The Statistical Variable Menu used for the Scatter Plot Explorer, Timelines Explorer, and Map Explorer was revamped to serve a much more comprehensive list of over 287000 statistical variables in an easy to consume way. This new menu comes with useful features such as search support and information on the places that each statistical variable has data for.
+
+
New Data
+
We’ve continued to add new data to the Data Commons graph. Some of these new additions include:
Today, we are excited to share that Data Commons is accessible via natural language queries in Google search. At a time when data informs our understanding of so many issues–from public health and education to the evolving workforce and more–access to data has never been more important. Data Commons in Google search is a step in this direction, enabling users to explore data without the need for expertise or programming skills.
+
+
Three years ago, the Data Commons journey started at Google with a simple observation: our ability to use data to understand our world is frequently hampered by the difficulties in working with data. The difficulties of finding, cleaning and joining datasets effectively limit who gets to work with data.
+
+
Data Commons addresses this challenge head on, performing the tedious tasks of curating, joining and cleaning data sets at scale so that data users don’t have to. The result? Large scale and cloud accessible APIs to clean and normalize data originating from some of the most widely used datasets, including those from the US Census, World Bank, CDC and more. Available as a layer on top of the Knowledge Graph, Data Commons is now accessible to a much wider audience.
+
+
Data Commons is Open. Open Data, Open Source. We hope that like its elder sister Schema.org, it becomes one of the foundational layers of the Web. We know this can only happen if it is built in an open and collaborative fashion. We are actively looking for partnerships on every aspect of this project, and we look forward to hearing from you!
Over the past few months, we’ve continued to incorporate new data into our knowledge graph and develop new tools. Here are some of the highlights:
+
+
New Statistical Variable Explorer
+
As Data Commons has grown, the number of Statistical Variables has increased. With over 300k variables to choose from (and counting!), we wanted to make it easier for you to find the right variables for your analysis. To address this, we added a new tool for exploring Statistical Variables. The tool provides metadata about the observations, places, and provenances we have for each variable.
+
+
New Data
+
Lately, we’ve been focused on building up our inventory of sustainability-related data. Some of recent our imports include:
We’re also in the process of importing a large number of US Census American Community Survey Subject Tables, which contain detailed demographic data about a variety of topics. For example:
We’ve made it easier for contributors to add datasets to Data Commons with our new open source command-line tool. This tool provides linting and detailed stats validation, streamlining our data ingestion process and making it more accessible.
Data Commons now includes 100+ sources of Sustainability data, covering topics from climate predictions (CMIP 5 and CMIP 6) from NASA, emissions from EPA, energy from EIA, NREL and UN, disasters from USGS and USFS, health from CDC and more. You can learn more about the launch of Sustainability Data Commons on the Google Keyword Blog.
In the last year, we have added several interesting datasets and exciting new features to Data Commons. One such feature is the new Data Download tool that allows you to easily download statistical variable data for a large number of places with just a few button clicks.
+
+
+
+
The Data Commons knowledge graph is huge – there are over 240B data points for over 120K statistical variables. Sometimes, you may want to export just some of this data and use it in a custom tool. We now make that easy to do with the new data download tool. The new tool gives you the data in a csv file, does not require any coding experience to use, and allows you to select the statistical variables, places, and dates that you are interested in.
+
+
Maybe you want to explore the population of all the countries in the world (get the data here). Or you want to analyze poverty levels during COVID-19 (get the data here). Or you’re interested in projected temperature differences (relative to 2006) and activities that can be affected by temperature rise (get the data here). The Data Download tool gives you the power to use the data in our knowledge graph to explore all of this and much more in your tool of choice.
+
+
As always, we would love to hear from you! Please share your feedback with our team.
+ 28 Dec 2022 – Crystal Wang, Jehangir Amjad, and Julia Wu
+
New Courseware - Data Literacy with Data Commons
+
+
tl;dr
+
+
Today, we are announcing the open and public availability of “Data Literacy with Data Commons” which comprises curriculum/course materials for instructors, students and other practitioners working on or helping others become data literate. This includes detailed modules with pedagogical narratives, explanations of key concepts, examples, and suggestions for exercises/projects focused on advancing the consumption, understanding and interpretation of data in the contemporary world. In our quest to expand the reach and utility of this material, we assume no background in computer science or programming, thereby removing a key obstacle to many such endeavors.
+
+
This material can be accessed on our courseware page and it is open for anyone to take advantage of. If you use any of this material, we would love to hear from you! If you end up finding any of this material useful and would like to be notified of updates, do drop us a line.
+
+
What is it?
+
+
A set of modules focusing on several key concepts focusing on data modeling, analysis, visualization and the (ab)use of data to tell (false) narratives. Each module lists its objectives and builds on a pedagogical narrative around the explanation of key concepts, e.g. the differences between correlations and causation. We extensively use the Data Commons platform to point to real world examples without needing to write a single line of code!
+
+
Who is this for?
+
+
Anyone and everyone. Instructors, students, aspiring data scientists and anyone interested in advancing their data comprehension and analysis skills without needing to code. For instructors, the curriculum page details the curriculum organization and how to find key concepts/ideas to use.
+
+
What’s Different?
+
+
There are several excellent courses which range from basic data analysis to advanced data science. We make no claim about “Data Literacy with Data Commons” being a replacement for them. Instead, we hope for this curriculum to become a useful starting point for those who want to whet their appetite in becoming data literate. This material uses a hands on approach, replete with real world examples but without requiring any programming. It also assumes only a high-school level of comfort with math and statistics. Data Commons is a natural companion platform to enable easy access to data and core visualizations. We hope that anyone exploring the suggested examples will rapidly be able to explore more and even generate new examples and case studies on their own! If you end up finding and exploring new examples and case studies, please share them with us through this form.
+
+
What is Data Literacy?
+
+
What does it mean to be “data literate”? Unsurprisingly, the answer depends on who one asks: from those who believe it implies being a casual consumer of data visualizations (in the media, for example) to those who believe that such a person ought to be able to run linear regressions on large volumes of data in a spreadsheet. Given that most (or all) of us are proliferate consumers of data, we take an opinionated approach to defining “data literacy”: someone who is data literate ought to be comfortable with consuming data across a wide range of modalities and be able to interpret it to make informed decisions. And we believe that data literacy ought not to be exclusionary and should be accessible to anyone and everyone.
+
+
There is no shortage of data all around us. While some of it will always be beyond the comprehension of most of us, e.g. advanced clinical trials data about new drugs under development or data reporting the inner workings of complex systems like satellites, much of the data we consume is not as complex and should not need advanced degrees to consume and decipher. For example, the promise of hundreds of dollars in savings when switching insurance providers or that nine out of ten dentists recommend a particular brand of toothpaste or that different segments of the society (men, women, youth, veterans etc) tend to vote a certain way on specific issues. We consume this data regularly and being able to interpret it to draw sound conclusions ought not to require advanced statistics.
+
+
Unfortunately, data literacy has been an elusive goal for many because it has been gated on relative comfort with programming or programming-like skills, e.g. spreadsheets. We believe data literacy should be more inclusive and require fewer prerequisites. There is no hiding from a basic familiarity with statistics, e.g. knowing how to take a sample average—after all, interpreting data is a sStatistical exercise. However, for a large majority of us the consumption, interpretation and decision-making based on data does not need a working knowledge of computer science (programming).
+
+
As a summary, our view on “Data Literacy” can be described as follows:
+
+
+
Ability to consume, understand, create, and communicate with data.
+
Ability to make decisions based on data.
+
And to do so confidently, i.e. reduce “data anxiety”.
+
A skill for everyone, not just “data scientists”.
+
+
+
With these goals in mind, we hope that this introductory curriculum can help the target audiences towards achieving data literacy and inspire many to dive deeper and farther to become data analysts and scientists.
+
+
Crystal, Jehangir, and Julia, on behalf of the Data Commons team
Data Commons is now harnessing the power of AI, specifically large language models (LLMs), to create a natural language interface. LLMs are used to understand the query and the results come straight from Data Commons, including a link to the original data source.
+
+
+
+
+
+
+
+
+
diff --git a/CNAME b/CNAME
new file mode 100644
index 000000000..bfaa8980f
--- /dev/null
+++ b/CNAME
@@ -0,0 +1 @@
+docs.datacommons.org
\ No newline at end of file
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
new file mode 100644
index 000000000..3a025f83c
--- /dev/null
+++ b/CONTRIBUTING.md
@@ -0,0 +1,28 @@
+# How to contribute
+
+We'd love to accept your patches and contributions to this project. There are
+just a few small guidelines you need to follow.
+
+## Contributor license agreement
+
+Contributions to this project must be accompanied by a Contributor License
+Agreement. You (or your employer) retain the copyright to your contribution;
+this simply gives us permission to use and redistribute your contributions as
+part of the project. Head over to to see
+your current agreements on file or to sign a new one.
+
+You generally only need to submit a CLA once, so if you've already submitted one
+(even if it was for a different project), you probably don't need to do it
+again.
+
+## Code reviews
+
+All submissions, including submissions by project members, require review. We
+use GitHub pull requests for this purpose. Consult
+[GitHub Help](https://help.github.com/articles/about-pull-requests/) for more
+information on using pull requests.
+
+## Community guidelines
+
+This project follows [Google's Open Source Community
+Guidelines](https://opensource.google/conduct/).
\ No newline at end of file
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 000000000..7a4a3ea24
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,202 @@
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
\ No newline at end of file
diff --git a/LICENSE-CC4 b/LICENSE-CC4
new file mode 100644
index 000000000..c8c890405
--- /dev/null
+++ b/LICENSE-CC4
@@ -0,0 +1,7 @@
+Copyright 2023 Google LLC
+
+The non-source code materials in this project are licensed under:
+Creative Commons - Attribution CC-BY 4.0
+
+For the full license text, please visit:
+https://creativecommons.org/licenses/by/4.0/legalcode
diff --git a/README.md b/README.md
new file mode 100644
index 000000000..48f305e6c
--- /dev/null
+++ b/README.md
@@ -0,0 +1,97 @@
+[](https://github.com/datacommonsorg/docsite/actions/workflows/github-pages.yml)
+
+# Data Commons documentation site
+
+This repo hosts Data Commons API documentation
+available at https://docs.datacommons.org/. The site is hosted in [Github Pages](https://pages.github.com/), and generated by [Jekyll](https://jekyllrb.com/).
+
+## About Data Commons
+
+[Data Commons](https://datacommons.org/) is an open knowledge graph that
+provides a unified view across multiple public data sets and statistics.
+We've bootstrapped the graph with lots of
+[data](https://datacommons.org/datasets) from US Census, CDC, NOAA, etc.,
+and through collaborations with the New York Botanical Garden,
+Opportunity Insights, and more. However, Data Commons is
+meant to be for community, by the community. We're excited to work with you
+to make public data accessible to everyone.
+
+To see the extent of data we have today, [browse the Knowledge Graph](https://datacommons.org/browser).
+
+## Markdown
+
+The Data Commons documentation uses [Kramdown](https://kramdown.gettalong.org/syntax.html) Markdown.
+
+## Navigation
+
+The navigation bar is generated automatically from the YAML "front matter" at the top of each Markdown file. See [Using YAML front matter](https://docs.github.com/en/contributing/writing-for-github-docs/using-yaml-frontmatter) for details.
+
+## Build locally
+
+The documentation site is built using Jekyll. To run this locally:
+
+1. One-time setup step: Install [Ruby](https://jekyllrb.com/docs/installation/).
+1. Run `bundle update`
+1. Run `bundle exec jekyll serve --incremental`
+
+You can continue to make local changes and just refresh the browser. You will need to rerun `bundle exec jekyll serve` if you make changes that affect the overall site, such as changes to YAML files, cross-page links, etc.
+
+Tip: If you want to make the staged site accessible to others (and not just on the loopback), add `--host 0.0.0.0` to the command. Then, users can access the site using the hostname of the machine where the site is running.
+
+## License
+
+Apache 2.0
+
+## Contribute changes
+
+### One-time setup steps
+
+1. In https://github.com/datacommonsorg/docsite, click the **Fork** button to fork the repo.
+1. Clone your forked repo to your desktop:
+
+
+
+Then, in github.com, in your forked repo, you can send a pull request. You will need to assign at least one reviewer to approve.
+
+If this is your first
+time contributing to a Google Open Source project, you may need to follow the
+steps in [CONTRIBUTING.md](CONTRIBUTING.md). Be sure to follow [the style guide](STYLE_GUIDE.md)
+when submitting documentation PRs.
+
+Wait for approval of the pull request and merge the change.
+
+## Support
+
+For general questions or issues, please open an issue on our
+[issues](https://github.com/datacommonsorg/docsite/issues) page. For all other
+questions, please [send us feedback](https://docs.google.com/forms/d/e/1FAIpQLScJTtNlIItT-uSPXI98WT6yNlavF-kf5JS0jMrCvJ9TPLmelg/viewform).
+
+> **Note** - This is not an officially supported Google product.
diff --git a/api/index.html b/api/index.html
new file mode 100644
index 000000000..23d6e6af4
--- /dev/null
+++ b/api/index.html
@@ -0,0 +1,596 @@
+
+
+
+
+ API - Query data programmatically - Docs - Data Commons
+
+
+
+
+
+
+
+
+
+
+
+
+
Data Commons aggregates data from many
+different data sources into a single
+database. Data Commons is based on the data model used by
+schema.org; for more information, see Key concepts.
+
+
The Data Commons APIs allow developers to programmatically access the data in Data Commons, using the following technologies:
+
+
+
A REST API that can be used on the command line as well as in any language with an HTTP library.
Note: The Python and Pandas APIs wrap the V1 version of the REST APIs and have not yet been updated to V2.
+
+
+
The endpoints can be roughly grouped into four categories:
+
+
+
+
Statistical data: Given a set of statistical variables, dates and entities, get observations.
+
+
+
Graph exploration: Given a set of nodes, explore the
+graph around those nodes.
+
+
+
Graph query/SPARQL: Given a subgraph where some of the nodes are
+variables, retrieve possible matches. This corresponds to a subset of the
+graph query language SPARQL. This is useful for complex node connections which would require multiple API calls; for example, “hate crimes motivated by disability status in Californian cities”.
+
+
+
Utilities: These are Python notebook-specific APIs for helping with
+Pandas DataFrames, etc.
+
+
+
+
In addition, Data Commons provides additional tools for accessing its data that call the REST APIs under the hood:
+
+
+
Google Sheets: provides several custom functions that populate spreadsheets with data from the Data Commons knowledge graph
+
Web Components: provides JavaScript APIs and HTML templates that allow you to embed Data Commons data and visualizations into web pages
+
+
+
API keys
+
+
A key is required by some APIs to authenticate and authorize requests.
+
+
All REST V2 and V1 APIs. These requests are served by endpoints at api.datacommons.org.
+
All requests coming from a custom Data Commons instance. These are also served by api.datacommons.org.
+
Data Commons NL API requests (used by the DataGemma tool). These are served by endpoints at nl.datacommons.org.
+
+
+
A key is currently not required for the following, although this may change in the future:
+
+
Python and Pandas client libraries other than NL APIs
+
V0 REST APIs
+
Google Sheets
+
Web Components
+
+
+
Obtain an API key
+
+
Data Commons API keys are managed by a self-service portal. To obtain an API key, go to https://apikeys.datacommons.org and request a key for the hostname(s) listed above. Enable each of the APIs you want; you can share a single key for all of them.
