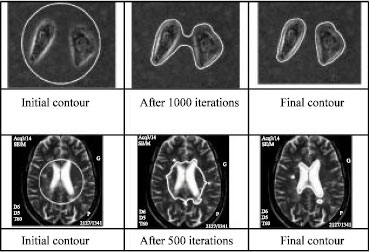
Active Contours - energy minimization problem where we want to find the equilibrium (lowest potential) of the three terms:
-
$(E_{int})$ Internal - sensitivity to the amount of stretch in the curve (smoothness along the curve) -
$(E_{img})$ Image - correspondence to the desired image features, e.g., gradients, edges, colors -
$(E_{ext})$ External - user defined constraints/prior knowledge over the image structure (e.g., starting region)
Energy in the image is some function of the image features; Snake is the object boundary or contour
Watershed Segmentation - classifying pixels to 3 classes based on thresholding: local minima (min value of a region), catchment basin (object region), watershed (object boundary)

For 3D imaging many images are collected to construct a smooth 3D scene. It is used in archeology (sharing discoveries), industrial inspection (verifying product standard), biometrics (recognizing 3D faces vs photos), augmented reality (IKEA app)
3D imaging is useful because it can remove the necessity to process low level features of 2D images: removes effects of directional illumination, segments foreground and background, distinguishes object textures from outlines
Depth - given a line on which the object exists, it is the shortest distance to the line from the point of interest
Passive Imaging - we are concerned with the light that reaches us. 3D information is acquired from a shared field of view (units don't interfere!)
Environment may contain shadows (difficult seeing), reflections (change location of different views = fake correspondences), don't have enough surface features
Surface is observed from multiple viewpoints simultaneously. Unique regions of the scene are found in all pictures (which can differ based on perspective) and the distance to the object is calculated considering the dispersity.
Difficult to find pixel correspondence
Surface is observed from multiple viewpoints sequentially. A single camera is moved around the object and the images are combined to construct an object representation.
If illumination, time of the day, cameras are changing, there is more sparsity
Surface is observed from different focuses based on camera's depth-of-field (which depends on the lens of the camera and the aperture). The changes are continuous. A focal stack can be taken and a depth map can be generated (though quite noisy).
Difficult to get quantitative numbers. Also mainly sharp edges become blurry when camera is not in focus but not everything has sharp edges



Active Imaging - we use the light that we control. It robustly performs dense measurements because little computation is involved, just direct measurements.
Light can be absorbed by dark surfaces and reflected by specular surfaces causing no signal, also multiple units may interfere with each other
Infrared light is used to project surface features and solve the problem of "not enough surface features". Since there is more detail from different viewpoints and since we don't care about patterns (only features themselves), it is easier to find correspondences
Lack of detail produces holes and error depends on distance between cameras. Also, projector brightness decreases with distance therefore things far away cannot be captured.
Distance from the object is found by the time taken for light to travel from camera to the scene. Directional illumination is used to focus photon shooting at just one direction which restricts the view area. Two devices are used:
- Lidar - has a photosensor and a laser pulse on the same axis which is rotated and each measurement is acquired through time. It is robust, however hard to measure short distances due to high speed of light; also is large and expensive.
- Time of flight camera - can image the scene all at once. It uses a spatially resolved sensor which fires light waves instead of pulses and each light wave is recognized by its relative phase. It is fast but depth measure depends on wave properties.
To save hardware resources, a projector and a camera are used at different perspectives (unlike in time of flight where they were on the same diagonal). Projected patterns give more information because they can encode locations onto the surface.
- Point scanner (
1D) - the position and the direction of the laser is checked and it is calculated where the intersection occurs in the image taken by camera. It is slow because for every point there has to be an image. - Laser line scanner (
2D) - a plane is projected which gives information about the curve of the surface. The depth is then calculated for a line of points in a single image. It is faster but not ideal because image is still not measured at once.
This technique is more accurate (especially for small objects), however the field of view is reduced and there is more complexity in imaging and processing time. Useful in industries where object, instead of laser, moves.
It is time-consuming to move one stripe over time, instead multiple stripes can be used to capture all the object at once. However, if the stripes look the same, camera could not distinguish their location (e.g., if one stripe is behind an object). Time multiplexing is used.
Time multiplexing - different patterns of stripes (arrangements of binary stripes) are projected and their progression through time (i.e., a set of different projections) is inspected to give an encoding of each pixel location in a 3D space.
- For example, in binary encoding, projecting
8different binary patterns of black | white, i.e.,[bw,bwbw,$\cdots$ ,bwbwbwbw], onto an object, for every resolution point would give an encoding of8bits, each bit representing1or0for the stripe it belongs to at every pattern. There are$2^8$ ways to arrange these bits giving a total of256single pixel values. -
Hamming distance - a metric for comparing
2binary data (sum of digits of a difference between each bit), for instance, the distance between$4$ (0100) and$14$ (1110) is$2$ , whereas between$4$ (0100) and$6$ (0110) is$1$ - Given that Grey Code has a Hamming distance of
1and Inverse Grey Code has a Hamming distance ofN-1, progression binary encodings belong to neither category. This means a lot of flexibility and a variety of possible algorithms.
In time multiplexing, because of the lenses, defocus may occur which mangles the edges and, because of the high frequency, information about regions could be lost. Sinusoidal patterns are used which are continuous and less affected by defocus.
