diff --git a/ja/1_instruction_tuning/README.md b/ja/1_instruction_tuning/README.md
new file mode 100644
index 00000000..41167b7b
--- /dev/null
+++ b/ja/1_instruction_tuning/README.md
@@ -0,0 +1,30 @@
+# インストラクションチューニング
+
+このモジュールでは、言語モデルのインストラクションチューニングのプロセスをガイドします。インストラクションチューニングとは、特定のタスクに対してモデルを適応させるために、特定のタスクに関連するデータセットで追加のトレーニングを行うことを指します。このプロセスは、特定のタスクにおけるモデルのパフォーマンスを向上させるのに役立ちます。
+
+このモジュールでは、2つのトピックを探ります:1) チャットテンプレートと2) 教師あり微調整
+
+## 1️⃣ チャットテンプレート
+
+チャットテンプレートは、ユーザーとAIモデル間のインタラクションを構造化し、一貫性のある文脈に適した応答を保証します。これらのテンプレートには、システムメッセージや役割に基づくメッセージなどのコンポーネントが含まれます。詳細については、[チャットテンプレート](./chat_templates.md)セクションを参照してください。
+
+## 2️⃣ 教師あり微調整
+
+教師あり微調整(SFT)は、事前トレーニングされた言語モデルを特定のタスクに適応させるための重要なプロセスです。これは、ラベル付きの例を含む特定のタスクのデータセットでモデルをトレーニングすることを含みます。SFTの詳細なガイド、重要なステップ、およびベストプラクティスについては、[教師あり微調整](./supervised_fine_tuning.md)ページを参照してください。
+
+## 演習ノートブック
+
+| タイトル | 説明 | 演習 | リンク | Colab |
+|--------|-------------|-----------|--------|-------|
+| チャットテンプレート | SmolLM2を使用してチャットテンプレートを使用し、チャットml形式のデータセットを処理する方法を学びます | 🐢 `HuggingFaceTB/smoltalk`データセットをchatml形式に変換
🐕 `openai/gsm8k`データセットをchatml形式に変換 | [ノートブック](./notebooks/chat_templates_example.ipynb) |  |
+| 教師あり微調整 | SFTTrainerを使用してSmolLM2を微調整する方法を学びます | 🐢 `HuggingFaceTB/smoltalk`データセットを使用
|
+| 教師あり微調整 | SFTTrainerを使用してSmolLM2を微調整する方法を学びます | 🐢 `HuggingFaceTB/smoltalk`データセットを使用
🐕 `bigcode/the-stack-smol`データセットを試す
🦁 実際の使用ケースに関連するデータセットを選択 | [ノートブック](./notebooks/sft_finetuning_example.ipynb) | |
+
+## 参考文献
+
+- [Transformersのチャットテンプレートに関するドキュメント](https://huggingface.co/docs/transformers/main/en/chat_templating)
+- [TRLの教師あり微調整スクリプト](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py)
+- [TRLの`SFTTrainer`](https://huggingface.co/docs/trl/main/en/sft_trainer)
+- [直接選好最適化に関する論文](https://arxiv.org/abs/2305.18290)
+- [TRLを使用した教師あり微調整](https://huggingface.co/docs/trl/main/en/tutorials/supervised_fine_tuning)
+- [ChatMLとHugging Face TRLを使用したGoogle Gemmaの微調整方法](https://www.philschmid.de/fine-tune-google-gemma)
+- [LLMを微調整してペルシャ語の商品カタログをJSON形式で生成する方法](https://huggingface.co/learn/cookbook/en/fine_tuning_llm_to_generate_persian_product_catalogs_in_json_format)
diff --git a/ja/1_instruction_tuning/chat_templates.md b/ja/1_instruction_tuning/chat_templates.md
new file mode 100644
index 00000000..1d92e7f6
--- /dev/null
+++ b/ja/1_instruction_tuning/chat_templates.md
@@ -0,0 +1,115 @@
+# チャットテンプレート
+
+チャットテンプレートは、言語モデルとユーザー間のインタラクションを構造化するために不可欠です。これらは会話の一貫した形式を提供し、モデルが各メッセージの文脈と役割を理解し、適切な応答パターンを維持することを保証します。
+
+## ベースモデル vs インストラクションモデル