+
+
To use the key in requests, see the relevant documentation:
The Data Commons Pandas API is a superset of the Data Commons Python API:
+all functions from the Python API are also accessible from
+the Pandas API, and supplemental functions help with directly creating
+pandas
+objects using data from the Data Commons knowledge graph for common
+use cases.
+
+
+
Note: The Pandas API only supports V1 of the REST APIs.
+
+
+
Before proceeding, make sure you have followed the setup instructions below.
You are ready to go! You can view our tutorials on how to use the
+API to perform certain tasks using Google Colab, or refer to pages in the navigation bar for detailed information about all the methods available.
+
+
Run Python interactively
+
+
The pages in this site demonstrate running the Pandas methods interactively from the Bash shell. To use this facility, be sure to import the datacommons_pandas package:
Returns a pandas.DataFrame with places
+as index and stat_vars
+as columns, where each cell is latest observed statistic for
+its Place and StatisticalVariable.
NOTE: In Data Commons, dcid stands for Data Commons ID and indicates the unique identifier assigned to every node in the knowledge graph.
+
+
Assembling the information you will need for a call to the build_multivariate_dataframe method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
places: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the nodes of interest.
+
+
+
stat_vars: This argument specifies the types of places sought in the response. For example, when examining places contained within American States, you would be able to select City or County (among others). For a full list of available types, see subClassOf Place.
+
+
+
+
Example: Compare the historic populations, median ages, and unemployment rates of the US, California, and Santa Clara County.
If a nonexistent place is passed as an argument, it will not render in the dataframe. In the following example, “geoId/123123123123123123” is one such nonexistent place.
NOTE: In Data Commons, dcid stands for Data Commons ID and indicates the unique identifier assigned to every node in the knowledge graph.
+
+
Assembling the information you will need for a call to the build_time_series method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
+
stat_var: The statistical variable whose value you are interested in.
+
+
+
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
measurement_method: The technique used for measuring a statistical variable.
scaling_factor: Property of statistical variables indicating factor by which a measurement is multiplied to fit a certain format.
+
+
+
+
Note that specifying arguments that do not exist for the target place and variable will result in an empty response. For more information on any of these arguments, check out the glossary.
+
+
Examples
+
+
Example 1: Retrieve the count of men in the state of California.
Returns a pandas.DataFrame with places
+as index and dates as columns, where each cell is the observed statistic for
+its place and date for the
+stat_var.
NOTE: In Data Commons, dcid stands for Data Commons ID and indicates the unique identifier assigned to every node in the knowledge graph.
+
+
Assembling the information you will need for a call to the build_time_series method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
places: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the places of interest.
+
+
+
stat_var: This argument specifies the statistical variable whose measurement you seek.
The Data Commons Python API is a Python library that enables developers to
+programmatically access nodes in the Data Commons knowledge graph. This package
+allows users to explore the structure of the graph, integrate statistics from
+the graph into data analysis workflows and much more.
+
+
+
Note: The Python API only supports V1 of the REST APIs.
+
+
+
Before proceeding, make sure you have followed the setup instructions below.
You are ready to go! You can view our tutorials on how to use the
+API to perform certain tasks using Google Colab, or refer to pages in the navigation bar for detailed information about all the methods available.
+
+
Run Python interactively
+
+
The pages in this site demonstrate running Python methods interactively from the Bash shell. To use this facility, be sure to import the datacommons package:
dcids: A list of nodes to query, identified by their DCID.
+
place_type: The type of the contained child Places within the given
+DCIDs to filter by.
+
+
+
Assembling the information you will need for a call to the get_places_in method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
dcids: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the nodes of interest. More information about DCIDs is available in the glossary.
+
+
+
place_type: This argument specifies the type of place sought in the response. For example, when examining places contained within American States, you would be able to select City or County (among others). For a full list of available types, see the place types page.
+
+
+
+
What to expect in the function return
+
+
The method’s return value will always be a dict in the following form:
+
+
{
+ "<dcid>":["string",...]
+ ...
+}
+
+
+
Example requests and responses
+
+
Example 1: Retrieve a list of all counties in Delaware.
Returns the labels of properties defined for the given node DCIDs.
+
+
General information about this method
+
+
Signature:
+
datacommons.get_property_labels(dcids,out=True)
+
+
+
Required arguments:
+
+
+
dcids: A list of nodes to query, identified by their DCID.
+
+
+
Optional arguments:
+
+
+
out: The label’s direction. Defaults to True (only returning response nodes directed towards the requested node). If set to False, will only return response nodes directed away from the request node.
+
+
+
Assembling the information you will need for a call to the get_property_values method
+
+
Going into more detail on how to assemble the values for the required argument:
+
+
+
dcids: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the nodes of interest. More information about DCIDs is available in the glossary.
+
+
+
In addition to this required property, this endpoint also allows for an additional, optional argument:
+
+
+
out: This is a boolean value that refers to the orientation, or direction, of the edge. You can specify this argument as True to indicate that you desire the response to only include nodes with the value of the property equivalent to one or more of the specified DCIDs, or False to only return nodes equivalent to one or more of the values of the properties of the specified DCIDs. (To visualize this, Figure 1 illustrates the directions for the property containedInPlace of the node for Argentina.)
+
+
+
+
+
Figure 1. Relationship diagram for the property containedInPlace of the country Argentina. Note the directionality of the property containedInPlace: the API returns both nodes with direction in (Buenos Aires is containedInPlace of Argentina) and nodes with direction out (Argentina is containedInPlace of South America).
+
+
What to expect in the function return
+
+
The method’s return value will always be a dict in the following form:
+
+
{
+ "<dcid>":["string",...]
+ ...
+}
+
+
+
Example requests and responses
+
+
Example 1: Retrieve the outwardly directed property labels of Wisconsin’s eighth congressional district.
dcids: A list of nodes to query, identified by their Data Commons identifiers.
+
prop: The property to query for.
+
+
+
Optional arguments:
+
+
+
value_type: The type of the property value to filter by. Defaults to NONE. Only applicable if
+the value refers to a node.
+
out: The label’s direction. Defaults to True (only returning response nodes directed towards the requested node). If set to False, will only return response nodes directed away from the request node.
+
limit: (≤ 500) Maximum number of values returned per node. Defaults to datacommons.utils._MAX_LIMIT.
+
+
+
Assembling the information you will need for a call to the get_property_values method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
dcids: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the nodes of interest. More information about DCIDs is available in the glossary.
+
+
+
prop: The property whose value you are interested in, such as “name” for the name of a node, or “typeOf” for the type of a node.
+
+
+
+
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
value_type: If the property queried only takes on node values, you can use this argument to filter nodes in the response, ensuring the response only contains nodes with the specified type. For example, if you query the property containedInPlace on the DCID geoId/06085, your response will contain many results that may not be relevant to your question. If you instead specify the value_type as City, your result list will be shorter, narrower, and easier to parse.
+
+
+
out: This is a boolean value that refers to the orientation, or direction, of the edge. You can specify this argument as True to indicate that you desire the response to only include nodes with the value of the property equivalent to one or more of the specified DCIDs, or False to only return nodes equivalent to one or more of the values of the properties of the specified DCIDs. (To visualize this, Figure 1 illustrates the directions for the property containedInPlace of the node for Argentina.)
+
+
+
+
+
+
Figure 1. Relationship diagram for the property containedInPlace of the country Argentina. Note the directionality of the property containedInPlace: the API returns both nodes with direction in (Buenos Aires is containedInPlace of Argentina) and nodes with direction out (Argentina is containedInPlace of South America).
+
+
What to expect in the function return
+
+
The method’s return value will always be a dict in the following form:
+
+
{
+ "<dcid>":["string",...]
+ ...
+}
+
+
+
Examples
+
+
Example 1: Retrieve the common names of the country of Côte d’Ivoire.
Example 3: Retrieve the addresses of Stuyvesant High School in New York and Gunn High School in California.
+
+
>>>datacommons.get_property_values(["nces/360007702877","nces/062961004587"],'address')
+{'nces/360007702877':['345 Chambers St, New York, New York'],'nces/062961004587':['780 Arastradero Rd., Palo Alto, California']}
+
+
+
Example 4: Retrieve a list of earthquake events in Madagascar.
+
+
+
NOTE:
+ Unlike in the REST API, the Python endpoint returns only one direction. Hence, you must specify out as False to obtain results in Madagascar.
Example 6: Retrieve the country in which Buenos Aires is located.
+
+
+
+
Figure 2. Relationship diagram for the property containedInPlace of the country Argentina. Note the directionality of the property containedInPlace: the API returns both nodes with direction in (Buenos Aires is containedInPlace of Argentina) and nodes with direction out (Argentina is containedInPlace of South America).
Query the Data Commons knowledge graph using SPARQL
+
+
Returns the results of running a graph query on the Data Commons knowledge graph
+using SPARQL. Note that Data Commons is only
+able to support a limited subsection of SPARQL functionality at this time: specifically only the keywords ORDER BY, DISTINCT, and LIMIT.
+
+
Note: The Python SPARQL library currently only supports the V1 version of the API.
+
+
General information about the query() method
+
+
Signature:
+
+
datacommons.query(query_string,select=None)
+
+
+
Required arguments:
+
+
+
query_string: A SPARQL query string.
+
+
+
How to construct a call to the query() method
+
+
This method makes it possible to query the Data Commons knowledge graph using SPARQL. SPARQL is a query language developed to retrieve data from websites. It leverages the graph structure innate in the data it queries to return specific information to an end user. For more information on assembling SPARQL queries, check out the Wikipedia page about SPARQL and the W3C specification information.
+
+
This method accepts the additional optional argument select. This function selects rows to be returned by query. Under the hood, the select function examines a row in the results of executing query_string and returns True if and only if the row is to be returned by query. The row passed in as an argument is represented as a dict that maps a query variable in query_string to its value in the given row.
+
+
+
NOTE:
+
+
In the query, each variable should have a typeOf condition, e.g. "?var typeOf City .".
The response contains an array of dictionaries, each corresponding to one node matching the conditions of the query. Each dictionary’s keys match the variables in the query SELECT clause, and the values in the dictionaries are those associated to the given node’s query-specified properties.
+
+
Examples and error responses
+
+
The following examples and error responses, along with explanations and fixes for the errors, are available in this Python notebook.
+
+
Example 1: Retrieve the name of the state associated with DCID geoId/06.
+
+
>>>geoId06_name_query='SELECT ?name ?dcid WHERE { ?a typeOf Place . ?a name ?name . ?a dcid ("geoId/06" "geoId/21" "geoId/24") . ?a dcid ?dcid }'
+>>>datacommons.query(geoId06_name_query)
+[{'?name':'Kentucky','?dcid':'geoId/21'},{'?name':'California','?dcid':'geoId/06'},{'?name':'Maryland','?dcid':'geoId/24'}]
+
+
+
Example 2: Retrieve a list of ten biological specimens in reverse alphabetical order.
Example 3: Retrieve a list of GNI observations by country.
+
+
>>>gni_by_country_query='SELECT ?observation ?place WHERE { ?observation typeOf StatVarObservation . ?observation variableMeasured Amount_EconomicActivity_GrossNationalIncome_PurchasingPowerParity_PerCapita . ?observation observationAbout ?place . ?place typeOf Country . } ORDER BY ASC (?place) LIMIT 10'
+>>>datacommons.query(gni_by_country_query)
+[{'?observation':'dc/o/syrpc3m8q34z7','?place':'country/ABW'},{'?observation':'dc/o/bqtfmc351v0f2','?place':'country/ABW'},{'?observation':'dc/o/md36fx6ty4d64','?place':'country/ABW'},{'?observation':'dc/o/bm28zvchsyf4b','?place':'country/ABW'},{'?observation':'dc/o/3nleez1feevw6','?place':'country/ABW'},{'?observation':'dc/o/x2yg38d0xecnf','?place':'country/ABW'},{'?observation':'dc/o/7swdqf6yjdyw8','?place':'country/ABW'},{'?observation':'dc/o/yqmsmbx1qskfg','?place':'country/ABW'},{'?observation':'dc/o/6hlhrz3k8p5wf','?place':'country/ABW'},{'?observation':'dc/o/txfw505ydg629','?place':'country/ABW'}]
+
+
+
Example 4: Retrieve a sample list of observations with the unit InternationalDollar.
+
+
>>>internationalDollar_obs_query='SELECT ?observation WHERE { ?observation typeOf StatVarObservation . ?observation unit InternationalDollar } LIMIT 10'
+>>>datacommons.query(internationalDollar_obs_query)
+[{'?observation':'dc/o/s3gzszzvj34f1'},{'?observation':'dc/o/gd41m7qym86d4'},{'?observation':'dc/o/wq62twxx902p4'},{'?observation':'dc/o/d93kzvns8sq4c'},{'?observation':'dc/o/6s741lstdqrg4'},{'?observation':'dc/o/2kcq1xjkmrzmd'},{'?observation':'dc/o/ced6jejwv224f'},{'?observation':'dc/o/q31my0dmcryzd'},{'?observation':'dc/o/96frt9w0yjwxf'},{'?observation':'dc/o/rvjz5xn9mlg73'}]
+
+
+
Example 5: Retrieve a list of ten distinct annual estimates of life expectancy, along with the year of estimation, for forty-seven-year-old Hungarians.
+
+
>>>life_expectancy_query='SELECT DISTINCT ?LifeExpectancy ?year WHERE { ?o typeOf StatVarObservation . ?o variableMeasured LifeExpectancy_Person_47Years . ?o observationAbout country/HUN . ?o value ?LifeExpectancy . ?o observationDate ?year } ORDER BY ASC(?LifeExpectancy) LIMIT 10'
+>>>datacommons.query(life_expectancy_query)
+[{'?LifeExpectancy':'26.4','?year':'1993'},{'?LifeExpectancy':'26.5','?year':'1992'},{'?LifeExpectancy':'26.7','?year':'1990'},{'?LifeExpectancy':'26.7','?year':'1994'},{'?LifeExpectancy':'26.8','?year':'1991'},{'?LifeExpectancy':'26.9','?year':'1995'},{'?LifeExpectancy':'27.2','?year':'1996'},{'?LifeExpectancy':'27.4','?year':'1999'},{'?LifeExpectancy':'27.5','?year':'1997'},{'?LifeExpectancy':'27.5','?year':'1998'}]
+
+
+
Example 6: Use the select function to filter returns based on name.
+
+
>>>names_for_places_query='SELECT ?name ?dcid WHERE { ?a typeOf Place . ?a name ?name . ?a dcid ("geoId/06" "geoId/21" "geoId/24") . ?a dcid ?dcid }'
+>>>maryland_selector=lambdarow:row['?name']=='Maryland'
+>>>result=datacommons.query(names_for_places_query,select=maryland_selector)
+>>>forrinresult:
+...print(r)
+...
+{'?name':'Maryland','?dcid':'geoId/24'}
+
Retrieve a collection of statistical data for multiple places
+
+
Returns a nested dict of all time series for places and stat_vars.
+Note that in Data Commons, a StatisticalVariable is any type of statistical metric that can be measured at a place and
+time. See the full list of StatisticalVariables.
+
+
General information about this method
+
+
Signature:
+
+
datacommons.get_stat_all(places,stat_vars)
+
+
+
Required arguments
+
+
+
places: The DCID IDs of the Place objects to query for. (Here DCID stands for Data Commons ID, the unique identifier assigned to all entities in Data Commons.)