Sinusoidal patterns - patterns encoded by a geometric function (
Reconstructing the surface from the wave patterns can cause ambiguities if surface is discontinuous so waves either have to be additionally encoded (labeled) or frequency should be dynamic (low
$\to$ high)
The goal is to calculate the orientation of the surfaces, not the depth - only the lighting changes, the location and perspective stays the same. If an absolute location of one point in the map is known, with integration other location can be found. LED illumination is used.
-
Lambertian reflectance - depends on the angle
$\theta$ between the surface normal and the ray to light -
Specular reflectance - depends on the angle
$\alpha$ between reflected ray to light and ray to observer
For simplicity, we assume there is no specular reflectance (that surface normal doesn't depend on it). We also assume light source is infinitely far away (constant) The diffusive illumination for each
Where:
-
$\mathbf{l}_i$ - direction to light from surface -
$\mathbf{n}$ - surface normal (different for each pixel) -
$k_d$ - constant reflectance -
$I_p$ -constant light spread
Assuming
Photometric stereo requires many assumptions about illumination and surface reflectance also a point of reference, also precision is no guaranteed because depth is estimated from estimated surface normals


After acquiring a depth map, it is converted (based on the pose and the optics of the camera) to point cloud which contains locations in space for each 3D point. Their neighborhoods help estimate surface normals which are used to build surfaces.
Poisson surface reconstruction - a function where surface normals are used as gradients - inside shape is annotated by ones, outside by zeros. It is a popular function to reconstruct surfaces from normals. It helps to create unstructured meshes.
Knowing a scene representation at different timesteps, they can be combined into one scene via image registration. A model of the scene is taken and its point cloud representations and the best fit is found. If point correspondences are missing, they are inferred. Once all points are known, Kabsch algorithm is applied to find the best single rigid transformation which optimizes the correspondences.
Kabsch algorithm - given 2 point sets
Point inferring can be done in multiple ways, a simplest one is via iterative closest point where closest points in each set are looked for and the best transformation to reach those points is performed iteratively until the points match.
PCA - algorithm that determines the dominant modes of variation of the data and projects the data onto the coordinate system matching the shape of the data.
Covariance - measures how much each of the dimensions vary with respect to each other. Given a dataset
Covariance matrix has variances on the diagonal and cross-covariances on the off-diagonal. If cross-covariances are 0s, then neither of the dimensions depend on each other. Given a dataset
- Identical variance - the spread for every dimension is the same
- Identical covariance - the correlation of different dimensions is the same
PCA chooses such
PCA thus becomes an optimization problem constrained to 0 shows that the columns of
In general, the optimization solution for covariance matrix
PCA works well for linear transformation however it is not suitable for non-linear transformation as it cannot change the shape of the datapoints, just rotate them.
Singular Value Decomposition - a representation of any
Where:
-
$U\in\mathbb{R}^{M\times M}$ - has orthonormal columns (eigenvectors) -
$V\in\mathbb{R}^{N\times N}$ - has orthonormal columns (eigenvectors) -
$D\in\mathbb{R}^{M\times N}$ - diagonal matrix and has singular values of$X$ on its diagonals ($s_1>s_2>...>0$ ) (eigenvalues)
In the case of images
$\Sigma$ would be$N\times N$ matrix where$N$ - the number of pixles (e.g.,$256\times 256=65536$ ). It could be very large therefore we don't explicitly compute covariance matrix.
Eigenface - a basis face which is used within a weighted combination to produce an overall face (represented by x - eigenface indices and y - eigenvalues (weights)). They are stored and can be used for recognition (not detection!) and reconstruction.

To compute eigenfaces, all face images are flattened and rearranged as a
2Dmatrix (rows = images, columns = pixels). Then the covariance matrix and its eigenvalues are found which represent the eigenfaces. Larger eigenvalue = more distinguishing.
To map image space to "face" space, every image
Given a weight vector of some new face
$$d(\mathbf{w}{\text{new}}, \mathbf{w}{i})=||\mathbf{w}{\text{new}} - \mathbf{w}{i}||_2$$
Note that the data must be comparable (same resolution) and size must be reasonable for computational reasons
Thermography - imaging of the heat being radiated from an object which is measured by infrared cameras/sensors. It helps to spot increased blood flow and metabolic activity when there is an inflammation (detects breast cancer, ear infection).
Process of taking an x-ray photo: A lamp generates electrons which are bombarded at a metal target which in turn generates high energy photons (x-rays). They go though some medium (e.g., chest) and those which pass though are captured on the other side what results in a black | white image (e.g., high density (bones) = white, low density (lungs) = black)
X-ray photos are good to determine structure but we cannot inspect depth
Process of 3D reconstruction via computed tomography (CT): An x-ray source is used to perform multiple scans across the medium to get multiple projections. The data is then back-projected to where the x-rays travelled to get a 3D representation of a medium. In practice filtered back-projections are used with smoothened (convolved with a filter) projected data.
CT reconstructions are also concerned with structural imaging
Process of nuclear medical imaging via photon emission tomography (PET): A subject is injected with radioactive tracers (molecules which emit radioactive energy) and then gamma cameras are used to measure how much radiation comes out of the body. The detect the position of each gamma ray and back-projection again is used to reconstruct the medium.