+
+ベースモデルは次のトークンを予測するために生のテキストデータでトレーニングされる一方、インストラクションモデルは特定の指示に従い会話に参加するように微調整されたモデルです。例えば、`SmolLM2-135M`はベースモデルであり、`SmolLM2-135M-Instruct`はその指示に特化したバリアントです。
+
+ベースモデルをインストラクションモデルのように動作させるためには、モデルが理解できるようにプロンプトを一貫してフォーマットする必要があります。ここでチャットテンプレートが役立ちます。ChatMLは、システム、ユーザー、アシスタントの役割を明確に示すテンプレート形式で会話を構造化します。
+
+ベースモデルは異なるチャットテンプレートで微調整される可能性があるため、インストラクションモデルを使用する際には、正しいチャットテンプレートを使用していることを確認する必要があります。
+
+## チャットテンプレートの理解
+
+チャットテンプレートの核心は、言語モデルと通信する際に会話がどのようにフォーマットされるべきかを定義することです。これには、システムレベルの指示、ユーザーメッセージ、およびアシスタントの応答が含まれ、モデルが理解できる構造化された形式で提供されます。この構造は、インタラクションの一貫性を維持し、モデルがさまざまな種類の入力に適切に応答することを保証します。以下はチャットテンプレートの例です:
+
+```sh
+<|im_end|>ユーザー
+こんにちは!<|im_end|>
+<|im_end|>アシスタント
+はじめまして!<|im_end|>
+<|im_end|>ユーザー
+質問してもいいですか?<|im_end|>
+<|im_end|>アシスタント
+```
+
+`transformers`ライブラリは、モデルのトークナイザーに関連してチャットテンプレートを自動的に処理します。`transformers`でチャットテンプレートがどのように構築されるかについて詳しくは[こちら](https://huggingface.co/docs/transformers/en/chat_templating#how-do-i-use-chat-templates)を参照してください。私たちはメッセージを正しい形式で構造化するだけで、残りはトークナイザーが処理します。以下は基本的な会話の例です:
+
+```python
+messages = [
+ {"role": "system", "content": "あなたは技術的なトピックに焦点を当てた役立つアシスタントです。"},
+ {"role": "user", "content": "チャットテンプレートとは何か説明できますか?"},
+ {"role": "assistant", "content": "チャットテンプレートは、ユーザーとAIモデル間の会話を構造化します..."}
+]
+```
+
+上記の例を分解して、チャットテンプレート形式にどのようにマッピングされるかを見てみましょう。
+
+## システムメッセージ
+
+システムメッセージは、モデルの動作の基礎を設定します。これらは、以降のすべてのインタラクションに影響を与える持続的な指示として機能します。例えば:
+
+```python
+system_message = {
+ "role": "system",
+ "content": "あなたはプロフェッショナルなカスタマーサービスエージェントです。常に礼儀正しく、明確で、役立つようにしてください。"
+}
+```
+
+## 会話
+
+チャットテンプレートは、ユーザーとアシスタント間の以前のやり取りを保存し、会話の履歴を通じて文脈を維持します。これにより、複数ターンにわたる一貫した会話が可能になります:
+
+```python
+conversation = [
+ {"role": "user", "content": "注文に関して助けが必要です"},
+ {"role": "assistant", "content": "お手伝いします。注文番号を教えていただけますか?"},
+ {"role": "user", "content": "注文番号はORDER-123です"},
+]
+```
+
+## Transformersを使用した実装
+
+`transformers`ライブラリは、チャットテンプレートのための組み込みサポートを提供します。使用方法は以下の通りです:
+
+```python
+from transformers import AutoTokenizer
+
+tokenizer = AutoTokenizer.from_pretrained("HuggingFaceTB/SmolLM2-135M-Instruct")
+
+messages = [
+ {"role": "system", "content": "あなたは役立つプログラミングアシスタントです。"},
+ {"role": "user", "content": "リストをソートするPython関数を書いてください"},
+]
+
+# チャットテンプレートを適用
+formatted_chat = tokenizer.apply_chat_template(
+ messages,
+ tokenize=False,
+ add_generation_prompt=True
+)
+```
+
+## カスタムフォーマット
+
+異なる役割に対して特別なトークンやフォーマットを追加するなど、さまざまなメッセージタイプのフォーマットをカスタマイズできます。例えば:
+
+```python
+template = """
+<|system|>{system_message}