Assembling the information you will need for a call to the get_stat_all method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
+
stat_var: The statistical variable whose value you are interested in.
In Data Commons, dcid stands for Data Commons ID and indicates the unique identifier assigned to every node in the knowledge graph.
+
+
+
+
Assembling the information you will need for a call to the get_stat_series method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
+
+
+
stat_var: The statistical variable whose value you are interested in.
+
+
+
+
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
measurement_method: The technique used for measuring a statistical variable.
You can find a list of StatisticalVariables with human-readable names here.
+
+
Optional arguments:
+
+
+
date: The preferred date of observation in ISO 8601 format. If not specified, returns the latest observation.
+
measurement_method: The DCID of the preferred measurementMethod value.
+
observation_period: The preferred observationPeriod value.
+
unit: The DCID of the preferred unit value.
+
scaling_factor: The preferred scalingFactor value.
+
+
+
Assembling the information you will need for a call to the get_stat_value method
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
+
stat_var: The statistical variable whose value you are interested in.
+
+
+
In addition to these required properties, this method also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
date: Specified in ISO 8601 format. Examples include 2011 (the year 2011), 2019-06 (the month of June in the year 2019), and 2019-06-05T17:21:00-06:00 (5:17PM on June 5, 2019, in CST).
+
+
+
measurement_method: The technique used for measuring a statistical variable.
dcids - A list of nodes to query, identified by their DCID.
+
+
+
Optional arguments:
+
+
+
limit - The maximum number of triples per combination of
+property and type associated with nodes linked by that property to fetch,
+≤ 500.
+
+
+
Assembling the information you will need for a call to the get_triples method
+
+
This endpoint requires the argument dcids, which are unique node identifiers defined by Data Commons. Your query will need to specify the DCIDs for the nodes of interest.
+
+
In addition to this required property, this endpoint also allows you to specify a limit on how many triples (up to 500) you would like to see in the response.
+
+
What to expect in the function return
+
+
The method’s return value will always be a dict in the following form:
+
+
{
+ "<dcid>":[<Triple>,...]
+ ...
+}
+
+
+
While all triples contain subjects, predicates, and objects, those entities may be specified using any of a few possible fields. Here are possible keys that you may find associated to triples in the JSON response:
+
+
+
SubjectID
+
SubjectName
+
SubjectTypes
+
Predicate
+
ObjectID
+
ObjectName
+
ObjectValue
+
ObjectTypes
+
ProvenanceID
+
+
+
Example requests and responses
+
+
Example 1: Retrieve triples associated with zip code 94043.
Get familiar with the Data Commons knowledge graph and APIs using these analysis examples.
+You can also clone these to use as a base for your own analysis.
NOTE: The Data Commons V0 REST API is deprecated. Please use the V2 REST API.
+
+
+
Data Commons V0 REST API
+
+
The Data Commons REST API is a REST library that enables developers to
+programmatically access nodes in the Data Commons knowledge graph. This package
+allows users to explore the structure of the graph, integrate statistics from
+the graph into data analysis applications and much more. Please see the
+overview for more details on the design and structure of the API.
+
+
Please see the V2 REST API for the latest version of the REST API.
Given a list of parent Place DCIDs,
+(e.g. any State, Country, etc.), return a list of child places
+contained within the specified DCIDs. Only returns children whose place type matches
+the request’s placeType parameter.
+
+
General information about this endpoint
+
+
URL: /node/places-in
+
+
Methods available: GET, POST
+
+
Required arguments:
+
+
+
+
dcids: A list of (parent) Place nodes, identified by their DCIDs.
+
+
+
placeType: The type of the contained (child) Place nodes to filter by.
+
+
+
+
How to construct a request to the places within a place endpoint
+
+
Step 1: assembling the information you will need
+
+
This endpoint requires the argument dcids. DCIDs are unique node identifiers defined by Data Commons. Your query will need to specify the DCIDs for the parent places of interest.
+
+
This endpoint also requires the argument placeType, specifying the type of the child places you desire in the response.
+
+
Step 2: creating the request
+
+
When actually putting together your request, you can choose from two options. If you intend to query only a small number of DCIDs, you may want to use the simpler formatting offered by the GET method. For larger numbers of DCIDs, or if you prefer to utilize a static URL, a POST request likely makes more sense. To use it, make a POST request against the main endpoint while changing the fields of the JSON body it sends.
+
+
Examples of usage for both GET and POST can be found below.
+
+
What to expect in the response
+
+
Your response will always look like this:
+
+
{
+ "payload":"<payload string>",
+}
+
+
+
Here "<payload string>" is a long encoded JSON string, whose structure changes depending on whether the response contains node references. You can run JSON.parse() on the payload field to retrieve the data. For example, in JavaScript: var data = JSON.parse(response['payload']).
+
+
After decoding the response payload string, its structure adheres to the following form:
Retrieve all statistical variables available for a particular place
+
+
Given a list of Place DCIDs,
+(e.g. any State, Country, etc.), return a list of statistical variables available for the specified DCIDs.
+
+
General information about this endpoint
+
+
URL: /place/stat-vars
+
+
Methods available: GET, POST
+
+
Required arguments:
+
+
+
dcids: A list of Place nodes, identified by their DCIDs.
+
+
+
How to construct a request to the place statistical variables endpoint
+
+
Step 1: assembling the information you will need
+
+
This endpoint requires the argument dcids. DCIDs are unique node identifiers defined by Data Commons. Your query will need to specify the DCIDs for the parent places of interest.
+
+
Step 2: creating the request
+
+
When actually putting together your request, you can choose from two options. If you intend to query only a small number of DCIDs, you may want to use the simpler formatting offered by the GET method. For larger numbers of DCIDs, or if you prefer to utilize a static URL, a POST request likely makes more sense. To use it, make a POST request against the main endpoint while changing the fields of the JSON body it sends.
+
+
Examples of usage for both GET and POST can be found below.
This endpoint is suitable for situations in which you have a node or list of nodes and desire to obtain the labels of all properties defined for those nodes.
+
+
General information about this endpoint
+
+
URL: /node/property-labels
+
+
Methods available: GET, POST
+
+
Required arguments:
+
+
+
dcids: A list of nodes to query, identified by DCID.
+
+
+
How to construct a request to the property label endpoint
+
+
Step 1: Assembling the information you will need
+
+
This endpoint requires the argument dcids, which are unique node identifiers defined by Data Commons. Your query will need to specify the DCIDs for the nodes of interest.
+
+
Step 2: Creating the request
+
+
When actually putting together your request, you can choose from two options. If you intend to query only a small number of DCIDs, you may want to use the simpler formatting offered by the GET method. For larger numbers of DCIDs, or if you prefer to utilize a static URL, a POST request likely makes more sense. To use it, make a POST request against the main endpoint while changing the fields of the JSON body it sends.
+
+
What to expect in the response
+
+
Your response will always look like this:
+
+
{
+ "payload":"<payload string>",
+}
+
+
+
Here "<payload string>" is a long encoded JSON string, whose structure changes depending on whether the response contains node references. You can run JSON.parse() on the payload field to retrieve the data. For example, in JavaScript: var data = JSON.parse(response['payload']).
+
+
Here is the structure the response payload string adheres to after decoding:
For each node, inLabels contains labels directed towards the node while
+outLabels contains labels directed away from the node. For more information on the in and out directions, check out the property value REST endpoint documentation.
+
+
Example requests and responses
+
+
Example 1: Retrieve the property labels of Wisconsin’s eighth congressional district.
This endpoint is suitable for situations in which you have a node or list of nodes and desire to obtain the values of a specified property attached to those nodes.
+
+
General information about this endpoint
+
+
URL: /node/property-values
+
+
Methods available: GET, POST
+
+
Required arguments:
+
+
+
dcids: A list of nodes to query, identified by their DCID.
+
property: The property to query for.
+
+
+
Optional arguments:
+
+
+
valueType: The type of the property value to filter by. Only applicable if
+the value refers to a node.
+
direction: The label’s direction. Only valid values are out (returning response nodes directed towards the requested node) and in (returning response nodes directed away from the request node).
+
limit: (≤ 500) Maximum number of values returned per node.
+
+
+
How to construct a request to the property value endpoint
+
+
Step 1: Assembling the information you will need
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
+
dcids: Data Commons uniquely identifies nodes by assigning them DCIDs, or Data Commons IDs. Your query will need to specify the DCIDs for the nodes of interest.
+
+
+
property: The property whose value you are interested in, such as “name” for the name of a node, or “typeOf” for the type of a node.
+
+
+
+
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
valueType: If the property queried only takes on node values, you can use this argument to filter nodes in the response, ensuring the response only contains nodes with the specified type.
+
+
+
direction: This refers to the orientation, or direction, of the edge. You can specify this argument as out to indicate that you desire the response to only include nodes with the value of the property equivalent to one or more of the specified DCIDs, or in to only return nodes equivalent to one or more of the values of the properties of the specified DCIDs. (To visualize this, Figure 1 illustrates the directions for the property containedInPlace of the node for Argentina.)
+
+
+
+
+
+
Figure 1. Relationship diagram for the property containedInPlace of the country Argentina. Note the directionality of the property containedInPlace: the API returns both nodes with direction in (Buenos Aires is containedInPlace of Argentina) and nodes with direction out (Argentina is containedInPlace of South America).
+
+
Step 2: Creating the request
+
+
When actually putting together your request, you can choose from two options. If you intend to use only a small number of parameters, you may want to use the simpler formatting offered by the GET method, which makes requests against the main endpoint while altering the query parameters incorporated into the URL. For more complex queries, or if you prefer to utilize a static URL, a POST request likely makes more sense. To use it, make a POST request against the main endpoint while changing the fields of the JSON body it sends.
+
+
What to expect in the response
+
+
Your response will always look like this:
+
+
{
+ "payload":"<payload string>",
+}
+
+
+
Here "<payload string>" is a long encoded JSON string, whose structure changes depending on whether the response contains node references. You can run JSON.parse() on the payload field to retrieve the data. For example, in javascript: var data = JSON.parse(response['payload']).
+
+
After decoding the response payload string, there are two possible structures it could adhere to.
+
+
Structure 1: Decoded response payload string for property values that are not node references.
{
+ "payload":"{\"country/MDG\":{\"in\":[{\"dcid\":\"earthquake/usp000jgbb\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp000h6zw\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp000gmuf\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp000fu24\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp000dckw\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0008vc6\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0007k9j\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0005gu9\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0004qn4\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0002kfd\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp00020ud\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0001ss5\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0001fcd\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp0000afz\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp00006yt\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usp00005zf\",\"name\":\"Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/usc000evr6\",\"name\":\"8km NW of Anakao, Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/us60003r15\",\"name\":\"50km ESE of Ambanja, Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]},{\"dcid\":\"earthquake/us200040me\",\"name\":\"25km W of Antalaha, Madagascar\",\"provenanceId\":\"dc/xz8ndk3\",\"types\":[\"EarthquakeEvent\"]}]}}"
+}
+
Example 6: Retrieve the country in which Buenos Aires is located.
+
+
+
+
Figure 2. Relationship diagram for the property containedInPlace of the country Argentina. Note the directionality of the property containedInPlace: the API returns both nodes with direction in (Buenos Aires is containedInPlace of Argentina) and nodes with direction out (Argentina is containedInPlace of South America).
Query the Data Commons knowledge graph using SPARQL
+
+
Returns the results of running a graph query on the Data Commons knowledge graph
+using SPARQL. Note that Data Commons is only
+able to support a limited subsection of SPARQL functionality at this time: specifically only the keywords ORDER BY, DISTINCT, and LIMIT.
+
+
General information about this endpoint
+
+
URL: /query
+
+
Methods available: POST
+
+
Required arguments:
+
+
+
sparql: A SPARQL query string.
+
+
+
How to construct a request to the SPARQL query endpoint
+
+
Step 1: Assembling the information you will need
+
+
This endpoint makes it possible to query the Data Commons knowledge graph using SPARQL. SPARQL is a query language developed to retrieve data from RDF graph content on the web. It leverages the graph structure innate in the data it queries to return specific information to an end user.
+
+
Step 2: Creating the request
+
+
Since only the POST method is available for this endpoint, you will need to assemble the request in the form of a JSON object adhering to the following form:
If there are no values for your query, you won’t receive an error code. Instead, the endpoint will return only the headers you sent, with no accompanying value information.
+
+
If your JSON body is formatted improperly, you will receive a 400 error and an error message like the following:
+
+
{
+ "code":3,
+ "message":"Node should be string, got [StatisticalPopulation ?o typeOf StatVarObservation] of type []string",
+ "details":[
+ {
+ "@type":"type.googleapis.com/google.rpc.DebugInfo",
+ "stackEntries":[],
+ "detail":"internal"
+ }
+ ]
+}
+
+
+
If your SPARQL query is constructed incorrectly, you will receive a 500 error and an error message like the following:
+
+
{
+ "code":2,
+ "message":"googleapi: Error 400: Unrecognized name: count; Did you mean unit? at [1:389], invalidQuery",
+ "details":[
+ {
+ "@type":"type.googleapis.com/google.rpc.DebugInfo",
+ "stackEntries":[],
+ "detail":"internal"
+ }
+ ]
+}
+
Get a collection of statistical data for one or more places
+
+
Returns a multiple level object containing all available time series for the specified
+places and statistical variables.
+Note that in Data Commons, a Statistical Variable is any type of statistical metric that can be measured at a place and
+time. See the full list of StatisticalVariables.
+
+
General information about this endpoint
+
+
URL: /stat/all
+
+
Method: POST
+
+
Required arguments:
+
+
+
+
places: A list of PlaceDCIDs to query for. (Here DCID stands for Data Commons ID, the unique identifier assigned to all entities in Data Commons.)
The top level field placeData is an object keyed by a Place dcid, with the value
+being statVarData. The statVarData data is an object keyed by a Statistical
+Variable dcid, with the object having the following fields:
+
+
+
placeName: the name of the place.
+
sourceSeries: a list of time series data objects with the following fields
+
+
val: an object from date to statistical value.
+
importName: the import name of the observations.
+
provenanceDomain: the provenance domain of the observations.
+
measurementMethod: the measurement method of the observations, if it exists.
+
observationPeriod: the observation period of the observations, if it exists.
+
unit: the unit of the observations, if it exists.
+
scalingFactor: the scaling factor of the observations, if it exists.
+
+
+
+
+
Error Response
+
+
Failure to specify the place in the request will result in an error response.
How to construct a request to the place statistics time series endpoint
+
+
Step 1: Assembling the information you will need
+
+
+
NOTE:
+
+
Specifying arguments that do not exist for the target place and variable will result in an empty response.
+
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
+
stat_var: The statistical variable whose value you are interested in.
+
+
+
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
measurement_method: The technique used for measuring a statistical variable.
How to construct a request to the place statistics value endpoint
+
+
Step 1: Assembling the information you will need
+
+
Going into more detail on how to assemble the values for the required arguments:
+
+
+
place: For this parameter, you will need to specify the DCID (the unique ID assigned by Data Commons to each node in the graph) of the place you are interested in.
In addition to these required properties, this endpoint also allows for other, optional arguments. Here are helpful arguments in regular use by Data Commons developers:
+
+
+
+
date: Specified in ISO 8601 format. Examples include 2011 (the year 2011), 2019-06 (the month of June in the year 2019), and 2019-06-05T17:21:00-06:00 (5:17PM on June 5, 2019, in CST).
