langdb_udf adds support for AI operations directly within ClickHouse through User Defined Functions (UDFs). This enables running AI completions and embeddings natively in your SQL queries.
ai_completions: Generate AI completions from various modelsai_embed: Create embeddings from text
LangDB UDFs are particularly powerful for running LLM-based evaluations and analysis directly within your ClickHouse environment:
- Native Integration: Run AI operations directly in SQL queries without data movement
- Batch Processing: Efficiently process and analyze large datasets with LLMs
- Real-time Analysis: Perform content moderation, sentiment analysis, and other AI tasks as part of your data pipeline
- Model Comparison: Easily compare results across different LLM models in a single query
- Scalability: Leverage ClickHouse's distributed architecture for parallel AI processing
-
Get your LangDB credentials:
- Sign up at LangDB
- Get your
LANGDB_PROJECT_IDandLANGDB_API_KEY
-
Set up environment variables:
export LANGDB_PROJECT_ID=your_project_id
export LANGDB_API_KEY=your_api_key# Clone the repository
git clone [email protected]:langdb/ai-gateway.git
cd ai-gateway
# Create directory for ClickHouse user scripts
mkdir -p docker/clickhouse/user_scripts
# Download the latest UDF
curl -sL https://github.com/langdb/ai-gateway/releases/download/0.1.0/langdb_udf \
-o docker/clickhouse/user_scripts/langdb_udf
# Start ClickHouse with LangDB UDF
docker compose up -dBasic example with system prompt:
-- Set system prompt
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value sentiment score between 1 and 5 for every input and nothing else.';
-- Run completion
SELECT ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000}')
({system_prompt:String}, 'You are very rude') as scoreYou can specify additional parameters like thread_id and run_id:
-- Set parameters
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value sentiment score between 1 and 5 for every input and nothing else.';
-- Generate UUIDs for tracking
SELECT generateUUIDv4();
SET param_thread_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