+<|user|>{user_message}
+<|assistant|>{assistant_message}
+""".lstrip()
+```
+
+## マルチターン会話のサポート
+
+テンプレートは、文脈を維持しながら複雑なマルチターン会話を処理できます:
+
+```python
+messages = [
+ {"role": "system", "content": "あなたは数学の家庭教師です。"},
+ {"role": "user", "content": "微積分とは何ですか?"},
+ {"role": "assistant", "content": "微積分は数学の一分野です..."},
+ {"role": "user", "content": "例を教えてください。"},
+]
+```
+
+⏭️ [次へ: Supervised Fine-Tuning](./supervised_fine_tuning.md)
+
+## リソース
+
+- [Hugging Face Chat Templating Guide](https://huggingface.co/docs/transformers/main/en/chat_templating)
+- [Transformers Documentation](https://huggingface.co/docs/transformers)
+- [Chat Templates Examples Repository](https://github.com/chujiezheng/chat_templates)
diff --git a/ja/1_instruction_tuning/notebooks/.env.example b/ja/1_instruction_tuning/notebooks/.env.example
new file mode 100644
index 00000000..532be08f
--- /dev/null
+++ b/ja/1_instruction_tuning/notebooks/.env.example
@@ -0,0 +1,2 @@
+# このファイルを.envにコピーし、シークレット値を記入します
+HF_TOKEN=
diff --git a/ja/1_instruction_tuning/notebooks/chat_templates_example.ipynb b/ja/1_instruction_tuning/notebooks/chat_templates_example.ipynb
new file mode 100644
index 00000000..bde66dc4
--- /dev/null
+++ b/ja/1_instruction_tuning/notebooks/chat_templates_example.ipynb
@@ -0,0 +1,280 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# SFTTrainerを使用した教師あり微調整\n",
+ "\n",
+ "このノートブックでは、`trl`ライブラリの`SFTTrainer`を使用して`HuggingFaceTB/SmolLM2-135M`モデルを微調整する方法を示します。ノートブックのセルを実行すると、モデルの微調整が行われます。さまざまなデータセットを試して、難易度を選択できます。\n",
+ "\n",
+ "\n",
+ "
演習: SFTTrainerを使用したSmolLM2の微調整
\n",
+ "
Hugging Faceのリポジトリからデータセットを取得し、それを使用してモデルを微調整します。
\n",
+ "
難易度レベル
\n",
+ "
🐢 `HuggingFaceTB/smoltalk`データセットを使用
\n",
+ "
🐕 `bigcode/the-stack-smol`データセットを試し、特定のサブセット`data/python`でコード生成モデルを微調整します。
\n",
+ "
🦁 実際の使用ケースに関連するデータセットを選択します。
\n",
+ "
\n",
+ "
追加の演習: 微調整されたモデルでの生成
\n",
+ "
🐕 微調整されたモデルを使用して、ベースモデルの例と同じように応答を生成します。
\n",
+ "
\n",
+ "
演習: SFTTrainerを使用したSmolLM2の微調整
\n",
+ "
Hugging Faceのリポジトリからデータセットを取得し、それを使用してモデルを微調整します。
\n",
+ "
難易度レベル
\n",
+ "
🐢 `HuggingFaceTB/smoltalk`データセットを使用
\n",
+ "
🐕 `bigcode/the-stack-smol`データセットを試し、特定のサブセット`data/python`でコード生成モデルを微調整します。
\n",
+ "
🦁 実際の使用ケースに関連するデータセットを選択します。
\n",
+ "
\n",
+ "
追加の演習: 微調整されたモデルでの生成
\n",
+ "
🐕 微調整されたモデルを使用して、ベースモデルの例と同じように応答を生成します。
\n",
+ "
🐕 独自の選好データセットを使用する
🦁 さまざまな選好データセットとモデルサイズで実験する | [ノートブック](./notebooks/dpo_finetuning_example.ipynb) | |
+| ORPOトレーニング | 選好確率比最適化を使用してモデルをトレーニングする方法を学ぶ | 🐢 指示と選好データを使用してモデルをトレーニングする
🐕 損失の重みを変えて実験する