+
+
+
measurement_method: The technique used for measuring a statistical variable.
Given a list of nodes, return triples which are associated with the specified
+node(s).
+
+
A knowledge graph can be described as a collection of triples which are
+3-tuples that take the form (s, p, o). Here, s and o are nodes in the
+graph called the subject and object respectively, while p is the property
+label of a directed edge from s to o (sometimes also called the predicate).
+
+
General information about this endpoint
+
+
URL: /node/triples
+
+
Methods available: GET, POST
+
+
Required arguments:
+
+
+
dcids: A list of nodes to query, identified by their DCID.
+
+
+
Optional arguments:
+
+
+
limit: The maximum number of triples per combination of property and type
+associated with nodes linked by that property to fetch, up to 500.
+
+
+
How to construct a request to the triples endpoint
+
+
Step 1: assembling the information you will need
+
+
This endpoint requires the argument dcids, which are unique node identifiers defined by Data Commons. Your query will need to specify the DCIDs for the nodes of interest.
+
+
In addition to this required property, this endpoint also allows you to specify a limit on how many triples (up to 500) you would like to see in the response.
+
+
Step 2: creating the request
+
+
When actually putting together your request, you can choose from two options. If you intend to query only a small number of DCIDs, you may want to use the simpler formatting offered by the GET method. For larger numbers of DCIDs, or if you prefer to utilize a static URL, a POST request likely makes more sense. To use it, make a POST request against the main endpoint while changing the fields of the JSON body it sends.
+
+
What to expect in the response
+
+
Your response will always look like this:
+
+
{
+ "payload":"<payload string>",
+}
+
+
+
Here “" is a long encoded JSON string, whose structure changes depending on whether the response contains node references. You can run JSON.parse() on the payload field to retrieve the data. For example, in JavaScript: `var data = JSON.parse(response['payload'])`.
+
+
When decoded, the response adheres to this structure:
+
+
{
+ "<dcid>":{
+ <Triples>
+ },
+ ...
+}
+
+
+
While all triples contain subjects, predicates, and objects, those entities may be specified using any of a few possible fields. Here are possible keys that you may find associated to triples in the JSON response:
+
+
+
SubjectID
+
SubjectName
+
SubjectTypes
+
Predicate
+
ObjectID
+
ObjectName
+
ObjectValue
+
ObjectTypes
+
ProvenanceID
+
+
+
Example requests and responses
+
+
Example 1: Retrieve triples associated with squareMeter 1238495 (a land tract in southern Florida).
NOTE: The Data Commons V1 REST API is deprecated. Please use the V2 REST API.
+
+
+
Data Commons V1 REST API
+
+
The Data Commons REST API is a
+REST library
+that enables developers to programmatically access data in the Data Commons
+knowledge graph. This package allows users to explore the structure of the
+graph, integrate statistics from the graph into data analysis applications and
+much more.
+
+
Getting Started
+
+
First time using the Data Commons API, or just need a refresher? Take a look at
+our Getting Started Guide.
+
+
Service Endpoints
+
+
The base URL for all endpoints below is:
+
+
https://api.datacommons.org
+
+
+
Simple vs Bulk Query
+
+
Some APIs have a bulk version, designed for handling multiple queries at a time,
+with more detailed output. Bulk endpoints are tagged with bulk below.
+
+
Local Graph Exploration
+
+
Methods for exploring the graph around a set of nodes.
Given the description of an entity, this endpoint searches for an entry in the Data Commons knowledge graph and returns the DCIDs of matches. For example, you could query for “San Francisco, CA” or “San Francisco” to find that its DCID is geoId/0667000. You can also provide the type of entity (country, city, state, etc.) to disambiguate (Georgia the country vs. Georgia the US state). If multiple DCIDs are returned, the first is the most likely best match given the available info.
+
+
+ info Note:
+ Currently, this endpoint only supports place entities. Support for other entity types will be added as the knowledge graph grows.
+
+
+
+ priority_highIMPORTANT:
+ This endpoint relies on name-based geocoding and is prone to inaccuracies. One common pattern is ambiguous place names that exist in different countries, states, etc. For example, there is at least one popular city called “Cambridge” in both the UK and USA. Thus, for more precise results, please provide as much context in the description as possible. For example, to resolve Cambridge in USA, pass “Cambridge, MA, USA” if you can.
+
+
+
+ info See Also:
+ For querying a single entity and a simpler output, see the simple version of this endpoint.
+
DCIDs matching the description you provided. If no matches are found, this field will not be returned.
+
+
+
+
+
Examples
+
+
Example 1: Find the DCID of places, with and without the type field
+
+
This queries for the DCID of “Georgia” twice: once without specifying type, and once with. Notice that specifying “Georgia” without specifying type returned the DCID of the US state of Georgia. When including "type":"Country", the DCID of the country of Georgia is returned.
This API returns basic information on multiple places, given each of their DCIDs. The information provided is per place, and includes the place’s name, type (city, state, country, etc.), as well as information on all parent places that contain the place queried.
+
+
+ info Tip:
+ For a rich, graphical exploration of places available in the Data Commons knowledge graph, take a look at the Place Explorer.
+
+
+
+ info See Also:
+ To get information on a variable instead of a place, see /v1/bulk/info/variable.
+ For querying a single variable and a simpler output, see the simple version of this endpoint.
+
Information about the place queried. Includes the name and type (city, state, country, etc.) of the place, as well as those of all “parent” places that contain the place queried (e.g. North America is a parent place of the United States).
+
+
+
+
+
Examples
+
+
Example 1: Get information for multiple places
+
+
Get information on the US states of California (DCID: geoId/06) and Alaska (DCID: geoId/02).
This API returns basic information on muliple variable groups, given the variable groups’
+DCIDs. The information is provided per variable group, and includes the
+display name, a list of child variables with their information, a list of child variable groups
+with their information and the number of descendent variables. If variable groups DCIDs are not provided, then
+all the variable group information will be retrieved.
+
+
+ info Tip:
+ Variable group is used in the statistical variable hierarchy UI widget as shown in Statistical Variable Explorer.
+
+
+
+ info See Also:
+ For querying a single variable group and a simpler output, see the simple version of this endpoint.
+
Your API key. See the page on authentication for a demo key, as well as instructions on how to get your own key.
+
+
+
nodes Optional
+
string
+
DCIDs of the variable groups to query information for.
+
+
+
constrained_entities Optional
+
Repeated string
+
DCIDs of entities to filter by. If provided, the results will be filtered to only include the queried variable group’s descendent variables that have data for the queried entities.
Information about the variable group queried. Includes child variables and variable group information, number of descendent variables and all the parent variable groups.
+
+
+
+
+
Examples
+
+
Example 1: Get information for all variable groups in Data Commons
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/bulk/info/variable-group?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
This API returns basic information on multiple variables, given each of their
+DCIDs. The information is provided per
+variable, and includes the number of entities with data on each variable, the
+minimum and maximum values observed, and the name and DCID of the top 3 entities
+with highest observed values for each variable.
+
+
+ info Tip:
+ To explore variables available in the Data Commons knowledge graph, take a look at the Statistical Variable Explorer.
+
+
+
+ info See Also:
+ To get information on a place instead of a variable, see /v1/bulk/info/place.
+ For querying a single variable and a simpler output, see the simple version of this endpoint.
+
Information about the variable queried. Includes maximum and minimum values, and number of places with data on the variable queried, grouped by place type (country-level, state-level, city-level, etc. statistics are grouped together). Also includes information about the provenance of data for the variable queried.
+
+
+
+
+
Examples
+
+
Example 1: Get information for multiple variables
+
+
Get information on the variables for number of farms (DCID: Count_Farm) and
+number of teachers (DCID: Count_Teacher).
Retrieve a specific observation at a set date from multiple variables for multiple entities.
+
+
+ info See Also:
+ To retrieve the entire series of observations, use /v1/bulk/observations/series
+ For single queries with a simpler output, see the simple version of this endpoint
+
Datetime of measurement of the value requested in ISO 8601 format. To see the dates available, look up the variable in the Statistical Variable Explorer. If date is not provided, the latest available datapoint is returned.
+
+
+
all_facets Optional
+
Boolean
+
Whether to return data from all facets available. If true, data from all facets available will be returned. If false, only data from the preferred facet will be returned. Defaults to false.
List of observations organized by variable. These are further organized by entity, and then by facet.
+
+
+
facets
+
object
+
Metadata on the facet(s) the data came from. Can include things like provenance, measurement method, and units.
+
+
+
+
+
Examples
+
+
Example 1: Get values for multiple variables and entities from the preferred facet at a set date
+
+
Get latest count of men (DCID: Count_Person_Male ) and count of women (DCID: Count_Person_Female ) for both California (DCID: geoId/06 ) and Texas (DCID: geoId/48 ) in 2019.
Example 2: Get values for multiple variables and entities from all facets
+
+
Get latest count of men (DCID: Count_Person_Male ) and count of women (DCID: Count_Person_Female ) for both California (DCID: geoId/06 ) and Texas (DCID: geoId/48 ) for all facets.
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/bulk/observations/point?entities=geoId/06&entities=geoId/48&variables=Count_Person_Male&variables=Count_Person_Female&all_facets=true&key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
Retrieve a single observation of multiple variables
+at a set date for entities linked to an ancestor entity by the same property.
+
+
More specifically, in the following diagram:
+
+
+
+
The property containedInPlace is linked. Buenos Aires is contained in
+Argentina, which is itself contained in South America – implying Buenos Aires
+is also contained in South America. With this endpoint, you could query for
+countries in South America (returning observations for Argentina) or for cities
+in South America (returning observations for Buenos Aires).
+
+
This is useful for retrieving an observation for all places within an ancestor place.
+For example, this could be getting the population of women in 2018 for all states in the United States.
+
+
+ info Note:
+ Currently, this endpoint only supports the containedInPlace property and Place entities. Support for other properties and entity types will be added in the future.
+
DCID of the property to query. Must be containedInPlace.
+
+
+
date Optional
+
string
+
Datetime of measurement of the value requested in ISO 8601 format. To see the dates available, look up the variable in the Statistical Variable Explorer. If date is not provided, the latest available datapoint is returned.
+
+
+
all_facets Optional
+
boolean
+
Whether to return data from all facets available. If true, data from all facets available will be returned. If false, only data from the preferred facet will be returned. Defaults to false.
Retrieve a series of observations for multiple variables and entities.
+
+
+ info See Also:
+ To retrieve a single observation within a series, use /v1/bulk/observations/point.
+ For single queries with a simpler output, see the simple version of this endpoint.
+
Whether to return data from all facets available. If true, data from all facets available will be returned. If false, only data from the preferred facet will be returned. Defaults to false.
List of observations organized by variable. These are further organized by entity, and then by facet. Observations are returned in chronological order.
+
+
+
facets
+
object
+
Metadata on the facet(s) the data came from. Can include things like provenance, measurement method, and units.
+
+
+
+
+
Examples
+
+
Example 1: Get time series for multiple variables and entities
+
+
Get total annual electric power consumption (DCID: Annual_Consumption_Coal_ElectricPower ) and water withdrawal rates (DCID: WithdrawalRate_Water ) for both Virginia (DCID: geoId/51 ) and Texas (DCID: geoId/48 )
Returns observations of multiple variables
+for entities linked to an ancestor entity by the same property.
+
+
More specifically, in the following diagram:
+
+
+
+
The property containedInPlace is linked. Buenos Aires is contained in
+Argentina, which is itself contained in South America – implying Buenos Aires
+is also contained in South America. With this endpoint, you could query for
+countries in South America (returning observations for Argentina) or for cities
+in South America (returning observations for Buenos Aires).
+
+
This is useful for retrieving observations for all places within an ancestor place.
+For example, this could be getting the population of women for all states in the United States.
+
+
+ info Note:
+ Currently, this endpoint only supports the containedInPlace property and Place entities. Support for other properties and entity types will be added in the future.
+
DCID of the property to query. Must be containedInPlace.
+
+
+
all_facets Optional
+
boolean
+
Whether to return data from all facets available. If true, data from all facets available will be returned. If false, only data from the preferred facet will be returned. Defaults to false.
List of observations organized by variable. These are further organized by entity, and then by facet. Observations are returned in chronological order.
+
+
+
facets
+
object
+
Metadata on the facet(s) the data came from. Can include things like provenance, measurement method, and units.
+
+
+
+
+
Examples
+
+
Example 1: Get observations for all places within an ancestor place.
+
+
Get the population (DCID: Count_Person) for all counties in the US state of Delaware (DCID: geoId/10).
Get all properties associated with a specific node,
+for multiple nodes.
+
+
More specifically, this endpoint returns the labels of the edges connected to a
+specific node in the Data Commons Knowledge Graph. Edges in the graph are
+directed, so properties can either be labels for edges towards or away from
+the node. Outgoing edges correspond to properties of the node. Incoming edges
+denote that the node is the value of this property for some other node.
+
+
+ info See Also:
+ To the values of properties, see /v1/bulk/property/values.
+ To find connected edges and nodes, see /v1/bulk/triples.
+ For querying a single node with simpler output, see the simple version of this endpoint.
+
One of in or out. Denotes direction of edges to get triples for.
If in, returns properties represented by edges pointing toward the node provided. If out, returns properties represented by edges pointing away from the node provided.
+
+
+
+
+
Query Parameters
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
key Required
+
string
+
Your API key. See the page on authentication for a demo key, as well as instructions on how to get your own key.
Data Commons represents properties as labels of directed edges between nodes,
+where the successor node is a value of the property. Thus, this endpoint returns
+nodes connected to the queried node via the property queried.
+
+
Note: If you want to query values for the property containedInPlace, consider
+using
+/v1/bulk/property/values/linked
+instead.
+
+
+ info See Also:
+ To get a list of properties available for an node, see /v1/bulk/properties.
+ For single queries with a simpler output, see the simple version of this endpoint.
+
Return property values for properties that can be
+chained for multiple degrees in the knowledge graph.
+
+
+ info Note:
+ This API currently only supports the containedInPlace property to fetch Place nodes. Support for more properties and node types will be added in the future.
+
+
+
For example, in the following diagram:
+
+
+
+
The property containedInPlace is chained. Buenos Aires is contained in
+Argentina, which is itself contained in South America – implying Buenos Aires
+is also contained in South America. With this endpoint, you could query for
+countries in South America (returning Argentina) or for cities in South America
+(returning Buenos Aires).
+
+
+ info See Also:
+ For single requests with a simpler output, see the simple version of this endpoint.
+
Get the states of the countries USA (DCID: ‘country/USA’) and India (DCID:
+‘country/IND’). Note that this works because both countries have entries for the
+State class of places.
Given the description of an entity, this endpoint searches for an entry in the Data Commons knowledge graph and returns the DCIDs of matches. For example, you could query for “San Francisco, CA” or “San Francisco” to find that its DCID is geoId/0667000. You can also provide the type of entity (country, city, state, etc.) to disambiguate (Georgia the country vs. Georgia the US state).
+
+
+ info Note:
+ Currently, this endpoint only supports place entities. Support for other entity types will be added as the knowledge graph grows.