SET param_run_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
-- Run completion with parameters
SELECT ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, 'You are very rude') as scoreGenerate embeddings from text:
SELECT ai_embed('{"model":"text-embedding-3-small"}')('Life is beautiful') as embed_textThis example shows how to score HackerNews comments for harmful content:
-- Create and populate table
CREATE TABLE hackernews
ENGINE = MergeTree
ORDER BY id
SETTINGS allow_nullable_key = 1 EMPTY AS
SELECT *
FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.parquet', 'Parquet');
-- Insert sample data
INSERT INTO hackernews SELECT *
FROM url('https://datasets-documentation.s3.eu-west-3.amazonaws.com/hackernews/hacknernews.parquet', 'Parquet')
LIMIT 100;
-- Set up parameters
SET param_system_prompt = 'You are a helpful assistant. You will return only a single value score between 1 and 5 for every input and nothing else based on malicious behavior. 0 being ok, 5 being the most harmful';
SET param_thread_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
SET param_run_id = '06b66882-e42e-4b17-ba93-4b5260a10ad8';
-- Score content using multiple models
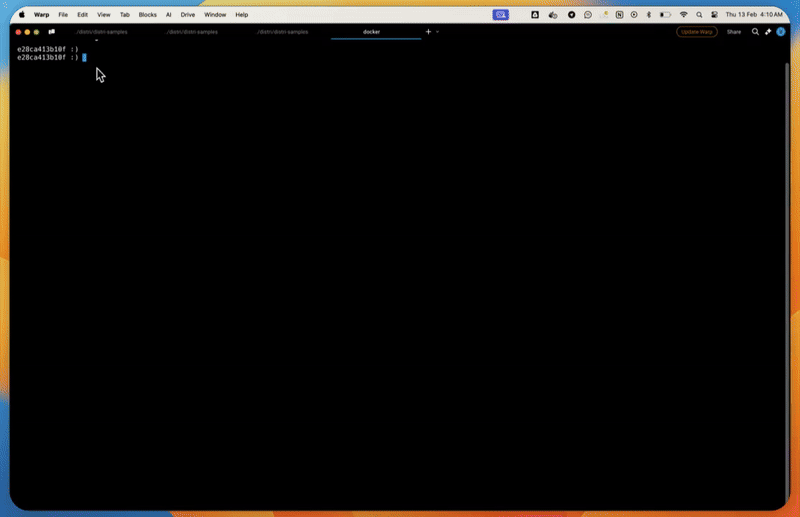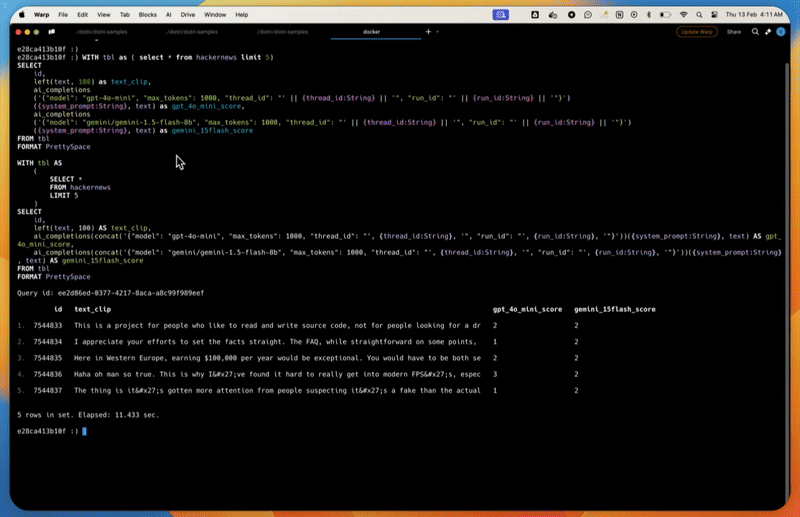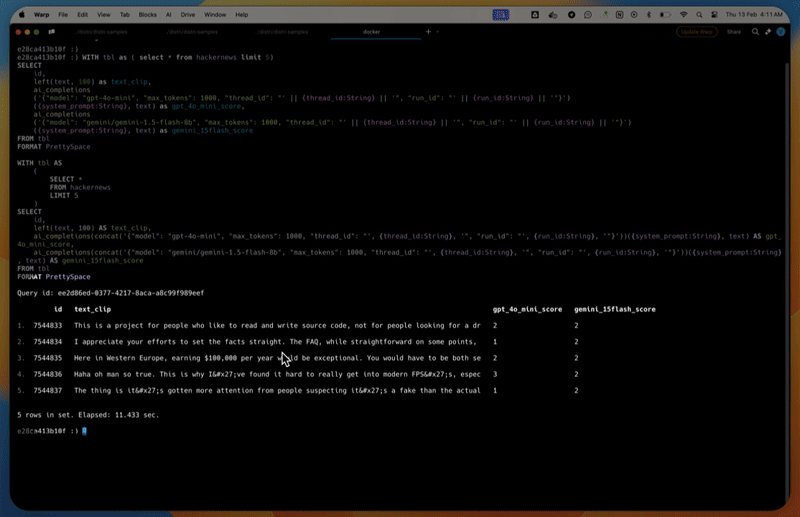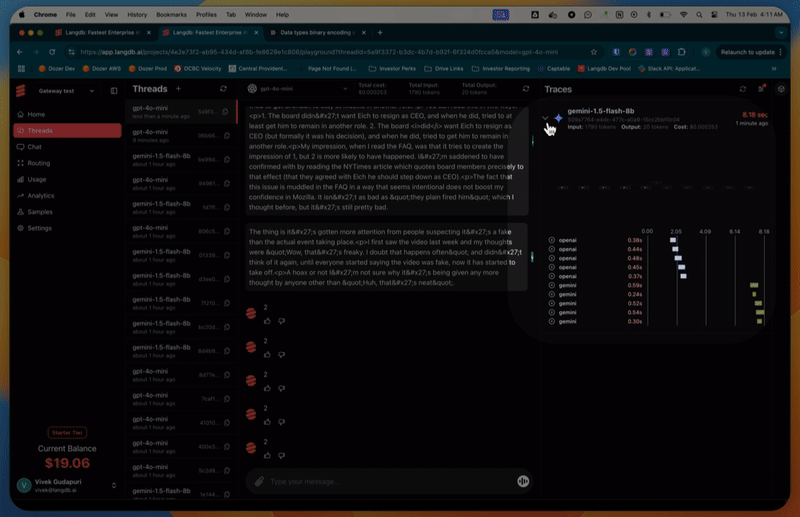
WITH tbl as ( select * from hackernews limit 5)
SELECT
id,
left(text, 100) as text_clip,
ai_completions
('{"model": "gpt-4o-mini", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, text) as gpt_4o_mini_score,
ai_completions
('{"model": "gemini/gemini-1.5-flash-8b", "max_tokens": 1000, "thread_id": "' || {thread_id:String} || '", "run_id": "' || {run_id:String} || '"}')
({system_prompt:String}, text) as gemini_15flash_score
FROM tbl
FORMAT PrettySpaceid text_clip gpt_4o_mini_score gemini_15flash_score
1. 7544833 This is a project for people who like to read and 2 2
2. 7544834 I appreciate your efforts to set the facts straigh 2 2
3. 7544835 Here in Western Europe, earning $100,000 per year 1 2
4. 7544836 Haha oh man so true. This is why I've found i 3 2
5. 7544837 The thing is it's gotten more attention from 1 2