🦁 ORPOとDPOの結果を比較する | [ノートブック](./notebooks/orpo_finetuning_example.ipynb) | |
+
+## リソース
+
+- [TRLのドキュメント](https://huggingface.co/docs/trl/index) - DPOを含むさまざまな整合技術を実装するためのTransformers Reinforcement Learning(TRL)ライブラリのドキュメント。
+- [DPO論文](https://arxiv.org/abs/2305.18290) - 人間のフィードバックを用いた強化学習の代替として、選好データを使用して言語モデルを直接最適化するシンプルなアプローチを紹介する論文。
+- [ORPO論文](https://arxiv.org/abs/2403.07691) - 指示調整と選好の整合を単一のトレーニングステージに統合する新しいアプローチを紹介する論文。
+- [ArgillaのRLHFガイド](https://argilla.io/blog/mantisnlp-rlhf-part-8/) - RLHF、DPOなどのさまざまな整合技術とその実践的な実装について説明するガイド。
+- [DPOに関するブログ記事](https://huggingface.co/blog/dpo-trl) - TRLライブラリを使用してDPOを実装する方法についての実践ガイド。コード例とベストプラクティスが含まれています。
+- [TRLのDPOスクリプト例](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo.py) - TRLライブラリを使用してDPOトレーニングを実装する方法を示す完全なスクリプト例。
+- [TRLのORPOスクリプト例](https://github.com/huggingface/trl/blob/main/examples/scripts/orpo.py) - TRLライブラリを使用してORPOトレーニングを実装するためのリファレンス実装。詳細な設定オプションが含まれています。
+- [Hugging Faceの整合ハンドブック](https://github.com/huggingface/alignment-handbook) - SFT、DPO、RLHFなどのさまざまな技術を使用して言語モデルを整合させるためのガイドとコード。
diff --git a/ja/2_preference_alignment/dpo.md b/ja/2_preference_alignment/dpo.md
new file mode 100644
index 00000000..6d354d35
--- /dev/null
+++ b/ja/2_preference_alignment/dpo.md
@@ -0,0 +1,73 @@
+**直接選好最適化(DPO)**
+
+直接選好最適化(DPO)は、言語モデルを人間の好みに合わせるための簡素化されたアプローチを提供します。従来のRLHF(人間のフィードバックを用いた強化学習)メソッドとは異なり、DPOは別個の報酬モデルや複雑な強化学習アルゴリズムを必要とせず、選好データを使用してモデルを直接最適化します。
+
+## DPOの理解
+
+DPOは、選好の整合を人間の選好データに基づく分類問題として再定義します。従来のRLHFアプローチでは、別個の報酬モデルをトレーニングし、PPO(近接ポリシー最適化)などの複雑なアルゴリズムを使用してモデルの出力を整合させる必要があります。DPOは、好ましい出力と好ましくない出力に基づいてモデルのポリシーを直接最適化する損失関数を定義することで、このプロセスを簡素化します。
+
+このアプローチは実際に非常に効果的であり、Llamaなどのモデルのトレーニングに使用されています。別個の報酬モデルや強化学習のステージを必要としないため、DPOは選好の整合をよりアクセスしやすく、安定したものにします。
+
+## DPOの仕組み
+
+DPOのプロセスには、ターゲットドメインにモデルを適応させるための教師あり微調整(SFT)が必要です。これにより、標準的な指示追従データセットでトレーニングすることで、選好学習の基盤が形成されます。モデルは基本的なタスクを完了しながら、一般的な能力を維持することを学びます。
+
+次に、選好学習が行われ、モデルは好ましい出力と好ましくない出力のペアでトレーニングされます。選好ペアは、モデルがどの応答が人間の価値観や期待に最も一致するかを理解するのに役立ちます。
+
+DPOの中心的な革新は、その直接最適化アプローチにあります。別個の報酬モデルをトレーニングする代わりに、DPOはバイナリクロスエントロピー損失を使用して、選好データに基づいてモデルの重みを直接更新します。この簡素化されたプロセスにより、トレーニングがより安定し、効率的になり、従来のRLHFメソッドと同等またはそれ以上の結果が得られます。
+
+## DPOのデータセット
+
+DPOのデータセットは、通常、選好または非選好として注釈された応答ペアを含むように作成されます。これは手動で行うか、自動フィルタリング技術を使用して行うことができます。以下は、単一ターンのDPO選好データセットの構造の例です:
+
+| プロンプト | 選好 | 非選好 |
+|--------|---------|-----------|
+| ... | ... | ... |
+| ... | ... | ... |
+| ... | ... | ... |
+
+`Prompt`列には、`選好`および`非選好`の応答を生成するために使用されたプロンプトが含まれています。`選好`および`非選好`列には、それぞれ好ましい応答と好ましくない応答が含まれています。この構造にはバリエーションがあり、例えば、`system_prompt`や`Input`列に参照資料を含めることができます。`選好`および`非選好`の値は、単一ターンの会話の場合は文字列として、または会話リストとして表現されることがあります。