Nuclear Imaging is concerned with functional imaging and inspects the areas of activity. However, gamma rays are absorbed in different amounts by different tissues, therefore, it is usually combined with CT


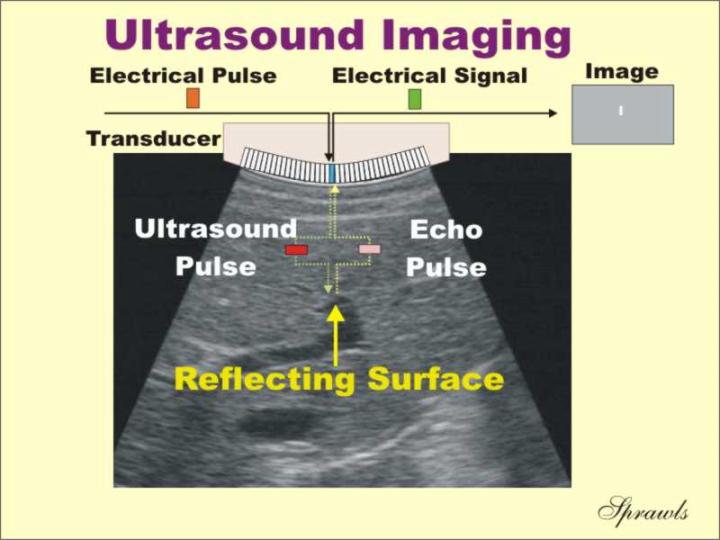
Ultrasound - a very high pitched sound which can be emitted to determine location (e.g., by bats, dolphins). Sonar devices emit a high pitch sound, listen for the echo and determine the distance to an object based on the speed of sound.
Process of ultrasound imaging using ultrasound probes: An ultrasound is emitted into a biological tissue and the reflection timing is detected (different across different tissue densities) which helps to work out the structure of that tissue and reconstruct its image.
The resolution of ultrasound images is poor but the technique is harmless to human body
Process of light imaging using pulse oximeters: as blood volume on every pulse increases, the absorption of red light increases so the changes of the intensity of light can be measured through time. More precisely, the absorption at 2 different wavelengths (red and infrared) corresponding to 2 different blood cases (oxy and deoxy) is measured whose ratio helps to infer the oxygen level in blood.
Tissue scattering - diffusion and scattering of light due to soft body. This is a problem because it produces diffused imaging (can't determine from which medium light bounces off exactly (path information is lost), so can't do back-projection)
Several ways to solve tissue scattering:
- Multi-wavelength measurements and scattering change detection - gives information on how to resolve the bouncing off
- Time of flight measurements (e.g., by pulses, amplitude changes) - gives information on how far photons have travelled
Process of optical functional brain imaging using a light detector with many fibers: A light travels through skin and bone to reach the surface of the brain. While a subject watches a rotating checkerboard pattern, an optical signal in the brain is measured. Using a 3D camera image registration, brain activity captured via light scans can be reconstructed on a brain model.
Process of looking at water concentration using magnetic devices: A subject is put inside a big magnet which causes spinning electrons to align with magnetic waves. Then a coil is used around the area of interest (e.g., a knee) which uses radiofrequency - it emits a signal which disrupts the spinning electrons and collects the signal (the rate of it) emitted when the electrons come back to their axes. Such information is used to reconstruct maps of water concentration.
Functional MRI (FMRI) - due to oxygenated blood being more magnetic than deoxygenated blood, blood delivery can be monitored at different parts of the brain based on when they are activated (require oxygenated blood).
MRI is structural and better than CT because it gives better contrast between the soft tissue

Viewpoint-invariant - non-changing features that can be obtained regardless of the viewing conditions. More sensitivity requires more features which is challenging to extract and more stability requires fewer features which are always constant.
Marr's model-based approach on reconstructing 3D scene from 2D information:
- Primal sketch - understanding what the intensity changes in the image represent (e.g., color, corners)
2.5Dsketch - building a viewer-centered representation of the object (object can be recognized from viewer angle)- Model selection - building an object-centered representation of the object (object can be recognized from all angles)
Marr's algorithm approaches the problem in a top-down approach (like brain): it observes a general shape (e.g., human), and then if it needs it gets into details (e.g., every human hair). It's object-centered - shape doesn't change depending on view.
Recognition by Components Theory - recognizing objects by matching visual input against structural representations of objects in the brain, consisting of geons and their relations
The problem is that there is an infinite variety of objects so there is no efficient way to represent and store the models of every object. Even a library containing
3Dparts (building blocks), would not be big enough and would need to be generalized.
Appearance based recognition - characterization of some aspects of the image via statistical methods. Useful when a lot of information is captured using multiple viewpoints because an object can look different from a different angle and it may be difficult to recognize using a model which is viewpoint-invariant. A lot of processing is involved in statistical approach.
SIFT can be applied to find features in the desired image which can further be re-described (e.g., scaled, rotated) to match the features in the dataset for recognition (note: features must be collected from different viewpoints in the dataset)
Part Based Model - identifying an object by parts - given a bag of features within the appearance model, the image is checked for those features and determined whether it contains the object. However, we want structure of the parts (e.g., order)
Constellation Model - takes into account geometrical representation of the identified parts based on connectivity models. It is a probabilistic model representing a class by a set of parts under some geometric constraints. Prone to missing parts.