+
+
+
+ priority_highIMPORTANT:
+ This endpoint relies on name-based geocoding and is prone to inaccuracies. One common pattern is ambiguous place names that exist in different countries, states, etc. For example, there is at least one popular city called “Cambridge” in both the UK and USA. Thus, for more precise results, please provide as much context in the description as possible. For example, to resolve Cambridge in USA, pass “Cambridge, MA, USA” if you can.
+
+
+
+ info See Also:
+ For querying multiple entities, see the bulk version of this endpoint.
+
Welcome! Whether you’re new to Data Commons or are just looking for a refresher, this guide gives an overview of what you need to know to get started using our REST API.
Our REST API follows the RESTful architectural style to allow you to query the Data Commons Knowledge Graph via HTTP. This allows you to explore the local graph and query data from specific variables and entities programatically.
+
+
How to Use the REST API
+
+
Our REST API can be used with any tool or language that supports HTTP. You can make queries on the command line (e.g. using cURL), by scripting HTTP requests in another language like javascript, or even by entering an endpoint into your web browser!
+
+
Following HTTP, a REST API call consists of a request that you provide, and a response from our servers with the data you requested in JSON format. The next section details how to assemble a request.
+
+
Assembling a Request
+
+
Endpoints
+
+
Requests are made through API endpoints. We provide endpoints for many different queries (see the list of available endpoints here).
+
+
Each endpoint can be acessed using its unique URL, which is a combination of a base URL and the endpoint’s URI.
+
+
The base URL for all REST endpoints is:
+
+
https://api.datacommons.org
+
+
+
And a URI looks like /v1/observation/point. To access a particular endpoint, append the URI to the base URL (e.g. https://api.datacommons.org/v1/observation/point ).
+
+
Parameters
+
+
Endpoints take a set of parameters which allow you to specify which entities, variables, timescales, etc. you are interested in. There are two kinds of parameters: path parameters and query parameters.
+
+
Path Parameters
+
+
Path parameters must be passed in a specific order as part of the URL. For example, /v1/observations/point requires the DCIDs of the entity and variable to query, in that order. This would look something like:
Query parameters are chained at the end of a URL behind a ? symbol. Separate multiple parameter entries with an & symbol. For example, this would look like:
Still confused? Each endpoint’s documentation page has examples at the bottom tailored to the endpoint you’re trying to use.
+
+
Finding Available Entities, Variables, and their DCIDs
+
+
Most requests require the DCID of the entity or variable you wish to query. Curious what entities and variables are available? Want to find a DCID? Take a look at our explorer tools:
Many endpoints allow the user to filter their results to specific dates. When querying for data at a specific date, the string passed for the date queried must match the date format (in ISO-8601) used by the target variable. An easy way to see what date format a variable uses is to look up your variable of interest in the Statistical Variable Explorer.
+
+
Bulk Retrieval
+
+
Many of our APIs come in both “simple” and “bulk” versions. The simple versions of endpoints have prefix /v1/ and are designed for handling single requests with a simplified return structure. The bulk versions of endpoints have prefix /v1/bulk/ and are meant for querying multiple variables or entities at once, and provide richer details in the response.
+
+
POST requests
+
+
Some bulk endpoints allow for POST requests. For POST requests, feed all parameters in JSON format. For example, in cURL, this would look like:
+ priority_highIMPORTANT:
+ API keys are now required. To use the REST API, a valid API key must be included in all requests.
+
+
+
Using API Keys
+
+
API keys are required in any REST API request. To include an API key, add your API key to the URL as a query parameter by appending ?key=<YOUR_API_KEY_HERE>.
The trial key is capped with a limited quota for requests. If you are planning on using our APIs more rigorously (e.g. for personal or school projects, developing applications, etc.) please go to the portal at https://apikeys.datacommons.org and request a key for api.datacommons.org.
+
+
Pagination
+
+
When the response to a request is too long, the returned payload is
+paginated. Only a subset of the response is returned, along with a long string
+of characters called a token. To get the next set of entries, repeat the
+request with nextToken as an query parameter, with the token as its value.
+
+
For example, the request:
+
+
$ curl --request GET \
+ `https://api.datacommons.org/v1/triples/in/geoId/06`
+
This is most commonly seen when the endpoint is misspelled or otherwise malformed. Check the spelling of your endpoint and that all required path parameters are provided in the right order.
This is most commonly seen when your request is missing a required path parameter. Make sure endpoints and parameters are both spelled correctly and provided in the right order.
+
+
Empty Response
+
+
{}
+
+
+
Sometimes your query might return an empty result. This is most commonly seen when the value provided for a parameter is misspelled or doesn’t exist. Make sure the values you are passing for parameters are spelled correctly.
+
+
“Could not find field <field> in the type”
+
+
{
+ "code":3,
+ "message":"Could not find field \"variables\" in the type \"datacommons.v1.BulkVariableInfoRequest\".",
+ "details":[
+ {
+ "@type":"type.googleapis.com/google.rpc.DebugInfo",
+ "stackEntries":[],
+ "detail":"internal"
+ }
+ ]
+}
+
+
+
This is most commonly seen when a query parameter is misspelled or incorrect. Check the spelling of query parameters.
This API returns basic information on a place, given the place’s DCID. The information provided includes the place’s name, type (city, state, country, etc.), as well as information on all parent places that contain the place queried.
+
+
+ info Tip:
+ For a rich, graphical exploration of places available in the Data Commons knowledge graph, take a look at the Place Explorer.
+
+
+
+ info See Also:
+ To get information on a variable instead of a place, see /v1/info/variable.
+ For querying multiple places, see the bulk version of this endpoint.
+
Information about the place queried. Includes the name and type (city, state, country, etc.) of the place, as well as those of all “parent” places that contain the place queried (e.g. North America is a parent place of the United States).
+
+
+
+
+
Examples
+
+
Example 1: Get information on a single place
+
+
Get basic information about New York City (DCID: geoId/3651000).
+
+
Request:
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/info/place/geoId/3651000?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
This API returns basic information of a variable group, given the variable group’s
+DCID. The information provided includes the
+display name, a list of child variables with their information, a list of child variable groups
+with their information and the number of descendent variables.
+
+
+ info Tip:
+ Variable group is used in the statistical variable hierarchy UI widget as shown in Statistical Variable Explorer.
+
+
+
+ info See Also:
+ For querying multiple variables groups, see the bulk version of this endpoint.
+
DCID of the variable group to query information for.
+
+
+
+
+
Query Parameters
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
key Required
+
string
+
Your API key. See the page on authentication for a demo key, as well as instructions on how to get your own key.
+
+
+
constrained_entities Optional
+
Repeated string
+
DCIDs of entities to filter by. If provided, the results will be filtered to only include the queried variable group’s descendent variables that have data for the queried entities.
Information about the variable group queried. Includes child variables and variable group information, number of descendent variables and all the parent variable groups.
+
+
+
+
+
Examples
+
+
Example 1: Get information on a single variable group
+
+
Get basic information about the variable group of female population (DCID:
+dc/g/Person_Gender-Female).
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/info/variable-group/dc/g/Person_Gender-Female?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
This API returns basic information on a variable, given the variable’s
+DCID. The information provided includes the
+number of entities that have data for the variable, the minimum and maximum
+value observed, and the name and DCID of the top 3 entities with highest
+observed values for that variable. The information is grouped by place type
+(country, state, county, etc.).
+
+
+ info Tip:
+ To explore variables available in the Data Commons knowledge graph, take a look at the Statistical Variable Explorer.
+
+
+
+ info See Also:
+ To get information on a place instead of a variable, see /v1/info/place.
+ For querying multiple variables, see the bulk version of this endpoint.
+
Information about the variable queried. Includes maximum and minimum values, and number of places with data on the variable queried, grouped by place type (country-level, state-level, city-level, etc. statistics are grouped together). Also includes information about the provenance of data for the variable queried.
+
+
+
+
+
Examples
+
+
Example 1: Get information on a single variable
+
+
Get basic information about the variable for number of farms (DCID:
+Count_Farm).
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/info/variable/Count_Farm?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
Retrieve a specific observation at a set date from a variable for an entity from the
+preferred facet. If no date is provided, the latest
+observation is returned.
+
+
+ info See Also:
+ To retrieve the entire series of observations, use /v1/observations/series
+ For querying multiple variables or entities, see the bulk version of this endpoint.
+
Your API key. See the page on authentication for a demo key, as well as instructions on how to get your own key.
+
+
+
date Optional
+
type
+
Datetime of measurement of the value requested in ISO 8601 format. To see the dates available, look up the variable in the Statistical Variable Explorer. If date is not provided, the latest available datapoint is returned.
Value of the variable queried for the queried entity.
+
+
+
date
+
string
+
Datetime the value returned was measured.
+
+
+
facet
+
dict
+
Metadata on the facet the data came from. Can include things like provenance, measurement method, and units.
+
+
+
+
+
Examples
+
+
Example 1: Get latest observation for given variable and entity
+
+
Get the population count (DCID: Count_Person ) for the United States of America (DCID: country/USA ). Note that the latest entry available will be returned.
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/observations/point/country/USA/Count_Person?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
Retrieve series of observations from a specific variable for an entity from the preferred facet.
+
+
+ info See Also:
+ To retrieve a single observation in a series of values, use /v1/observations/point For querying multiple variables or entities, or to get observations from other facets, see the bulk version of this endpoint.
+
A list of {date, value} pairs for the variable queried, where date is the date of measurement and value the measured value for the variable. Pairs are returned in chronological order.
+
+
+
facet
+
dict
+
Metadata on the facet the data came from. Can include things like provenance, measurement method, and units.
+
+
+
+
+
Examples
+
+
Example 1: Get the time series for a given variable and entity from a preferred facet.
+
+
Get the mean rainfall (DCID: Mean_Rainfall ) for New Delhi, India (DCID: wikidataId/Q 987).
+
+
Request:
+
+
$ curl --request GET --url\
+'https://api.datacommons.org/v1/observations/series/wikidataId/Q987/Mean_Rainfall?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI'
+
Get all properties associated with a specific node.
+
+
More specifically, this endpoint returns the labels of the edges connected to a
+specific node in the Data Commons Knowledge Graph. Edges in the graph are
+directed, so properties can either be labels for edges towards or away from
+the node. Outgoing edges correspond to properties of the node. Incoming edges
+denote that the node is the value of this property for some other node.
+
+
+ info See Also:
+ To find all possible values of a specific property, see /v1/property/values.
+ To find connected edges and nodes, see /v1/triples.
+ For querying multiple nodes, see the bulk version of this endpoint.
+
Data Commons represents properties as labels of directed edges between nodes,
+where the successor node is a value of the property. Thus, this endpoint returns
+nodes connected to the queried node via the property queried.
+
+
Note: If you want to query values for the property containedInPlace, consider
+using /v1/property/values/linked
+instead.
+
+
+ info See Also:
+ To get a list of properties available for an node, see /v1/properties.
+ To query multiple entites or properties, see the bulk version of this endpoint.
+
Return property values for properties that can be
+chained for multiple degrees in the knowledge graph.
+
+
+ info Note:
+ This API currently only supports the containedInPlace property to fetch Place nodes. Support for more properties and node types will be added in the future.
+
+
+
For example, in the following diagram:
+
+
+
+
The property containedInPlace is chained. Buenos Aires is contained in
+Argentina, which is itself contained in South America – implying Buenos Aires
+is also contained in South America. With this endpoint, you could query for
+countries in South America (returning Argentina) or for cities in South America
+(returning Buenos Aires).
+
+
+ info See Also:
+ To query multiple entites or properties, see the bulk version of this endpoint.
+
Query the Data Commons knowledge graph using
+SPARQL.
+
+
This endpoint makes it possible to query the Data Commons knowledge graph using
+SPARQL. SPARQL is a query language developed to retrieve data from RDF graph
+content on the web. It leverages the graph structure innate in the data it
+queries to return specific information to an end user.
The Data Commons REST API is a
+REST library
+that enables developers to programmatically access data in the Data Commons
+knowledge graph, using HTTP. This allows you to explore the structure of the
+graph, integrate statistics from the graph into data analysis applications and
+much more.
+
+
Following HTTP, a REST API call consists of a request that you provide, and a response from the Data Commons servers with the data you requested, in JSON format. You can use the REST API with any tool or language that supports HTTP. You can make queries on the command line (e.g. using cURL), by scripting HTTP requests in another language like Javascript, or even by entering an endpoint into your web browser!
+
+
What’s new in V2
+
+
The V2 API collapses functionality from the V1 API into a smaller number of endpoints, by introducing a syntax for relation expressions, described below. Each API endpoint can also handle both single and bulk requests.
+
+
Service endpoints
+
+
You make requests through API endpoints. You access each endpoint using its unique URL, which is a combination of a base URL and the endpoint’s URI.
+
+
The base URL for all REST endpoints is:
+
+
+https://api.datacommons.org/VERSION
+
+
+
The current version is v2.
+
+
To access a particular endpoint, append the URI to the base URL (e.g. https://api.datacommons.org/v2/node ).
+The URIs for the V2 API are below:
If you are running your own Data Commons, the URL/URI endpoints are slightly different:
+
+
+CUSTOM_URL/core/api/v2
+
+
+
Query parameters
+
+
Endpoints take a set of parameters which allow you to specify the entities, variables, timescales, etc. you are interested in. The V2 APIs only use query parameters.
+
+
Query parameters are chained at the end of a URL behind a ? symbol. Separate multiple parameter entries with an & symbol. For example, this would look like:
The trial key is capped with a limited quota for requests. If you are planning on using our APIs more rigorously (e.g. for personal or school projects, developing applications, etc.) please request an official key without any quota limits; please see Obtain an API key for information.
+
+
+
Note: If you are sending API requests to a custom Data Commons instance, do not include any API key in the requests.
+
+
+
To include an API key, add your API key to the URL as a query parameter by appending ?key=API_KEY.
Find available entities, variables, and their DCIDs
+
+
Many requests require the DCID of the entity or variable you wish to query. For tips on how to find relevant DCIDs, entities and variables, please see the Key concepts document, specifically the following sections:
Data Commons represents real world entities and data as nodes. These
+nodes are connected by directed edges, or arcs, to form a knowledge graph. The
+label of the arc is the name of the property.
+
+
Relation expressions include arrow annotation and other symbols in the syntax to
+represent neighboring nodes, and to support chaining and filtering.
+These new expressions allow all of the functionality of the V1 API to be
+expressed with fewer API endpoints in V2. All V2 API calls require relation
+expressions in the property or expression parameter.
+
+
The following table describes symbols in the V2 API relation expressions:
+
+
+
+
+
->
+
An outgoing arc
+
+
+
<-
+
An incoming arc
+
+
+
{PROPERTY:VALUE}
+
Filtering; identifies the property and associated value
+
+
+
[]
+
Multiple properties, separated by commas
+
+
+
*
+
All properties linked to this node
+
+
+
+
+
One or more expressions chained together for indirect relationships, like containedInPlace+{typeOf:City}
+
+
+
+
+
Incoming and outgoing arcs
+
+
Arcs in the Data Commons Graph have directions. In the example below, for the node Argentina, the property containedInPlace exists in both in and out directions, illustrated in the following figure:
+
+
+
+
Note the directionality of the property containedInPlace: incoming arc represents “Argentina contains Buenos Aires”, while the outgoing arc represents “Argentina is in South America”.