+
+Hugging FaceでDPOデータセットのコレクションを[こちら](https://huggingface.co/collections/argilla/preference-datasets-for-dpo-656f0ce6a00ad2dc33069478)で見つけることができます。
+
+## TRLを使用した実装
+
+Transformers Reinforcement Learning(TRL)ライブラリは、DPOの実装を容易にします。`DPOConfig`および`DPOTrainer`クラスは、`transformers`スタイルのAPIに従います。
+
+以下は、DPOトレーニングを設定する基本的な例です:
+
+```python
+from trl import DPOConfig, DPOTrainer
+
+# 引数を定義
+training_args = DPOConfig(
+ ...
+)
+
+# トレーナーを初期化
+trainer = DPOTrainer(
+ model,
+ train_dataset=dataset,
+ tokenizer=tokenizer,
+ ...
+)
+
+# モデルをトレーニング
+trainer.train()
+```
+
+DPOConfigおよびDPOTrainerクラスの使用方法の詳細については、[DPOチュートリアル](./notebooks/dpo_finetuning_example.ipynb)を参照してください。
+
+## ベストプラクティス
+
+データの品質は、DPOの成功した実装にとって重要です。選好データセットには、望ましい行動のさまざまな側面をカバーする多様な例が含まれている必要があります。明確な注釈ガイドラインは、選好および非選好の応答の一貫したラベル付けを保証します。選好データセットの品質を向上させることで、モデルのパフォーマンスを向上させることができます。例えば、より大きなデータセットをフィルタリングして、高品質の例やユースケースに関連する例のみを含めることができます。
+
+トレーニング中は、損失の収束を慎重に監視し、保持データでパフォーマンスを検証します。選好学習とモデルの一般的な能力の維持をバランスさせるために、ベータパラメータを調整する必要がある場合があります。多様な例での定期的な評価は、モデルが望ましい選好を学習しながら過剰適合しないことを保証するのに役立ちます。
+
+モデルの出力を基準モデルと比較して、選好の整合性の向上を確認します。さまざまなプロンプト、特にエッジケースを使用してモデルをテストすることで、さまざまなシナリオでの選好学習の堅牢性を保証します。
+
+## 次のステップ
+
+⏩ DPOの実践的な経験を得るために、[DPOチュートリアル](./notebooks/dpo_finetuning_example.ipynb)を試してみてください。この実践ガイドでは、データの準備からトレーニングおよび評価まで、選好整合の実装方法を説明します。
+
+⏭️ チュートリアルを完了した後、別の選好整合技術について学ぶために[ORPOページ](./orpo.md)を探索してください。
diff --git a/ja/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb b/ja/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb
new file mode 100644
index 00000000..38f63fde
--- /dev/null
+++ b/ja/2_preference_alignment/notebooks/dpo_finetuning_example.ipynb
@@ -0,0 +1,167 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# DPO微調整の例\n",
+ "\n",
+ "このノートブックでは、`trl`ライブラリを使用してDPO(直接選好最適化)を実行する方法を示します。DPOは、モデルの出力を人間の選好に合わせるためのシンプルで効果的な方法です。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. 環境の設定\n",
+ "\n",
+ "まず、必要なライブラリをインストールし、Hugging Faceにログインします。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Google Colabでの要件のインストール\n",
+ "# !pip install transformers datasets trl huggingface_hub\n",
+ "\n",
+ "# Hugging Faceへの認証\n",
+ "from huggingface_hub import login\n",
+ "\n",
+ "login()\n",
+ "\n",
+ "# 便利のため、Hugging Faceのトークンを.envファイルのHF_TOKENとして環境変数に設定できます"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. モデルとデータセットのロード\n",
+ "\n",