Hierarchical Architecture for object recognition (extract to hypothesize, register to verify):
- Extract local features and learn more complex compositions
- Select the most statistically significant compositions
- Find the category-specific general parts
Appearance based recognition is a more sophisticated technique as it is more general for different viewpoints, however model based techniques work well for non-complex problems because they are very simple.
CMOS | CCD sensor - a digital camera sensor composed of a grid of photodiodes. One photodiode can capture one RGB color, therefore, specific pattern of diodes is used where a subgrid of diodes provides information about color (most popular - Bayer filter).
Bayer fillter - an RGB mask put on top of a digital sensor having twice as many green cells as blue/red to accomodate human eye. A cell represents a color a diode can capture. For actual pixel color, surrounding cells are also involved.
Since depth information is lost during projection, there is ambiguity in object sizes due to perspective
Pinhole camera - abstract camera model: a box with a hole which assumes only one light ray can fit through it. This creates an inverted image on the image plane which is used to create a virtual image at the same distance from the hole on the virtual plane.

Given a true point $=\begin{bmatrix}x & y & z\end{bmatrix}^{\top}$ and a projected point $P'=\begin{bmatrix}x' & y' & z'\end{bmatrix}^{\top}$ (where
Such weak-perspective projection is used when scene depth is small because magnification
Pinhole cameras are dark to allow only a small amount of rays hit the screen (to make the image sharp). Lenses are used instead to capture more light.
Projection of a 3D coordinate system is extrinsic (3D world 3D camera) and intrinsic (3D camera 2D image). An acquired point in camera 3D coordinates is projected to image plane, then to discretized image. General camera has 11 projection parameters.
For extrinsic projection real world coordinates are simply aligned with the camera's coordinates via translation and rotation:
Homogenous coordinates - "projective space" coordinates (Cartesian coordinates with an extra dimension) which preserve the scale of the original coordinates. E.g., scaling $\begin{bmatrix}x & y & 1\end{bmatrix}^{\top}$ by
In normalized camera coordinate system origin is at the center of the image plane. In the image coordinate system origin is at the corner.
Calibration matrix 3D camera coordinate to discrete pixel
Where:
-
$\alpha_x$ and $\alpha_y$ - focal length
$f$ (which acts like$z$ (i.e., like extra dimension$w$ ) to divide$x$ and$y$ ) multiplied by discretization constant$m_x$ or$m_y$ (which is the number of pixels per sensor dimension unit) - $x_0$ and $y_0$ - offsets to shift the camera origin to the corner (results in only positive values)
- $s$ - the sensor skewedness: it is usually not a perfect rectangle
Lens adds nonlinearity for which symmetric radial expansion is used (for every point from the origin the radius changes but the angle remains) to un-distort. Along with shear, this transformation is captured in $s$ (see above).
For a general projection matrix, we can obtain a translation vector
If 3D coordinates of a real point and 2D coordinates of a projected point are known, then, given a pattern of such points, 3D2D" mapping is solved, e.g., via Direct Linear Transformation (DLT) (see this video) or reprojection error optimization. If positions/orientations are not known, multiplane camera calibration is performed where only many images of a single patterned plane are needed.
Given a point
Horizon - connected vanishing points of a plane. Each set of parallel lines correspond to a different vanishing point.
Alignment - fitting transformation parameters according to a set of matching feature pairs in original image and transformed image. Several matches are required because the transformation may be noisy. Also outliers should be considered (RANSAC)
Parametric (global) wrapping - transformation which affects all pixels the same (e.g., translation, rotation, affine). Homogenous coordinates are used again to accomodate transformation: $\begin{bmatrix}x' & y' & 1\end{bmatrix}^{\top}=T\begin{bmatrix}x & y & 1\end{bmatrix}^{\top}$. Some examples of
$$\underbrace{\begin{bmatrix}1 & 0 & t_x \ 0 & 1 & t_y \ 0 & 0 & 1\end{bmatrix}}{\text{translation}};\ \text{ }\ \underbrace{\begin{bmatrix}s_x & 0 & 0 \ 0 & s_y & 0 \ 0 & 0 & 1\end{bmatrix}}{\text{scaling}};\ \text{ }\ \underbrace{\begin{bmatrix}\cos\theta & -\sin\theta & 0 \ \sin\theta & \cos\theta & 0 \ 0 & 0 & 1\end{bmatrix}}{\text{rotation}};\ \text{ }\ \underbrace{\begin{bmatrix}1 & sh_x & 0 \ sh_y & 1 & 0 \ 0 & 0 & 1\end{bmatrix}}{\text{shearing}}$$
Affine transformation - combination of linear transformation and translation (parallel lines remain parallel). It is a generic matrix involving 6 parameters.
RANSAC - an iterative method for estimating a mathematical model from a data set that contains outliers
The most likely model is computed as follows:
- Randomly choose a group of points from a data set and use them to compute transformation
- Set the maximum inliers error (margin)
$\varepsilon_i=f(x_i, \mathbf{p}) - y_i$ and find all inliers in the transformation - Repeat from step
1until the transformation with the most inliers is found - Refit the model using all inliers
In the case of alignment a smallest group of correspondences is chosen from which the transformation parameters can be estimated. The number of inliers is how many correspondences in total agree with the model.
RANSAC is simple and general, applicable to a lot of problems but there are a lot of parameters to tune and it doesn't work well for low inlier ratios (also depends on initialization).