+
+
Nodes for outgoing arcs are represented by ->, while nodes for incoming arcs
+arcs are represented by <-. To illustrate using the above example:
+
+
+
Regions that include Argentina (DCID: country/ARG): country/ARG->containedInPlace
+
All cities directly contained in Argentina (DCID: country/ARG): country/ARG<-containedInPlace{typeOf:City}
+
+
+
Filters
+
+
You can use filters to reduce results to only match nodes with a specified property and value. Use {} to specify property:value pairs to define the filter. Using the same example, country/ARG<-containedInPlace+{typeOf:City} only returns nodes with the typeOf:City, filtering out typeOf:AdministrativeArea1 and so on.
+
+
Specify multiple properties
+
+
You can combine multiple properties together within []. For example, to request a few outgoing arcs for a node, use
+->[name, latitude, longitude]. See more in this Node API example).
+
+
Wildcard
+
+
To retrieve all properties linked to a node, use the * wildcard, e.g. <-*.
+See more in this Node API example.
+
+
Chain properties
+
+
Use + to express a chain expression. A chain expression represents requests for information about nodes
+which are connected by the same property, but are a few hops away. This is supported only for the containedInPlace property.
+
+
To illustrate again using the Argentina example:
+
+
All cities directly contained in Argentina (dcid: country/ARG): country/ARG<-containedInPlace{typeOf:City}
+
All cities indirectly contained in Argentina (dcid: country/ARG): country/ARG<-containedInPlace+{typeOf:City}
+
+
+
URL-encoding reserved characters in GET requests
+
+
HTTP GET requests do not allow some of the characters used by Data Commons DCIDs and relation expressions. When sending GET requests, you may need to use the corresponding percent codes for reserved characters. For example, a query string such as the following:
When the response to a request is too long, the returned payload is
+paginated. Only a subset of the response is returned, along with a long string
+of characters called a token. To get the next set of entries, repeat the
+request with nextToken as an query parameter, with the token as its value.
+
+
For example, the request:
+
+
curl --request GET \
+ 'https://api.datacommons.org/v2/node?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI&nodes=geoId%2F06&property=%3C-%2A'
+
Data Commons represents node relations as directed edges between nodes, or
+properties. The name of the property is a label, while the target node is the value of
+the property. The Node API returns the property labels and values that are
+connected to the queried node. This is useful for
+finding local connections between nodes of the Data Commons knowledge graph.
+
+
More specifically, this API can perform the following tasks:
+
+
Get all property labels associated with individual or multiple nodes.
+
Get the values of a property for individual or multiple nodes. These can also
+be chained for multiple hops in the graph.
+
Get all connected nodes that are linked with individual or multiple nodes.
Property to query, represented with symbols including arrow notation. For more details, see relation expressions. By using different property parameters, you can query node information in different ways, such as getting the edges and neighboring node values. Examples below show how to request this information for one or multiple nodes.
Example 1: Get all incoming arc labels for a given node
+
+
Get all incoming arc property labels of the node with DCID geoId/06 by querying all properties with the <- symbol. This returns just the property labels but not the property values.
+
+
Parameters:
+
+
nodes: "geoId/06"
+property: "<-"
+
+
+
GET Request:
+
+
curl --request GET --url\
+ 'https://api.datacommons.org/v2/node?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI&nodes=geoId%2F06&property=%3C-'
+
Example 3: Get multiple property values for multiple nodes
+
+
Get name, latitude, and longitude values for several nodes: geoId/06085
+and geoId/06087. Note that multiple properties for a given node must be
+enclosed in square brackets [].
Example 4: Get all incoming arc values (properties) for a node
+
+
Get all the incoming linked nodes for node PowerPlant, using <-*. Note that, unlike example 1, this query returns the actual property values, not just their labels.
+
+
Also note that the response contains a nextToken, so to get all the data, you need to send additional requests with continuation tokens, until no nextToken is returned.
+
+
Parameters:
+
+
nodes: "PowerPlant"
+property: "<-*"
+
+
+
GET Request:
+
+
curl --request GET --url\
+ 'https://api.datacommons.org/v2/node?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI&nodes=PowerPlant&property=%3C-%2A'
+
Example 5: Get a list of all existing statistical variables
+
+
Get all incoming linked nodes of node StatisticalVariable, with the typeof property. Since StatisticalVariable is a top-level entity, or entity type, this effectively gets all statistical variables.
+
+
Also note that the response contains a nextToken, so to get all the data, you need to send additional requests with continuation tokens, until no nextToken is returned.
{
+ "data":{
+ "StatisticalVariable":{
+ "arcs":{
+ "typeOf":{
+ "nodes":[
+ {
+ "name":"Max Temperature (Difference Relative To Base Date): Relative To 1990, Highest Value, Median Across Models",
+ "types":[
+ "StatisticalVariable"
+ ],
+ "dcid":"AggregateMax_MedianAcrossModels_DifferenceRelativeToBaseDate1990_Max_Temperature",
+ "provenanceId":"dc/base/HumanReadableStatVars"
+ },
+ {
+ "name":"Max Temperature (Difference Relative To Base Date): Relative To Between 2006 And 2020, Based on RCP 4.5, Highest Value, Median Across Models",
+ "types":[
+ "StatisticalVariable"
+ ],
+ "dcid":"AggregateMax_MedianAcrossModels_DifferenceRelativeToBaseDate2006To2020_Max_Temperature_RCP45",
+ "provenanceId":"dc/base/HumanReadableStatVars"
+ },
+ {
+ "name":"Max Temperature (Difference Relative To Base Date): Relative To Between 2006 And 2020, Based on RCP 8.5, Highest Value, Median Across Models",
+ "types":[
+ "StatisticalVariable"
+ ],
+ "dcid":"AggregateMax_MedianAcrossModels_DifferenceRelativeToBaseDate2006To2020_Max_Temperature_RCP85",
+ "provenanceId":"dc/base/HumanReadableStatVars"
+ },
+ {
+ "name":"Max Temperature (Difference Relative To Base Date): Relative To 2006, Based on RCP 4.5, Highest Value, Median Across Models",
+ "types":[
+ "StatisticalVariable"
+ ],
+ "dcid":"AggregateMax_MedianAcrossModels_DifferenceRelativeToBaseDate2006_Max_Temperature_RCP45",
+ "provenanceId":"dc/base/HumanReadableStatVars"
+ },
+ {
+ "name":"Max Temperature (Difference Relative To Base Date): Relative To 2006, Based on RCP 8.5, Highest Value, Median Across Models",
+ "types":[
+ "StatisticalVariable"
+ ],
+ "dcid":"AggregateMax_MedianAcrossModels_DifferenceRelativeToBaseDate2006_Max_Temperature_RCP85",
+ "provenanceId":"dc/base/HumanReadableStatVars"
+ }...
+ ]
+ }
+ }
+ }
+ },
+ "nextToken":"H4sIAAAAAAAA/2zJsQ6CMBQFUHut9fp0MNcPcyBhf5CSNOlA4C38PT/AfGyx3xAebY82ex99az71aiWOtf6vUTdlpm8SCIF3gVngQ2AR+BRIgS+BJvAt8HMCAAD//wEAAP//522gCWgAAAA="
+}
+
+
+
Example 6: Get a list of all existing entity types
+
+
Get all incoming linked nodes of node Class, with the typeof property. Since Class is the top-level entity in the knowledge graph, getting all directly linked nodes effectively gets all entity types.
+
+
Also note that the response contains a nextToken, so you need to send additional requests with the continuation tokens to get all the data.
+
+
Parameters:
+
+
nodes: "Class"
+property: "<-typeOf"
+
+
+
GET Request:
+
+
curl --request GET --url\
+ 'https://api.datacommons.org/v2/node?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI&nodes=Class&property=%3C-typeOf'
+
The Observation API fetches statistical observations. An observation is associated with an
+entity and variable at a particular date: for example, “population of USA in
+2020”, “GDP of California in 2010”, and so on.
List of DCIDs for the statistical variable to be queried.
+
+
+
entity.dcids
+
list of strings
+
Comma-separated list of DCIDs of entities to query. One of entity.dcids or entity.expression is required. Multiple entity.dcids parameters are allowed.
+
+
+
entity.expression
+
string
+
Relation expression that represents the entities to query. One of entity.dcids or entity.expression is required.
+
+
+
select Required
+
string literal
+
select=variable and select=entity are required. If specifed without select=date and select=value, no observations are returned. You can use this to first check the existence of variable-entity pairs in the data and fetch all the variables that have data for given entities.
+
+
+
select Optional
+
string literal
+
If used, you must specify both select=date and select=value. Returns actual observations, with the date and value for each variable and entity queried.
+
+
+
+
+
Date-time string formats
+
+
Here are the possible values for specifying dates/times:
+
+
LATEST: Fetch the latest observations only.
+
DATE_STRING: Fetch observations matching the specified date(s) and time(s). The value must be in the ISO-8601 format used by the target variable; for example, 2020 or 2010-12. To look up the format of a statistical variable, see below.
+
"": Return observations for all dates.
+
+
+
Find the date format for a statistical variable
+
+
Statistical variable dates are defined as yearly, monthly, weekly, or daily. For most variables, you can find out the correct date format by searching for the variable in the
+Statistical Variable Explorer and looking for the Date range. For example, for the variable Gini Index of Economic Activity, the date-time format is yearly, i.e. in YYYY format:
+
+
+
+
For other cases, you may need to drill down further to a timeline graph to view specific observations. For example, Mean Wind Direction, is measured at the sub-daily level, but the frequency is not clear (hourly or every two hours, etc.)
+
+
+
+
In these cases, do the following:
+
+
+
In the Statistical Variable Explorer, click on an example place to link to the variable’s page in the Knowledge Graph Browser.
+
Scroll to the Observations section and click Show Table to get a list of observations.
+
+
+
For example, in the case of Mean Wind Direction for Ibrahimpur, India, the observations table shows that the variable is measured every four hours, starting at midnight.
+
+
+
+
Response
+
+
Without select=date and select=value specified, the response looks like:
Metadata about the observations returned, keyed first by variable, and then by entity, such as the date range, the number of observations included in the facet etc.
+
+
+
observations
+
list of objects
+
Date and value pairs for the observations made in the time period
+
+
+
facets
+
object
+
Various properties of reported facets, where available, including the provenance of the data, etc.
+
+
+
+
+
Examples
+
+
Example 1: Get the latest observation for given entities
+
+
Specify date=LATEST to get the latest observations and values. In this example, we select the entity by its DCID using entity.dcids.
Example 3: Get the latest observations for all California counties
+
+
In this example, we use the chained expression
+(+) to specify “all contained places in
+California (dcid: geoId/06) of
+type County”. Then we specify the select fields to request actual observations
+with date and value for each variable
+(Count_Person) and
+entity (all counties in California).
The Resolve API returns a Data Commons ID (DCID) for entities in the graph.
+Each entity in Data Commons has an associated DCID which is used to refer to it
+in other API calls or programs. An important step for a Data Commons developer is to
+identify the DCIDs of entities they care about. This API searches for an entry in the
+Data Commons knowledge graph and returns the DCIDs of matches. You can use
+common properties or even descriptive words to find entities.
+
+
For example, you could query for “San Francisco, CA” or “San Francisco” to find
+that its DCID is geoId/0667000. You can also provide the type of entity
+(country, city, state, etc.) to disambiguate (Georgia the country vs. Georgia
+the US state).
+
+
+
Note: Currently, this endpoint only supports place entities.
+
+
+
+
IMPORTANT:
+ This endpoint relies on name-based geocoding and is prone to inaccuracies.
+ One common pattern is ambiguous place names that exist in different
+ countries, states, etc. For example, there is at least one popular city
+ called “Cambridge” in both the UK and USA. Thus, for more precise results,
+ please provide as much context in the description as possible. For example,
+ to resolve Cambridge in USA, pass “Cambridge, MA, USA” if you can.
Optional field which, where present, disambiguates between multiple results.
+
+
+
+
+
+
Note:
+ There is a deprecated field resolvedIds that is currently returned by the API. It will be removed soon. Examples below omit this redundant field.
+
+
+
Examples
+
+
Example 1: Find the DCID of a place by another known ID
+
+
This queries for the DCID of a place by its Wikidata ID. This property is represented in the graph by wikidataId.
+
+
Parameters:
+
+
nodes: "Q30"
+property: "<-wikidataId->dcid"
+
+
GET Request:
+
+
curl --request GET --url\
+'https://api.datacommons.org/v2/resolve?key=AIzaSyCTI4Xz-UW_G2Q2RfknhcfdAnTHq5X5XuI&nodes=Q30&property=%3C-wikidataId-%3Edcid'
+
Example 2: Find the DCID of a place by coordinates
+
+
This queries for the DCID of “Mountain View” by its coordinates. This is most often represented by the latitude and longitude properties on a node. Since the API only supports querying a single property, use the synthetic geoCoordinate property. To specify the latitude and longitude, use the # sign to separate both values. This returns all the places in the graph that contains the coordinate.
This queries for the DCID of “Georgia”. Notice that specifying Georgia without a type filter returns all possible DCIDs with the same name: the state of Georgia in USA (geoId/13), the country Georgia (country/GEO) and the city Georgia in the US state of Vermont (geoId/5027700).
+
+
Note the description property in the request. This currently only supports resolving place entities by name.
Example 4: Find the DCID of a place by name, with a type filter
+
+
This queries for the DCID of “Georgia”. Unlike in the previous example, here
+we also specify its type using a filter and only get one place in the response.
This endpoint makes it possible to query the Data Commons knowledge graph using
+SPARQL. SPARQL is a query language developed to retrieve data from RDF graph content on the web. It leverages the graph structure innate in the data it
+queries to return specific information.
+
+
+
Note: Data Commons only supports a limited subset of SPARQL functionality at this time: specifically, only the keywords WHERE, ORDER BY, DISTINCT, and LIMIT are supported.
+
+
+
Request
+
+
+
Note: GET requests are not provided because they are inconvenient to use with SPARQL.
Your API key. See the the section on authentication for details.
+
+
+
query Required
+
string
+
A SPARQL query string. In the query, all desired entities must be specified; wildcards are not supported. Each node or entity should have a typeOf condition, for example, ?ENTITY_NAME typeOf City.
{
+ "code":16,
+ "message":"Method doesn't allow unregistered callers (callers without established identity). Please use API Key or other form of API consumer identity to call this API.",
+ "details":[
+ {
+ "@type":"type.googleapis.com/google.rpc.DebugInfo",
+ "stackEntries":[],
+ "detail":"service_control"
+ }
+ ]
+}
+
+
+
The request is missing an API key or the parameter specifying it is misspelled. Please request your own API key.
+
+
Empty response
+
+
{}
+
+
+
This is most commonly seen when the value provided for a query parameter is misspelled or doesn’t exist. Make sure the values you are passing for parameters are spelled correctly, that you are correctly URL-encoding special characters in parameter values, and not URL-encoding parameter delimiters.
+
+
Marshaling errors
+
+
{
+ "code":13,
+ "message":"grpc: error while marshaling: proto: Marshal called with nil",
+ "details":[
+ {
+ "@type":"type.googleapis.com/google.rpc.DebugInfo",
+ "stackEntries":[],
+ "detail":"internal"
+ }
+ ]
+}
+
+
+
This is most commonly seen when a query parameter is missing, misspelled or incorrect. Check the spelling of query parameters, ensure all required parameters are sent in the request, that you are correctly URL-encoding special characters in parameter values, and not URL-encoding parameter delimiters.
dcids - A single node or range of cells representing nodes, identified by their DCIDs, whose members are sought.