+ "次に、事前学習済みモデルとデータセットをロードします。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from transformers import AutoModelForCausalLM, AutoTokenizer\n",
+ "from datasets import load_dataset\n",
+ "\n",
+ "# モデルとトークナイザーをロード\n",
+ "model_name = \"HuggingFaceTB/SmolLM2-135M\"\n",
+ "model = AutoModelForCausalLM.from_pretrained(model_name)\n",
+ "tokenizer = AutoTokenizer.from_pretrained(model_name)\n",
+ "\n",
+ "# データセットをロード\n",
+ "dataset = load_dataset(\"Anthropic/hh-rlhf\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3. DPOトレーナーの設定\n",
+ "\n",
+ "DPOトレーナーを設定し、トレーニングを開始します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from trl import DPOConfig, DPOTrainer\n",
+ "\n",
+ "# DPOの設定\n",
+ "dpo_config = DPOConfig(\n",
+ " model_name_or_path=model_name,\n",
+ " learning_rate=5e-5,\n",
+ " per_device_train_batch_size=4,\n",
+ " num_train_epochs=3,\n",
+ " logging_steps=10,\n",
+ " save_steps=100,\n",
+ " output_dir=\"./dpo_output\"\n",
+ ")\n",
+ "\n",
+ "# DPOトレーナーを初期化\n",
+ "trainer = DPOTrainer(\n",
+ " model=model,\n",
+ " args=dpo_config,\n",
+ " train_dataset=dataset[\"train\"],\n",
+ " eval_dataset=dataset[\"test\"],\n",
+ " tokenizer=tokenizer\n",
+ ")\n",
+ "\n",
+ "# モデルをトレーニング\n",
+ "trainer.train()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. 微調整されたモデルの保存\n",
+ "\n",
+ "トレーニングが完了したら、微調整されたモデルを保存します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 微調整されたモデルを保存\n",
+ "trainer.save_model(\"./dpo_finetuned_model\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 5. 微調整されたモデルの評価\n",
+ "\n",
+ "最後に、微調整されたモデルを評価します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 評価の実行\n",
+ "results = trainer.evaluate()\n",
+ "print(results)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/ja/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb b/ja/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb
new file mode 100644
index 00000000..e4fc09ca
--- /dev/null
+++ b/ja/2_preference_alignment/notebooks/orpo_finetuning_example.ipynb
@@ -0,0 +1,167 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# ORPO微調整の例\n",
+ "\n",
+ "このノートブックでは、`trl`ライブラリを使用してORPO(選好確率比最適化)を実行する方法を示します。ORPOは、モデルの出力を人間の選好に合わせるためのシンプルで効果的な方法です。"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 1. 環境の設定\n",
+ "\n",
+ "まず、必要なライブラリをインストールし、Hugging Faceにログインします。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# Google Colabでの要件のインストール\n",
+ "# !pip install transformers datasets trl huggingface_hub\n",
+ "\n",
+ "# Hugging Faceへの認証\n",
+ "from huggingface_hub import login\n",
+ "\n",
+ "login()\n",
+ "\n",