Homography - projection from plane to plane: 2 projective planes with the same center of projection.
Stitching - to stitch together images into panorama (mosaic), the transformation between
2images is calculated, then they are overlapped and blended. This is repeated for multiple images. In general, images are reprojected onto common plane.
For a single 2D point $\begin{bmatrix}wx_i' & wy_i' & w\end{bmatrix}^{\top}=H\begin{bmatrix}x_i & y_i & 1\end{bmatrix}^{\top}$, where 1s and 0s) of orignial and projected coordinates and a 0s vector. More correspondences can be added which would expand the equation:
$$\underbrace{\begin{bmatrix}x_1 & y_1 & 1 & 0 & 0 & 0 & -x_1'x_1 & -x_1'y_1 & -x_1' \ 0 & 0 & 0 & x_1 & y_1 & 1 & -y_1'x_1 & -y_1'y_1 & -y_1' \ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots &\vdots & \vdots & \vdots\ x_N & y_N & 1 & 0 & 0 & 0 & -x_N'x_N & -x_N'y_N & -x_N' \ 0 & 0 & 0 & x_N & y_N & 1 & -y_N'x_N & -y_N'y_N & -y_N' \ \end{bmatrix}}{A}\underbrace{\begin{bmatrix}h{11} \ h_{12} \ h_{13} \ h_{21} \ h_{22} \ h_{23} \ h_{31} \ h_{32} \ h_{33}\end{bmatrix}}{\mathbf{h}}=\underbrace{\begin{bmatrix}0 \ 0 \ \vdots \ 0 \ 0\end{bmatrix}}{\mathbf{0}}$$
This can be formulated as least squares:
During forward wrapping (projection), pixels may be projected between discrete pixels in which case splatting - color distribution among neighboring pixels - is performed. For inverse wrapping, color from neighbors is interpolated.
Local features - identified points of interest, each described by a feature vector, which are used to match descriptors in a different view. Applications include image alignment, 3D reconstruction, motion tracking, object recognition etc.
Local feature properties:
- Repeatability - same feature in multiple images (despite geometric/photometric transformations). Corners are most informative
- Saliency - distinct descriptions for every feature
-
Compactness - num features
$\ll$ image pixels - Locality - small area occupation
Harris Corner Detector - detects intensity
For small shifts
Such
If eigenvalues are large, a corner is detected because intensity change (gradient) is big in both
Non-maxima suppression is applied after thresholding.
Harris Detector is rotation invariant (same eigenvalues if image is rotated) but not scale invariant (e.g., more corners are detected if a round corner is scaled)
Hessian Corner Detector - finds corners based on values of the determinant of the Hessian of a region:
Automatic scale selection - a scale invariant function which outputs the same value for regions with the same content even if regions are located at different scales. As scale changes, the function produces a different value for that region and the scales for both images is chosen where the function peaks out:
Blob - superposition of 2 ripples. A ripple is a zerocrossing function at an edge location after applying LoG. Because of the shape of the LoG filter, it detects blobs (maximum response) as spots in the image as long as its size matches the spot's scale. In which case filter's scale is called characteristic scale.
Note that in practice LoG is approximated with a difference of Gaussian (DoG) at different values of
$\sigma$ . Many such differences form a scale space (pyramid) where local maximas among neighboring pixels (including upper and lower DoG) within some region are chosen as features
SIFT Descriptor - a descriptor that is invariant to scale. A simple vector of pixels of some region does not describe a region well because a corresponding region in another image may be shifted causing mismatches between intensities. SIFT Descriptor creation:
- Calculate gradients on each pixel and smooth over a few neighbors
- Split the region to
16subregions and calculate a histogram of gradient orientations (8directions) at each - Each orientation is described by gradient's magnitude weighted by a Gaussian centered at the region center
- Descriptor is acquired by stacking all histograms (
4$\times$4$ \times$8) to a single vector and normalizing it
Actually, before the main procedure of SIFT, the orientation must be normalized - the gradients are rotated into rectified orientation. It is found by computing a histogram of orientations (region is rotated 36 times) where the largest angle bin represents the best orientation.
To make the SIFT Descriptor invariant to affine changes, covariance matrix can be calculated of the region, then eigenvectors can be found based on which it can be normalized.
SIFT Descriptor is invariant:
- Scale - scale is found such that the scale invariant function has local maxima
- Rotation - gradients are rotated towards dominant orientation
- Illumination (partially) - gradients of sub-patches are used
- Translation (partially) - histograms are robust to small shifts
- Affine (partially) - eigenvectors are used for normalization
When feature matches are found, they should be symmetric
Stereo imaging (triangulation) - given several images of the same object, its 3D representation is computed (e.g., depth map, point cloud, mesh etc.)
3D point reconstruction can be calculated by intersection of 2 rays (projection points in the images). In practice, rays will not intersect, therefore linear and non-linear approaches are considered (note: 3D point is unknown but the projection points in the 2 images are known):
- The former solves a homogenous system by SVD resulting in the desired
3Dpoint being the smallest eigenvector. It generalizes well but has error cases. - The latter introduces a reprojection error (mismatch between true and generated projections of a predicted
3Dpoint). True point is detected when the error is minimized. It's very accurate but requires iterative solution.