+
+
+
Returns
+
+
The DCIDs of the cohort members. For a single DCID, the result is a column of members of the cohort represented by that DCID. For a row of DCIDs, the result is a matrix with each column the members of the cohort whose DCID serves as the column’s index. For a column of DCIDs, the result is a matrix with each row the members of the cohort whose DCID serves as the row’s index.
+
+
Example: Retrieve the list of cities that are members of the CDC 500 cohort
The =DCGETNAME formula returns the names associated with given DCIDs to a cell or range of cells.
+
+
Formula
+
+
=DCGETNAME(dcids)
+
+
+
Required arguments
+
+
+
dcids - A node or range of cells representing multiple nodes, identified by their DCIDs.
+
+
+
Returns
+
+
The names associated with given node DCIDs to a cell or a range of cells.
+
+
Examples
+
+
This section contains examples of using DCGETNAME to return the names associated with given DCIDs.
+
+
+
Note: Be sure to follow the instructions for for enabling the Sheets add-on before trying these examples.
+
+
+
Example 1: Retrieve the name of a place by its DCID
+
+
To retrieve the name of a place by its DCID:
+
+
+
Place your cursor in the cell where you want to add a DCID; in this case, cell A1, and enter geoId/06.
+
Move to the cell where you want to retrieve the place name.
+
Enter the formula =DCGETNAME(A1) to retrieve the name. California populates the cell.
+
+
+
+
+
Example 2: Retrieve the names of a list of power plants
+
+
To retrieve the names of a list of power plants:
+
+
+
Enter into column A the DCIDs that are shown in the following image.
+
In cell B2, enter the formula =DCGETNAME(A2:A4). The names of the power plants for each DCID populate column B.
+
+
+
+
+
Example 3: Retrieve the names of a list of statistical variables
+
+
Statistical variables are also nodes in the Data Commons knowledge with a DCID. To retrieve the names of a list of statistical variables:
+
+
+
Enter into column A the DCIDs that are shown in the following image.
+
In cell B2, enter the formula =DCGETNAME(A2:A4). The names of the variables for each DCID populate column B.
+
+
+
+
+
Error responses
+
+
If a DCID does not exist, the =DCGETNAME formula does not return a value. For example, because the DCID geoId/123123123 does not exist, no value is returned to cell B1 in the following sheet:
+
+
+
+
If you provide an empty cell for a DCID, the =DCGETNAME formula returns a value of #ERROR!, as shown show in the following image:
The =DCPROPERTY formula returns values associated with the given property for a single placeDCID or list of places.
+
+
Formula
+
+
=DCPROPERTY(dcids, property)
+
+
+
Required arguments
+
+
+
dcids: A single place node or range of cells representing nodes, identified by their DCIDs.
+
property: The label of the property whose value you are interested in, such as name for the name of a node, or typeOf for the type of a node. If you aren’t sure what properties are available for a particular DCID, you can use the Data Commons Knowledge Graph to look up the DCID of interest and see what properties it is associated with.
+
+
+
Returns
+
+
The values of the property label for the specified DCIDs.
+
+
Examples
+
+
This section contains examples of using the =DCPROPERTY to return values associated with the given property.
+
+
+
Note: Be sure to follow the instructions for for enabling the Sheets add-on before trying these examples.
+
+
+
Example 1: Retrieve the common name of a country by its DCID
+
+
To retrieve the name of a country by its DCID:
+
+
+
Place your cursor in the cell where you want to add a DCID; in this case, cell A1.
+
Enter country/CIV for the country Ivory Coast.
+
Place your cursor in cell B2 and enter =DCPROPERTY(A1, "name") to retrieve the Ivory Coast country names in column B; note that the French and English spellings for Ivory Coast appear in column B.
+
+
+
+
+
Example 2: Retrieve the order to which a plant belongs
+
+
To retrieve the order to which the plant Austrobaileya Scandens belongs:
+
+
+
Place your cursor in the cell where you want to add a DCID; in this case, cell A1.
+
Enter dc/bsmvthtq89217 for the plant Austrobaileya Scandens.
+
Place your cursor in cell B2 and enter =DCPROPERTY(A1, "order"). Austrobaileyales appears in cell B2.
+
+
+
+
+
Example 3: Retrieve the addresses of two high schools
+
+
To retrieve the addresses of Stuyvesant High School in New York and Gunn High School in California:
+
+
+
Place your cursor in cell A1 and enter nces/360007702877 for Stuyvesant Hight School in New York.
+
Place your cursor in cell A2 and enter nces/062961004587 for Gunn High School in California.
+
Place your cursor in cell B2, and enter the formula =DCPROPERTY(A1:A2, "address"). The addresses of both high schools are populated in column B.
+
+
+
+
+
Error responses
+
+
If you pass a nonexistent property, an empty value is returned. For example, because the “nonexistent property” does not exist, no value is returned to cell B1 in the following sheet:
+
+
+
+
If you pass a bad DCID, an empty value is returned:
+
+
+
+
If you pass an empty DCID, a response of #ERROR! is returned:
+
+
+
+
If you do not pass a required property argument, a response of #ERROR! is returned:
date: The date or dates of interest. If this argument is not specified, the API returns the latest variable observation. You can specify this argument as a single value, row, or column. All dates must be in ISO 8601 format (such as 2017, “2017”, “2017-12”) or as a Google sheets date value.
+
+
Returns
+
+
The value of the variable at those places on the specified date or on the latest available date, if no date is specified.
+
+
Examples
+
+
This section contains examples of using the =DCGET formula to returns the values of statistical variables such as Count_Person and Median_Income_Person.
+
+
+
Note: Be sure to follow the instructions for for enabling the Sheets add-on before trying these examples.
+
+
+
Example 1: Get the total population of Hawaii in 2017
+
+
To get the total population of Hawaii in 2017:
+
+
+
Place your cursor in the desired cell.
+
Enter the formula =DCGET("geoId/15", "Count_Person", 2017). The value 1425763 populates the cell.
+
+
+
Example 2: Get the population of five Hawaii counties in 2017
+
+
To get the population of the five counties in 2017:
+
+
+
Place your cursor in the desired cell; in this case A2, and enter the DCID of Hawaii, namely geoId/15.
+
In cell B2, enter the formula =DCPLACESIN(A2, "County"). The DCIDs of the Hawaii counties populate column B.
+
(Optional) In cell C2, enter =DCGETNAME(B2:B6) to retrieve the names of the counties in column C.
+
+
In cell D2, enter the formula =DCGET(B2:B6, "Count_Person", 2017).
+
+
+
+
The values populate column D.
+
+
+
+
+
+
Example 3: Get the median income of a single place in multiple years
+
+
This example shows how to get the median income in Hawaii for the years 2011 - 2013, with dates as columns:
+
+
+
In a new sheet, in row 1, create cells with the headings shown in the image below.
+
In cell A2, enter Hawaii, and in cell B2, geoId/15.
+
+
Select cells C2 to E2, and enter the formula =DCGET(B2, "Median_Income_Person", C1:E1).
+
+
+
+
The values populate C2, D2 and E2.
+
+
+
+
+
+
Example 4: Get the median age of multiple places in multiple years
+
+
The following examples demonstrate how to retrieve the median age of five counties in Hawaii for the years 2011 - 2015.
+
+
To get the results with the counties in rows and the dates in columns, do the following:
+
+
+
In a new sheet, in row 1, create cells with the headings shown in the image below, with columns for each year 2011 to 2015.
+
In cell A2, enter Hawaii, and in cell B2, geoId/15.
+
In cell C2, enter the formula =DCPLACESIN(, "County"). The county DCIDs populate column C.
+
In cell D2, enter the formula =DCGETNAME(C2:C6) . The county names populate column D.
+
Place your cursor in cell E2 and enter the formula =DCGET(C2:C6, "Median_Age_Person", E1:I1). The ages for each county and year appear in columns E to I.
+
+
+
+
+
To get the results with the counties in columns and the dates in rows, do the following:
+
+
+
In a new sheet, in column A, create cells with the headings shown in the image below.
+
In cell B1, enter Hawaii, and in cell B2, geoId/15
+
Manually enter the DCIDs for each county, in cells B3 to F3, as shown in the image below.
+
Place your cursor in cell B4 and enter the formula =DCGETNAME(B3:F3) . The county names populate column D.
+
+
Place your cursor in cell B5 and enter the formula =DCGET(B3:F3, "Median_Age_Person", A5:A9).
+
+
+
+
The ages for each county and year appear in rows 5 to 9.
+
+
+
+
+
+
Error responses
+
+
The =DCGET formula returns a blank value under the following circumstances:
+
+
+
A DCID does not exist (e.g. geoId/123123123)
+
You provide a nonexistent statistical variable (e.g. Count)
+
You provide an incorrectly formatted date (e.g. July 12, 2013)
+
+
+
For example, because the geoId/123123123 DCID does not exist, no value is returned to cell B1 in the following sheet for the formula =DCGET(A1, "Count_Person"):
+
+
+
+
If you fail to provide all required arguments, you will get a response of #ERROR!:
The Data Commons Google Sheets add-on allows you to import data from the Data Commons knowledge graph. The add-on provides an interface for finding a location’s unique Data Commons identifier (DCID), and several custom functions for importing data into a spreadsheet.
+
+
Read our step-by-step guides for examples on using the add-on for various analysis and visualization use cases.
Select Extensions > Data Commons > Fill place dcids.
+
+
+
+
Note: None of the Data Commons Sheets functions will work in a spreadsheet until you have enabled the add-on by opening the Fill place dcids sidebar. You need to open the sidebar every time you reopen the Sheets application or create a new sheet.
+
+
+
Find a place’s DCID
+
+
The Data Commons Sheets add-on provides the ability to look up a place’s DCID by using the Fill place dcids feature. To find a place’s DCID:
+
+
+
In Google Sheets, open a new or existing spreadsheet.
+
Select the destination cell where you want to add a place’s DCID.
+
+
Select Extensions > Data Commons > Fill place dcids.
+
+
+
+
In the Fill place dcids for selected cells sidebar that appears, start typing the name of the place you are searching for.
+
+
From the drop-down menu, select the place you want, and its DCID appears in the cell that you selected. For example, the following image shows the place names that match “Hawaii”.
+
+
+
+
+
+
Data Commons Sheets functions
+
+
The Data Commons Sheets add-on includes the five formulas listed in the following table. Click the links in the table for detailed information on each formula.
A single value can be a string literal, such as "geoId/05" or "County" and must be enclosed quotation marks.
+
Multiple values must be a range of cells (row or column), such as A2:A5, and are not enclosed in quotation marks..
+See below for examples.
+
+
+
+
Note: It’s always best to minimize the number of calls to Data Commons functions by using arguments containing a column or row of values. This is because a spreadsheet will make one call to a Google server per function call, so if your sheet contains thousands of separate calls to a function, it will be slow and return with errors.
+
+
+
Get started with Data Commons functions
+
+
Here’s a quick demo on using several of the Data Commons functions to get population data for all counties in the state of California.
+
+
+
Open a new sheet and create 3 column headings: DCID, County name, and Population.
+
Select cell A2 and enter the following formula to get a list of the DCIDs of all counties in California, whose DCID is geoId/06: =DCPLACESIN("geoId/06", "County"). The column fills with 58 DCIDs.
+
Select cell B2 and enter the following formula to get the names corresponding to all the DCIDs: =DCGETNAME(A2:A59)
+
Select cell C3 and enter the following formula to get the populations of each of the counties, using the statistical variable Count_Person: =DCGET(A2:A59, "Count_Person")
+
+
+
Your spreadsheet should now look like this:
+
+
+
+
Sort data
+
+
Because the Data Commons add-on does not actually store values, but only formulas, in a sheet, you can’t directly sort the data. To sort the data, you need to copy it as values to a new sheet and then sort as usual:
+
+
+
Select all the columns in the sheet and select Edit > Copy.
+
Select Insert > Sheet to create a new sheet.
+
Select Edit > Paste special > Values only. You can now sort each column as desired.
The =DCPLACESIN formula returns lists of child places from a list of parent PlaceDCIDs. It only returns children with a place type that matches the place_type parameter, such as State, Country, and so on.
+
+
Formula
+
+
=DCPLACESIN(dcids, place_type)
+
+
+
Required arguments
+
+
+
dcids: A single place node or range of cells representing place nodes, identified by their DCIDs.
+
place_type: The type of the contained child place nodes to filter by. For example,City and Countyare contained within State. For a full list of available types, see the place types page.
+
+
+
Returns
+
+
A list of child place DCIDs of the specified place DCIDs, of the specified place type.
+
+
Examples
+
+
This section contains examples of using the =DCPLACESIN formula to return places contained in another place.
+
+
+
Note: Be sure to follow the instructions for for enabling the Sheets add-on before trying these examples.
+
+
+
Example 1: Retrieve a list of counties in Delaware
+
+
To retrieve a list of counties in Delaware:
+
+
Place your cursor in the cell where you want to add the DCID for Delaware; in this case, cell A2.
+
Enter the Delaware DCID of geoId/10.
+
(Optional) In cell B2, enter DCGETNAME(A2) to retrieve Delaware’s name from the DCID in cell A2.
+
In cell C2, enter the formula =DCPLACESIN(A2, "County"). The DCIDs for the three Delaware counties populate column C.
+
In cell D2, enter the formula DCGETNAME(C2:C4) to retrieve the names of the counties.
+
+
+
+
+
Example 2: Retrieve congressional districts in Alaska and Hawaii
+
+
To retrieve the congressional districts in Alaska and Hawaii:
+
+
+
In cell A2, enter geoId/02 for the DCID of Alaska and in cell A3, enter geoId/15 for the DCID of Hawaii.
+
(Optional) In cell B1, enter =DCGETNAME(A2:A3) to retrieve the names of Alaska and Hawaii into column B.
+
In cell C2, enter =DCPLACESIN(A2:A3, "CongressionalDistrict") to retrieve the DCIDs of the congressional districts.
+
In cell D2, enter =DCGETNAMES(C2:C4) to retrieve the names of the congressional districts.
+
+
+
+
+
Error responses
+
+
If a DCID does not exist, the =DCPLACESIN formula returns a value of #REF!. For example, because the geoId/123123123 DCID does not exist, an error of #REF! is returned to cell B1 in the following sheet:
+
+
+
+
If you provide an empty cell for a DCID, the =DCPLACESIN formula returns a value of #ERROR!, as shown show in the following image:
+
+
+
+
Finally, if you provide an invalid property to the =DCPLACESIN formula, an error of #REF! is also returned, as follows:
Throughout COVID-19 pandemic, the Data Commons team worked to upload COVID-19 data as it became available, helping public and private sector analysts create evidence-based policy to combat the public health crisis. This tutorial presents an example of how to obtain use Google Sheets to obtain the data from Data Commons and create visualizations for it.
+
+
Step 1: Setup
+
Pull up Google Sheets and create a new, blank spreadsheet. You can title it Data Commons COVID-19 analysis or any other name of your choosing.
+
+
+
+
To enable the Data Commons API in your spreadsheet, ensure that the Data Commons extension is installed and available under the Extensions menu. Hover over the Data Commons menu item, then click on the Fill place DCIDs option.
+
+
+
+
A menu should pop up on the right side of the Sheets web application. Type the name of any place desired; its DCID should populate into the A1 entry of the chart. This step is required to enable the Data Commons API.