+ "# 便利のため、Hugging Faceのトークンを.envファイルのHF_TOKENとして環境変数に設定できます"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 2. モデルとデータセットのロード\n",
+ "\n",
+ "次に、事前学習済みモデルとデータセットをロードします。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from transformers import AutoModelForCausalLM, AutoTokenizer\n",
+ "from datasets import load_dataset\n",
+ "\n",
+ "# モデルとトークナイザーをロード\n",
+ "model_name = \"HuggingFaceTB/SmolLM2-135M\"\n",
+ "model = AutoModelForCausalLM.from_pretrained(model_name)\n",
+ "tokenizer = AutoTokenizer.from_pretrained(model_name)\n",
+ "\n",
+ "# データセットをロード\n",
+ "dataset = load_dataset(\"Anthropic/hh-rlhf\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 3. ORPOトレーナーの設定\n",
+ "\n",
+ "ORPOトレーナーを設定し、トレーニングを開始します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from trl import ORPOConfig, ORPOTrainer\n",
+ "\n",
+ "# ORPOの設定\n",
+ "orpo_config = ORPOConfig(\n",
+ " model_name_or_path=model_name,\n",
+ " learning_rate=5e-5,\n",
+ " per_device_train_batch_size=4,\n",
+ " num_train_epochs=3,\n",
+ " logging_steps=10,\n",
+ " save_steps=100,\n",
+ " output_dir=\"./orpo_output\"\n",
+ ")\n",
+ "\n",
+ "# ORPOトレーナーを初期化\n",
+ "trainer = ORPOTrainer(\n",
+ " model=model,\n",
+ " args=orpo_config,\n",
+ " train_dataset=dataset[\"train\"],\n",
+ " eval_dataset=dataset[\"test\"],\n",
+ " tokenizer=tokenizer\n",
+ ")\n",
+ "\n",
+ "# モデルをトレーニング\n",
+ "trainer.train()"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 4. 微調整されたモデルの保存\n",
+ "\n",
+ "トレーニングが完了したら、微調整されたモデルを保存します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 微調整されたモデルを保存\n",
+ "trainer.save_model(\"./orpo_finetuned_model\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## 5. 微調整されたモデルの評価\n",
+ "\n",
+ "最後に、微調整されたモデルを評価します。"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "# 評価の実行\n",
+ "results = trainer.evaluate()\n",
+ "print(results)"
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "Python 3",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.8.8"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 5
+}
diff --git a/ja/2_preference_alignment/orpo.md b/ja/2_preference_alignment/orpo.md
new file mode 100644
index 00000000..ac3a4af6
--- /dev/null
+++ b/ja/2_preference_alignment/orpo.md
@@ -0,0 +1,83 @@
+**選好確率比最適化(ORPO)**
+
+選好確率比最適化(ORPO)は、微調整と選好整合を単一の統合プロセスで組み合わせる新しいアプローチです。この統合アプローチは、従来のRLHFやDPOなどの方法と比較して、効率とパフォーマンスの面で利点を提供します。
+
+## ORPOの理解
+
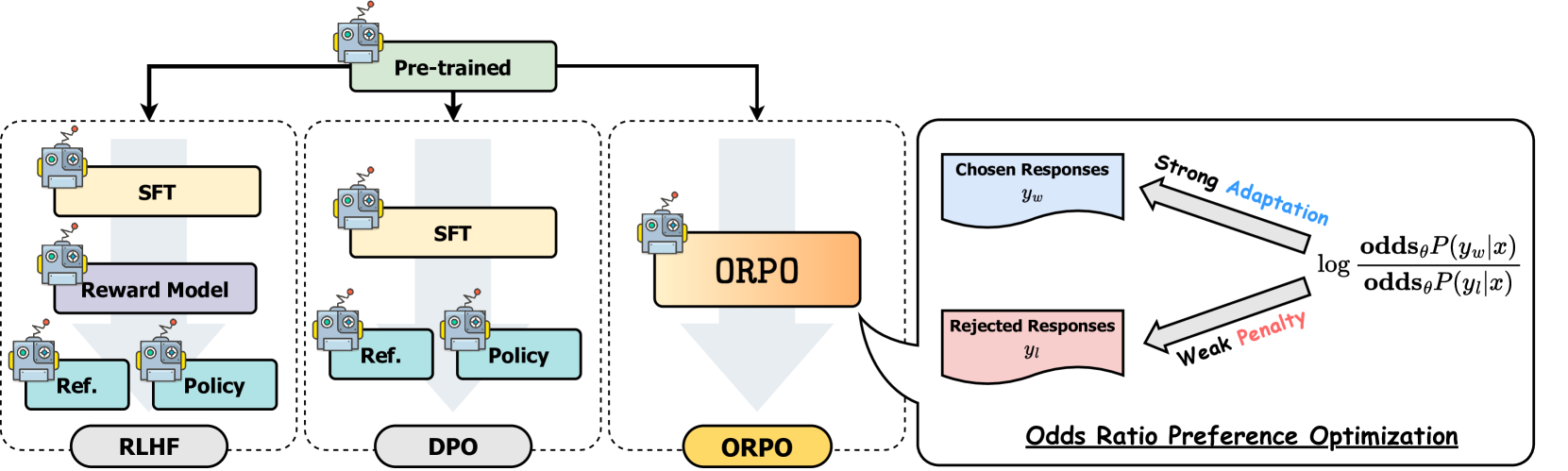
+DPOのような選好整合方法は、通常、微調整と選好整合の2つの別々のステップを含みます。微調整はモデルを特定のドメインや形式に適応させ、選好整合は人間の選好に合わせて出力を調整します。SFT(教師あり微調整)は、モデルをターゲットドメインに適応させるのに効果的ですが、望ましい応答と望ましくない応答の両方の確率を増加させる可能性があります。ORPOは、以下の比較図に示すように、これらのステップを単一のプロセスに統合することで、この制限に対処します。