If the correspondence in another image is not known but cameras are in parallel, then given their focal length 2 projected points (disparity)
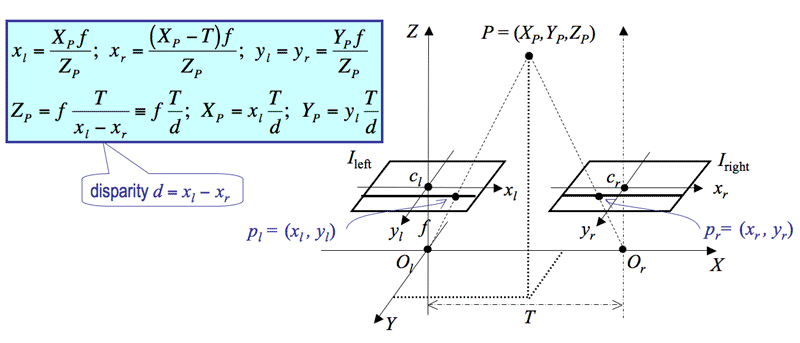
If cameras are not in parallel, disparity won't help, thus epipolar geometry is considered which simplifies the correspondence problem to 1D search along an epipolar line. In one image a ray from the projected point to the 3D point is projected in another image (epipolar line) where we look for a point from which the ray (to the 3D point) would be projected in the initial image crossing its projected point. Connecting those points with epipoles (where base line crosses image plane) results in epipolar plane.
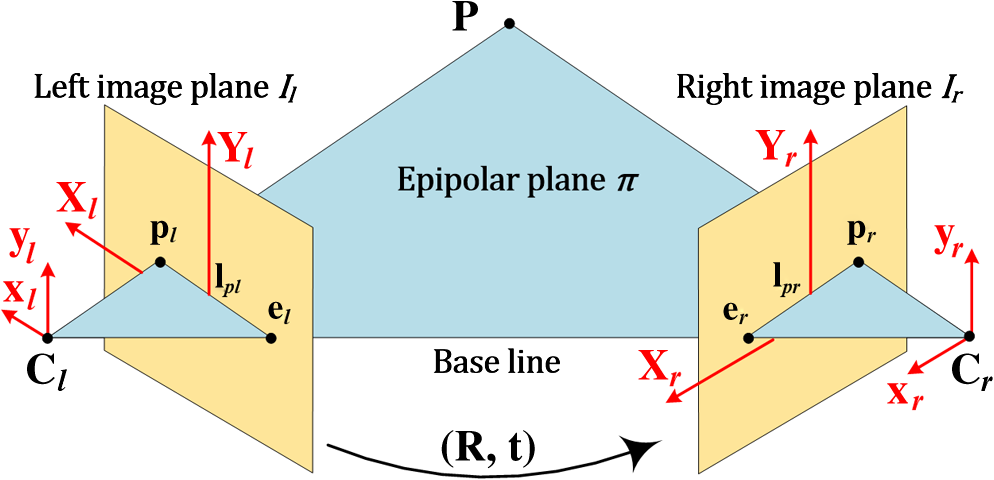
To get an epipolar line when some point is selected on the left image, there has to be some constraints for the stereo system.
If camera calibrations are known, essential matrix
For a non-calibrated system coordinates cannot be transformed, however by combining left and right cameras' intrinsic parameters
If optical axes are parallel stereo image rectification is performed - images are reprojected onto a common plane, parallel to the base line where the depth can be computed based on disparity.
To estimate
- Assumptions: points in both cameras are visible, regions are similar and the baseline is small compared to depth
- Correspondences: once a feature point is selected in one image, a corresponding feature in the other image is checked via dense correspondences - a window is slide through epipolar line and such regions is selected where the cost is the lowest (best similarity)
- Constraints -
1-1correspondence, same order of points (no in-between objects), locally smooth disparity
SFM - reconstruction of camera positions given several images of the same scene
To compute the projection matrix
In general correspondences are unknown and they are jointly looked for. The general algorithm for correspondences and
- Find key points in the images (e.g., corner)
- Calculate potential matches
- Estimate epipolar geometry (use RANSAC)
- Improve match estimates and iterate
Each local feature region has a descriptor which is a point in a high-dimensional space (e.g., SIFT). An efficient way to perform feature retrieval is to make the problem similar to text retrieval, i.e., indexing. For that, each feature is mapped to tokens/words by quantizing the feature space via clustering (to make a discrete set of "visual words", i.e., bag of words).
Texton - cluster center of filter responses over collection of images. It is assigned to features that are closest to it.
To identify textures (repeated local patterns), filters that look like patterns themselves are used to find them and then local windows are used for statistical description. Textures can be represented by a 2D graph of points representing windows (x - mean y - mean
Inverted indexing (each "visual word" is assigned a list of images) is used to enable faster search at query time
Given a fixed set of features, every image can be represented in terms of that set by a distribution of every feature occurrence. Then, given two such representations
Given some query and a database, retrieval quality is calculated by precision (num relevant / tot returned) and recall (num relevant / tot relevant). Obtaining all possible precisions and recalls for a single query forms a PR curve under which the area can be calculated to produce an accuracy score.
For computational efficiency, hierarchical clustering is used to subgroup textons
Bag of words pros and cons:
(+)Flexible to geometry/deformation(+)Compact summary of image content(+)Vector representation for sets(-)Ignored geometry must be verified(-)Mixed foreground and background(-)Unclear optimal vocabulary
Recognized instances must be spatially verified, e.g., using RANSAC (by checking support for possible transformations) or generalized Hough Transform (by allowing each feature to cast a vote on location, scale and orientation).