+
+
+*モデル整合技術の比較*
+
+## ORPOの仕組み
+
+ORPOのトレーニングプロセスは、DPOと同様に、入力プロンプトと2つの応答(1つは選好、もう1つは非選好)を含む選好データセットを使用します。他の整合方法とは異なり、ORPOは選好整合を教師あり微調整プロセスに直接統合します。この統合アプローチにより、参照モデルが不要になり、計算効率とメモリ効率が向上し、FLOP数が減少します。
+
+ORPOは、次の2つの主要なコンポーネントを組み合わせて新しい目的を作成します:
+
+1. **SFT損失**:負の対数尤度損失を使用して、参照トークンの生成確率を最大化します。これにより、モデルの一般的な言語能力が維持されます。
+2. **オッズ比損失**:望ましくない応答をペナルティし、選好される応答を報酬する新しいコンポーネントです。この損失関数は、トークンレベルで選好される応答と非選好の応答を効果的に対比するためにオッズ比を使用します。
+
+これらのコンポーネントを組み合わせることで、モデルは特定のドメインに対して望ましい生成を適応させながら、非選好の応答を積極的に抑制します。オッズ比メカニズムは、選好された応答と拒否された応答の間のモデルの選好を測定および最適化する自然な方法を提供します。数学的な詳細については、[ORPO論文](https://arxiv.org/abs/2403.07691)を参照してください。実装の観点からORPOについて学びたい場合は、[TRLライブラリ](https://github.com/huggingface/trl/blob/b02189aaa538f3a95f6abb0ab46c0a971bfde57e/trl/trainer/orpo_trainer.py#L660)でORPO損失がどのように計算されるかを確認してください。
+
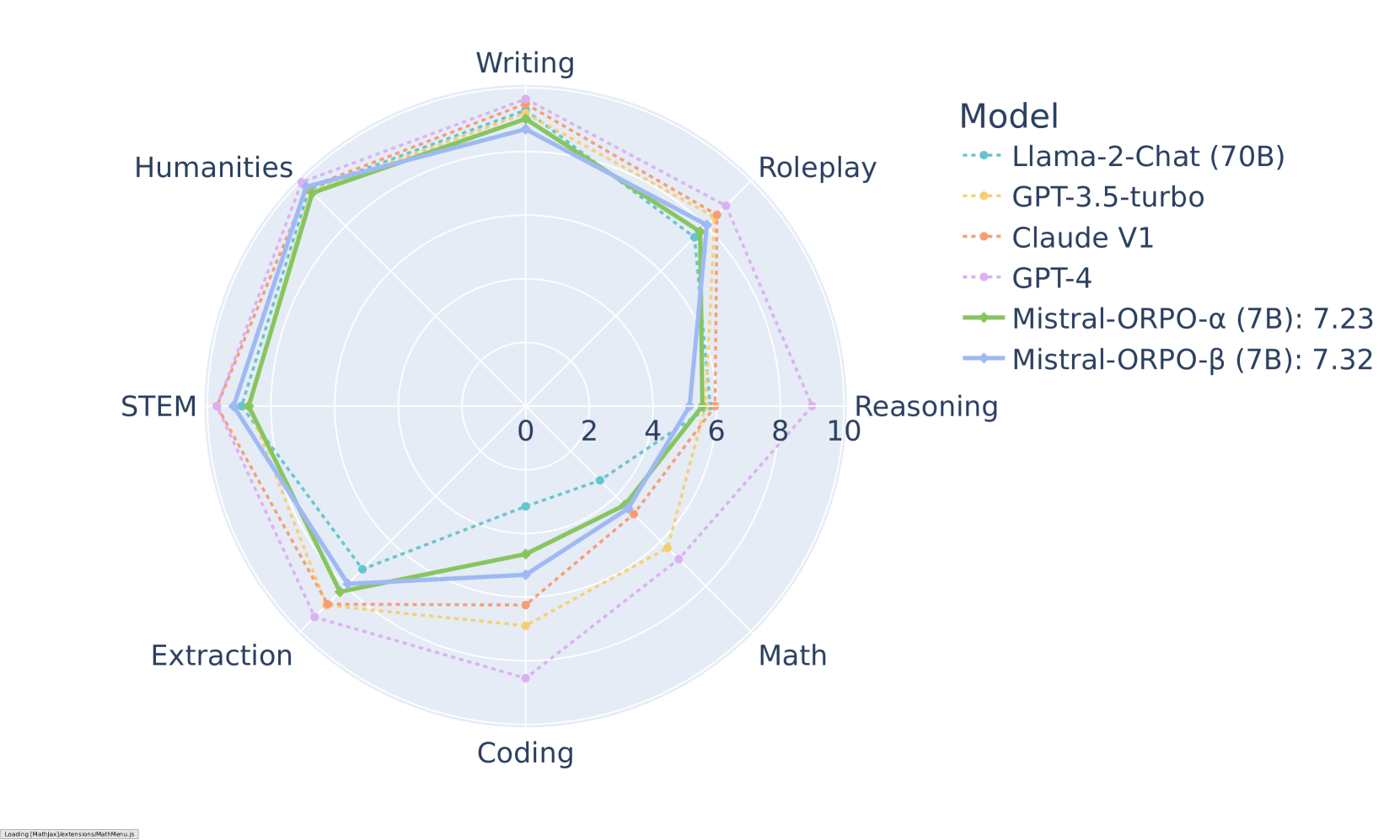
+## パフォーマンスと結果
+
+ORPOは、さまざまなベンチマークで印象的な結果を示しています。MT-Benchでは、さまざまなカテゴリで競争力のあるスコアを達成しています:
+
+
+*MT-Benchのカテゴリ別結果(Mistral-ORPOモデル)*
+
+他の整合方法と比較すると、ORPOはAlpacaEval 2.0で優れたパフォーマンスを示しています:
+
+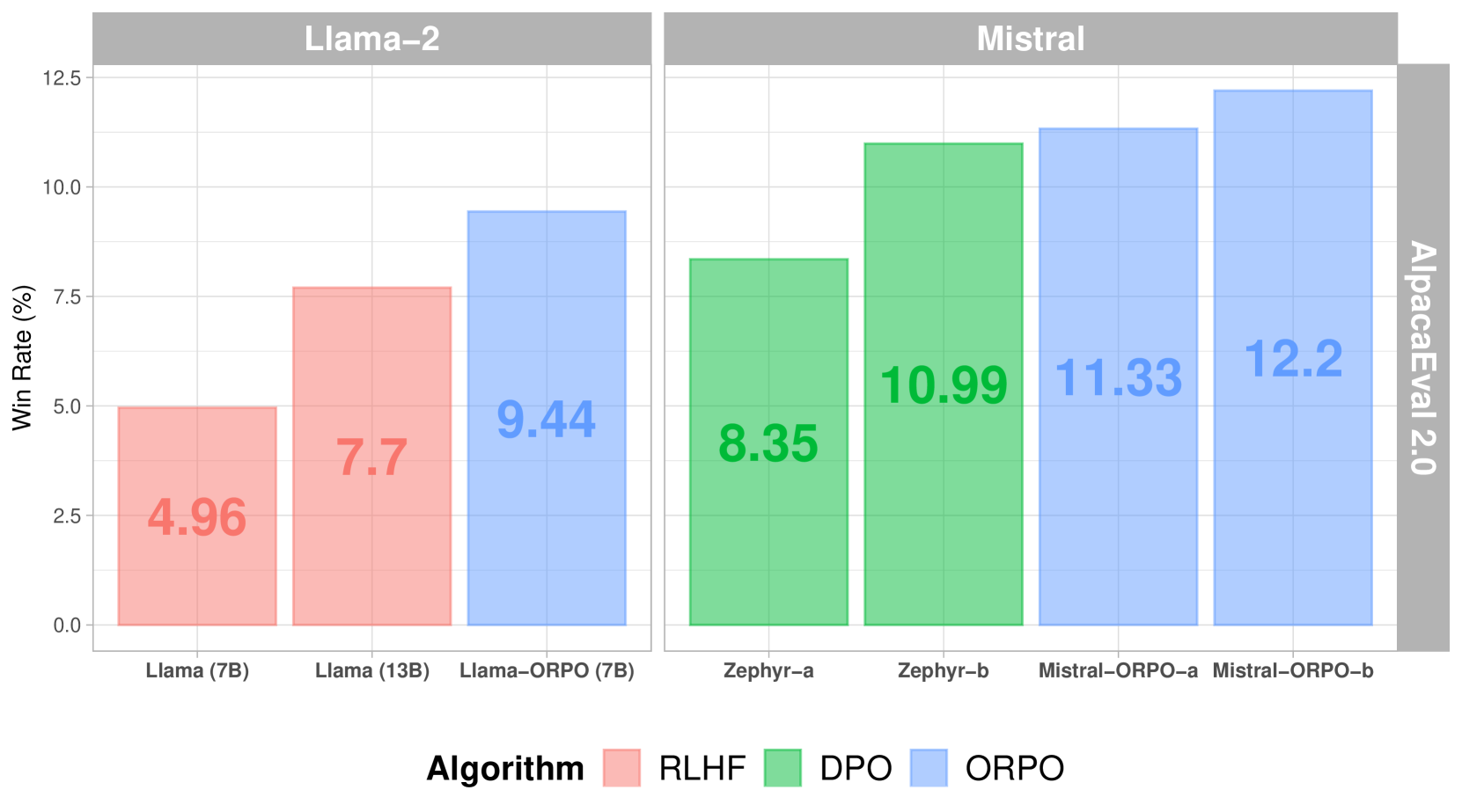
+*さまざまな整合方法におけるAlpacaEval 2.0スコア*
+
+SFT+DPOと比較して、ORPOは参照モデルが不要であり、バッチごとのフォワードパスの数を半減させることで計算要件を削減します。さらに、トレーニングプロセスは、さまざまなモデルサイズとデータセットでより安定しており、調整するハイパーパラメータが少なくて済みます。パフォーマンスに関しては、ORPOはより大きなモデルと同等のパフォーマンスを示しながら、人間の選好に対する整合性が向上しています。
+
+## 実装
+
+ORPOの成功した実装は、高品質の選好データに大きく依存します。トレーニングデータは明確な注釈ガイドラインに従い、さまざまなシナリオで好ましい応答と拒否された応答のバランスの取れた表現を提供する必要があります。
+
+### TRLを使用した実装
+
+ORPOは、Transformers Reinforcement Learning(TRL)ライブラリを使用して実装できます。以下は基本的な例です:
+
+```python
+from trl import ORPOConfig, ORPOTrainer
+
+# ORPOトレーニングの設定
+orpo_config = ORPOConfig(
+ learning_rate=1e-5,
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ max_steps=1000,
+ orpo_alpha=1.0, # 選好最適化の強度を制御
+ orpo_beta=0.1, # オッズ比計算の温度パラメータ
+)
+
+# トレーナーを初期化
+trainer = ORPOTrainer(
+ model=model,
+ args=orpo_config,
+ train_dataset=dataset,
+ tokenizer=tokenizer,
+)
+
+# トレーニングを開始
+trainer.train()
+```
+
+考慮すべき主要なパラメータ:
+- `orpo_alpha`:選好最適化の強度を制御
+- `orpo_beta`:オッズ比計算の温度パラメータ
+- `learning_rate`:忘却のカタストロフィーを避けるために比較的小さく設定
+- `gradient_accumulation_steps`:トレーニングの安定性を向上
+
+## 次のステップ
+
+⏩ この統合された選好整合アプローチを実装するための[ORPOチュートリアル](./notebooks/orpo_tutorial.ipynb)を試してみてください。
+
+## リソース
+- [ORPO論文](https://arxiv.org/abs/2403.07691)
+- [TRLドキュメント](https://huggingface.co/docs/trl/index)
+- [ArgillaのRLHFガイド](https://argilla.io/blog/mantisnlp-rlhf-part-8/)