Term Frequency - Inverse Document Frequency (TF-IDF) weighting - another way to retrieve query results taken from text retrieval. Such weighting describes frames by their word frequency and downweights words that appear often in the database (aims to retrieve results that have a lot of similarity with the query but overall are as little similar to other documents):
Where:
-
$n_{id}$ - num occurrences of word$i$ in document$d$ -
$n_d$ - num words in document$d$ -
$n_i$ - num documents word$i$ occurs in -
$N$ - tot num documents in the database
Query Expansion - acquiring filtered query results and reusing them for the same query to obtain even more results
Object categorization - given a small number of training samples, recognize a priori unknown instances and assign a correct label. There are 2 object categorization levels: instance (e.g., a car) and category (e.g., a bunch of cars). There are also different levels of abstraction: abstract (e.g., animal), basic (e.g., dog), individual (e.g., German Shepard). Basic is most commonly chosen as it reflects humans.
Supervised classification - given a collection of labeled samples, a function is looked for that can predict labels for new samples. The function is good when the risk (expected loss) is minimized. There are 2 models for that:
- Generative - training data is used to build a probability model (conditional densities, priors are modeled) [e.g., CNN]
- Discriminative - a decision boundary is constructed directly (posterior is modeled) [e.g., SVM]
Learning types:
- Reinforcement learning - learn to select an action of maximum payoff
- Supervised learning - given input, predict output.
2types: regression (continuous values), classification (labels) - Unsupervised learning - discover internal representation of an input (also includes self-supervised learning)
Applications to computer vision:
- Classification - assign class labels to images [ResNet, SENet]
- Detection - identify rectangular regions of objects [Faster R-CNN, YOLO]
- Segmentation - classify each pixel to a specific category [DeepLab, UNet]
- Low-level vision - pixel-based processing techniques (denoising, super-resolution, inpainting etc.)
- 3D vision -
3D/depth reconstruction [NERF] - Vision + X - processing vision along with other modalities like audio/speech (e.g., DALLE)
Artificial neuron representation:
-
$\mathbf{x}$ - input vector ("synapses") is just the given features -
$\mathbf{w}$ - weight vector which regulates the importance of each input -
$b$ - bias which adjusts the weighted values, i.e., shifts them -
$\mathbf{z}$ - net input vector $\mathbf{w}^{\top}\mathbf{x}+b$ which is linear combination of inputs -
$g(\cdot)$ - activation function through which the net input is passed to introduce non-linearity -
$\mathbf{a}$ - the activation vector $g(\mathbf{z})$ which is the neuron output vector
Artificial neural network representation:
- Each neuron receives inputs from inputs neurons and sends activations to output neurons
- There are multiple neuron layers and the more there are, the more powerful the network is (usually)
- The weights learn to adapt to the required task to produce the best results based on some loss function
Popular activation functions - ReLU, sigmoid and softmax, the last two of which are mainly used in the last layer before the error function:
Popular error functions - MSE (for regression), Cross Entropy (for classification):
$$\text{MSE}(\hat{\mathbf{y}}, \mathbf{y})=\frac{1}{N}\sum_{n=1}^N(y_n-\hat{y}n)^2;\ \text{ }\ \text{ }\ \text{ }\ \text{ }\ \text{CE}(\hat{\mathbf{y}}, \mathbf{y})=-\sum{n=1}^N y_n \log \hat{y}_n$$
Backpropagation - weight update algorithm during which the gradient of the error function with respect to the parameters
To avoid overfitting, early stopping, dropout, batch normalization, regularization data augmentation are used. Also data preprocessing, e.g., PCA, normalization
Locally connected layer - neurons which are connected only to local regions of an image instead of all the pixels. This allows less computational resources and limits parameter space allowing less samples for training.
The size of the feature map acquired after convolution depends on the kernel size (filter width/height), padding (border size), dilation (gap size ratio between filter values) and stride (sliding step size):
Transfer Learning - if there is not enough data, a majority of the network can be initialized with already learned weights (majority of which can be kept frozen during training) from another network and only the remaining part can be trained.
Modern research topics:
- Generative Adversarial Networks (GANs) - given some input space (created via VAEs), a generator creates an image and a discriminator classifies how real it is. It is a
min-maxoptimization problem. [DCGAN] - Self-supervised learning - learning from the data itself without labels. There are
2types: learning specific tasks (labels are within the training samples, e.g., colorizing) and learning general representations (trained on general data, then fine-tuned). Other modalities like audio can also be used to self-supervision. - Transformers (vision) - multi-head attention module is used which transforms the input data to value, key and query such that they have a high correlation.Image patches are used as tokens to do data fusion.
-
Visual Perception
- Why is computational vision challenging? Some applications.
- How photocell's interaction with light is registered as an electric signal?
- Difference between rods & cones
- How Ganglion cells work + types
- Trichromatic coding + how is color captured in the eye
- Perceivable electormagnetic wavelengths range
- Law of Geometric Optics + Snell's Law
- Focal length of a human eye
- Lens + Magnification formulas
- How curved image plane impacts object/image approximation?
-
Edge Filters
- Intensity image + Colormap + Image
- How is magnitude and direction computed of a gradient map?
- Edge descriptors, detection steps and detection criteria
- How
1storder edge detector works; what are some popular ones? - How
2ndorder edge detector works; what is a popular operator? - What filter is used for noise removal; how can it be created?
- Noise suppression-localization tradeoff
- How to combine noise and edge filter into one? Why is it useful?
- Canny Edge Detection algorithm
-
Motion
- SIFT and types of invariances
- Where image motion analysis can be applied?
- Optical Flow + its usage
- Difference Picture + usage of connectedness to clean up noise
-
Motion correspondence and its
3principles + Aperture problem - Algorithm for Motion correspondence and what is used for degree of similarity
- How Hough Transform works?
-
Registration & Segmentation
- Image Registration and its cases; how it can be expressed mathematically?
- Types of entities we want to match and transformations we may encounter
- Conservation of Intensity, Mutual Information and Normalized CC
- How image segmentation (histogram-based) depends on image resolution?
- Image segmentation + its techniques
- Image representation and Image characterization types
- Thresholding for segmentation + its types (what is Otsu Threshold?)
- Mathematical Morphology for segmentation, how does it incorporate structuring elements?
- Active Contours for segmentation, what is energy and snake in the image?
- Watershed for segmentation
-
3D Imaging
- 3D Imaging applications and why is it useful?
- Passive Imaging and Active Imaging + challenges of each
- Stereophotogrammetry, Structure from motion and Depth from focus - how it works + challenges
- How does Active Stereophotogrammetry work + its challenges?
-
Structured light imaging + its
1Dand2Ddevices - Time multiplexing and why we need it?
- What are sinusoidal patterns used for?
- Photometric stereo + its challenges.
- Reflectance types and diffusive illumination formula
- How does surface reconstruction work + how Poisson function contributes to it?
- How does surface registration work + how Kabsch algorithm contributes to it?
-
Face Recognition with PCA
-
Variance and Covariance formulas + how to compute Covariance Matrix
$\Sigma$ ? - PCA + its algorithm
- Where PCA is not suitable?
- PCA expressed as SVD
- Eigenface + how to compute it + where are they used?
- Face recognition given a dataset of eigenfaces
-
Variance and Covariance formulas + how to compute Covariance Matrix
-
Medical Image Analysis
- Thermography and where is it used?
- How to take an x-ray photo and where is it used?
- How to perform CT and why do we use it?
- How does PET work? Is it structural or functional imaging? Why do we combine it with CT?
- How doe imaging with ultrasound works? What's its advantage?
- How pulse oximeters work? How is light used for brain imaging? Problem of tissue scattering + how to solve it?
- How do MRI and FMRI work? Why are they preferred over CT?
-
Object Recognition
- Viewpoint invariance + sensitivity-stability tradeoff
- Marr's model-based algorithm + how is it similar to brain?
- How does recognition by Components Theory works?
- Problem of model-based object recognition
- How does appearance-based object recognition works? How SIFT becomes handy?
- Difference between Part-based model and Constellation Model
- Hierarchical Architecture for object recognition
- When o use appearance-based and when to use model-based object recognition?
-
Robot Vision
-
Camera Geometry
- How does CMOS/CCD photosensor work along with Bayer Filter?
- How pinhole cameras work and why are they dark?
- Weak-perspective projection principle (when depth is small)
- Difference between intrinsic and extrinsic projection
- Homogenous coordinates
-
Calibration matrix
$K$ (and its parameters) and a general projection matrix (how can it be computed?) - Vanishing point and horizon
-
Alignment & Features
- Alignment, affine transform + examples of parametric wrapping
- RANSAC and its algorithm (when it can fail?)
- Homography and stitching
- Estimation of projection matrix
$H$ as optimization problem - Local features and their properties
- Harris Corner Detector and its approximated expression (by Taylor Series) convolved with Gaussian
- Corner Response Function and why it is used. How invariant Harris Detector is?
- Hessian Corner Detector
- How automatic scale selection works?
- How are blobs detected and how pyramids are used for feature selection?
- SIFT Descriptor and how to create it. How invariant is is?
-
Multiple-View Geometry
-
Stereo imaging; difference between linear and non-linear approach for
3Dpoint reconstruction - When and how can disparity be used for depth estimation?
- When epipolar geometry is used for depth estimation? Terms: epipolar line, epipolar plane, epipole, baseline
- Why constraints are needed for a stereo system? How to approach them in calibrated and non-calibrated cases?
- Essential matrix, fundamental matrix and Epipolar Constraint
- What correspondences to use for estimating
$F$ ? - SFM and what projection error is used?
- Iterative algorithm for estimating
$F$
-
Stereo imaging; difference between linear and non-linear approach for
-
Recognition
- How feature retrieval is approached via bag of words? Its pros and cons?
- What is texton and how textures are identified?
- How to calculate similarity between given and queried images? What is inverted indexing?
- How to evaluate retrieval accuracy based on precision-recall curve?
- How does retrieval based on TF-IDF weighting work?
- Query expansion
- Object categorization; its level types and abstraction types
-
Supervised classification and its
2types
-
Camera Geometry
-
Deep Learning
- Deep learning types, applications for CV
- Artificial neuron and NN representation
- Popular activation and error functions
- Backpropagation and how to tackle overfitting?
- Local connectivity vs global connectivity
- How to compute feature map size given
kernel_size,padding,dilationandstride? - Transfer learning
-
3modern research techniques for imaging and how they generally work?