+
+
+
+
Next, double-click on A1 in the chart and type country/USA.
+
+
+
+
Step 2: Retrieve place names and DCIDs
+
To obtain the DCIDs for all the states, you can use the plugin function DCPLACESIN. In cell B1, type =DCPLACESIN(A1, "State"). Sheets provides pointers to help guide your function inputs. Your spreadsheet output should look like this:
+
+
+
+
Finally, you’ll want to retrieve the state names and position them conveniently near these DCIDs. You can use the add-on function DCGETNAME to access this information. In cell C1, type =DCGETNAME(B1:B). Your final output should look like this:
+
+
+
+
Step 3: Populate the spreadsheet with COVID information
+
Let’s analyze each state’s cumulative count of deaths due to COVID as of December 31, 2022. To do this, we get the value of the statistical variableCumulativeCount_MedicalConditionIncident_COVID_19_PatientDeceased for each state on the date specified. You can use the DCGET method to do this.
+
+
In cell D1, type =DCGET(B1:B, "CumulativeCount_MedicalConditionIncident_COVID_19_PatientDeceased", "2022-12-31"). Your final output should look like this:
+
+
+
+
Step 4: Visualize the data
+
As a final step, you can use Google Sheets’ Chart option to map this data! Select cells C1 to D52, then select Insert > Chart. Your spreadsheet will look like this:
+
+
+
+
Feel free to drag the histogram out of the way of the numbers! As a final step, in the right sidebar Chart editor, from the Setup > Chart type drop-down menu, select Map. Then, from the Customize > Geo > Region drop-down menu, select the United States. Your final sheet should look something like this:
Obtain latitude information for country capitals in South America
+
+
Introduction
+
The Data Commons Sheets add-on allows you to obtain basic information about the entities in the knowledge graph by retrieving their properties. This tutorial walks you through the DCPROPERTY function that enables this.
+
+
Step 1: Setup
+
Pull up Google Sheets and create a new, blank spreadsheet. You can title it Data Commons South American capitals’ latitude or any other name of your choosing.
+
+
+
+
To enable the Data Commons API in your spreadsheet, ensure that the Data Commons extension is installed and available under the Extensions menu. Hover over the Data Commons menu item, then click on the Fill place DCIDs option.
+
+
+
+
Step 2: Retrieve place names and DCIDs
+
Double-click on the A1 cell and enter southamerica (the DCID for the continent of South America).
+
+
+
+
To obtain the DCIDs for all the countries, you can use the add-on function DCPLACESIN. In cell B1, type =DCPLACESIN(A1, "Country"). Sheets provides pointers to help guide your function inputs. Your spreadsheet output should look like this:
+
+
+
+
Next, you’ll want to retrieve the country names and position them conveniently near these DCIDs. You can use the addon-on function DCGETNAME to access this information. In cell C1, type =dcgetname(B1:B). Your final output will look like this:
+
+
+
+
Step 3: Populate the spreadsheet with capital and latitude information
+
In this step, you will obtain all South American countries’ capitals and latitudes. To do this, you will need to get the value of the property names latitude and administrativeCapital for each country on the date specified. (As an aside, if you’d like to see what properties are available for any given entity, Data Commons provides a Knowledge Graph tool enabling you to look up any entity in the graph and view its associated properties.) You can use the DCPROPERTY method to do this.
+
+
In cell D1, =DCPROPERTY(B1:B, "administrativeCapital"). Your output should look like this:
+
+
+
+
Now, to get the latitude of each capital, in cell E1, type =DCPROPERTY(D1:D, "latitude").
+
+
+
+
Finally, use the DCGETNAME function again, against column D, to get the names of the capitals. Try it yourself!
The Data Commons API enables easy access to health data for the 500 cities the U.S. Centers for Disease Control and Prevention (CDC) has prioritized for public health information tracking. This tutorial will walk you through accessing and analyzing that information and scoring each of the cities according to adults residents’ excellence in sleep habits, for the year 2020.
+
+
Step 1: Setup
+
Pull up Google Sheets and create a new, blank spreadsheet. You can title it Data Commons CDC 500 sleep analysis or any other name of your choosing.
+
+
+
+
To enable the Data Commons API in your spreadsheet, ensure that the Data Commons extension is installed and available under the Extensions menu. Hover over the Data Commons menu item, then click on the Fill place DCIDs option.
+
+
+
+
Step 2: Get the DCIDs and names of cohort members
+
Data Commons provides the method DCCOHORTMEMBERS for obtaining the members of a Data Commons cohort. Here, you’ll use this method to retrieve the cities in the CDC 500 cohort. Start by double-clicking on A1 in the chart and enter CDC500_City.
+
+
+
+
In cell B1, enter =DCCOHORTMEMBERS(A1). The output should look like this:
+
+
+
+
To get the names of these cities, enter =DCGETNAME(B1:B) into cell C1. The output should look like this:
+
+
+
+
Step 3: Obtain the sleep health level for each city
+
We will use the percentage of chronically restless residents in each city using the DCGET method with the statistical variable Percent_Person_SleepLessThan7Hours. (More information on statistical variables is available in the glossary.) Enter =DCGET(B1:B, "Percent_Person_SleepLessThan7Hours", "2020") into cell D1 in your spreadsheet. The output should look like this:
+
+
+
+
Step 4: Sort on sleep score
+
+
+
Select columns B, C, and D, and choose Edit > Copy.
+
Select Insert > Sheet to add a new sheet.
+
Select Edit > Paste special > Values only.
+
Select column C, click the down arrow, and select Sort sheet Z to A.
Data Commons Web Component for visualizing one or more statistical variables around one or more places on a bar chart.
+
+
+
+
Usage
+
+
+
+
+
+
+
<datacommons-bar
+ header="Populations of USA, India, and China"
+ places="country/USA country/IND country/CHN"
+ variables="Count_Person"
+ maxPlaces="15"
+></datacommons-bar>
+
+
+
<datacommons-bar
+ header="Most populous states in the US"
+ parentPlace="country/USA"
+ childPlaceType="State"
+ variables="Count_Person"
+ maxPlaces="15"
+></datacommons-bar>
+
+
+
+
+
+
+
Attributes
+
+
Required
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
childPlaceType
+
string
+
Child place types to plot. Example: State. For a list of available place types, see the place types page. Optional if places is specified.
+
+
+
header
+
string
+
Chart title.
+
+
+
parentPlace
+
string
+
Parent place DCID to plot. Example: country/USA. Optional if places is specified.
+
+
+
places
+
list
+
Places DCIDs to plot, as a space separated list of strings. Example: "geoId/12 geoId/13". Optional if childPlaceType and parentPlace are specified.
+
+
+
variables
+
list
+
Variable DCID(s) to plot, as a space separated list of strings. Example: "Count_Person Count_Farm".
+
+
+
+
+
Optional
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
barHeight
+
number
+
Bar height (in px) for horizontal charts.
+
+
+
colors
+
list
+
Specify custom color for each variable. Pass in colors in the same order as variables.
Values should follow CSS specification (keywords, rgb, rgba, hsl, #hex). Separate multiple values with spaces, e.g., "#ff0000 #00ff00 #0000ff". Make sure individual colors have no spaces. For example, use rgba(255,0,0,0.3) instead of rgba(255, 0, 0, 0.3).
+
+
+
disableEntityLink
+
boolean
+
Include to disable entity (place) links in the x-axis. Default: false (links are enabled)
+
+
+
+
+
+
+
+
horizontal
+
boolean
+
Include to draw bars horizontally instead of vertically.
+
+
+
lollipop
+
boolean
+
Include to draw lollipops instead of bars.
+
+
+
maxPlaces
+
number
+
Maximum number of child places to plot. Default: 7.
+
+
+
maxVariables
+
number
+
Maximum number of varibales to plot. Default: show all variables.
+
+
+
sort
+
string
+
Bar chart sort order.
Options: - ascending (ascending by the variable’s value) - descending (descending by variable’s value) - ascendingPopulation (ascending by the place’s population) -descendingPopulation (descending by the place’s population)
Default: descendingPopulation
+
+
+
stacked
+
boolean
+
Include to draw as stacked bar chart instead of grouped chart.
+
+
+
subscribe
+
string
+
Listen for data changes on this event channel. Channel name should match the publish name on a control component. Example: datacommons-slider
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
defaultVariableName
+
string
+
To be used with variableNameRegex. If specified and no variable name is extracted out with the regex, use this as the variable name. e.g., if the variableNameRegex is “(.*?)(?=:)”, and the defaultVariableName is “Total”, for a variable named “variable 1”, it will become “Total”.
+
+
+
placeNameProp
+
string
+
Optionally specify the property to use to get the place names.
+
+
+
showExploreMore
+
boolean
+
Include to show “Explore more” link in the footer, which takes the user to Datacommons.org’s visualization tools.
+
+
+
variableNameRegex
+
string
+
Optionally specify regex to use to extract out variable name. e.g., if the variableNameRegex is “(.*?)(?=:)”, only the part before a “:” will be used for variable names. So “variable 1: test” will become “variable 1”.
+
+
+
yAxisMargin
+
number
+
Set size (in px) of y-axis’ margin to fit the axis label text. Default: 60px.
+
+
+
+
+
Examples
+
+
Example 1: A bar chart of population for states in the US
+
+
Code:
+
<datacommons-bar
+ header="Population of US States"
+ parentPlace="country/USA"
+ childPlaceType="State"
+ variables="Count_Person"
+></datacommons-bar>
+
+
+
+
+
+
+
Example 2: A bar chart of population for specific US states
+
+
Code:
+
<datacommons-bar
+ header="Population of US States"
+ variables="Count_Person"
+ places="geoId/01 geoId/02"
+></datacommons-bar>
+
+
+
+
+
+
+
Example 3: A stacked bar chart of population by gender for specific US states
+
+
Code:
+
<datacommons-bar
+ header="Population of US States"
+ variables="Count_Person"
+ places="geoId/01 geoId/02"
+ stacked
+></datacommons-bar>
+
+
+
+
+
+
+
Example 4: A horizontal, stacked bar chart of median income for specific US states
Optionally specify a custom chart color scheme for the display variable. Will interpolate colors linearly depending on how many are passed in.
Values should follow CSS specification (keywords, rgb, rgba, hsl, #hex). Separate multiple values with spaces, e.g., "#ff0000 #00ff00 #0000ff". Make sure individual colors have no spaces. For example, use rgba(255,0,0,0.3) instead of rgba(255, 0, 0, 0.3).
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
+
+
Examples
+
+
Example 1: Show percentage of US population that are internet users
+
+
Code:
+
<datacommons-gauge
+ header="Percentage of US Population that are Internet Users"
+ place="country/USA"
+ variable="Count_Person_IsInternetUser_PerCapita"
+ min="0"
+ max="100"
+></datacommons-gauge>
+
Specific date to show data for. ISO 8601 format (e.g. “YYYY”, “YYYY-MM”, “YYYY-MM-DD”).
Note: Ensure your variable has data available at the specified date using the Stat Var Explorer
Default: Most recent data available.
+
+
+
unit
+
string
+
Unit the variable is measured in.
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
+
+
Examples
+
+
Example 1: Show percentage of US population that are internet users
+
+
Code:
+
<datacommons-highlight
+ header="Percentage of US Population that are Internet Users"
+ place="country/USA"
+ variable="Count_Person_IsInternetUser_PerCapita"
+></datacommons-highlight>
+
+ info
+ Are you using the Data Commons Web Components?
+ Sign up for our announcement mailing list to stay up to date with our latest
+ developments. Join the list by
+ clicking here, then clicking the “Join group” button.
+
+
+
Usage
+
+
Include datacommons.js in your html’s
+<head>...</head> tag. Then use Data Commons
+web component
+tags (e.g. datacommons-line) to add embedded data visualizations.
Data Commons web components visualize statistical variables about one or more
+places. Variables and places are identified by
+Data Commons Identifiers, or
+DCIDs.
+
+
To look up a DCID for an entity or variable, see the different methods described in this page.
+
+
To find places available for a statistical variable, see this page.
Child place types to plot. Example: State. For a list of available place types, see the place types page. Optional if places is specified.
+
+
+
header
+
string
+
Chart title.
+
+
+
parentPlace
+
string
+
Parent place DCID to plot. Example: country/USA. Optional if places is specified.
+
+
+
places
+
list
+
Places DCIDs to plot, as a space separated list of strings. Example: "geoId/12 geoId/13". Optional if childPlaceType and parentPlace are specified.
+
+
+
variables
+
list
+
Variable DCID(s) to plot, as a space separated list of strings. Example: "Count_Person Count_Farm".
+
+
+
+
+
Optional
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
colors
+
list
+
Specify custom color for each variable. Pass in colors in the same order as variables.
Values should follow CSS specification (keywords, rgb, rgba, hsl, #hex). Separate multiple values with spaces, e.g., "#ff0000 #00ff00 #0000ff". Make sure individual colors have no spaces. For example, use rgba(255,0,0,0.3) instead of rgba(255, 0, 0, 0.3).
+
+
+
timeScale
+
string
+
One of "year", "month", or "day". If provided, the x-axis will draw a tick mark and label at that time scale.
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
defaultVariableName
+
string
+
To be used with variableNameRegex. If specified and no variable name is extracted out with the regex, use this as the variable name. e.g., if the variableNameRegex is “(.*?)(?=:)”, and the defaultVariableName is “Total”, for a variable named “variable 1”, it will become “Total”.
+
+
+
placeNameProp
+
string
+
Optionally specify the property to use to get the place names.
+
+
+
showExploreMore
+
boolean
+
Include to show “Explore more” link in the footer, which takes the user to Datacommons.org’s visualization tools.
+
+
+
variableNameRegex
+
string
+
Optionally specify regex to use to extract out variable name. e.g., if the variableNameRegex is “(.*?)(?=:)”, only the part before a “:” will be used for variable names. So “variable 1: test” will become “variable 1”.
+
+
+
+
+
Examples
+
+
Example 1: Plot a single variable over time for a single place
+
+
Show the number of people under poverty level in the US over time.
+
+
Code:
+
<datacommons-line
+ header="Population Below Poverty Level Status in United States"
+ places="country/USA"
+ variables="Count_Person_BelowPovertyLevelInThePast12Months"
+></datacommons-line>
+
+
+
+
+
Example 2: Plot a single variable over time for multiple places
+
+
Code:
+
<datacommons-line
+ header="Population for USA, India, and China"
+ places="country/USA country/IND country/CHN"
+ variables="Count_Person"
+></datacommons-line>
+
+
+
+
+
Example 3: Plot a single variable for all child places in a parent place
+
+
Show population for all counties in Alaska, USA.
+
+
Code:
+
<datacommons-line
+ header="Population of counties in Alaska"
+ parentPlace="geoId/02"
+ childPlaceType="County"
+ variables="Count_Person"
+></datacommons-line>
+
+
+
+
+
Example 4: Plot multiple variables for a single place
+
+
Show number of households without internet and number of households without health insurance for California, USA.
+
+
Code:
+
<datacommons-line
+ header="Population by gender of California"
+ places="geoId/06"
+ variables="Count_Household_InternetWithoutSubscription Count_Household_NoHealthInsurance"
+></datacommons-line>
+
Include to allow zooming and panning using the mouse and show zoom-in and zoom-out buttons.
+
+
+
colors
+
list
+
List up to three colors to define a custom color scale.
Values should follow CSS specification (keywords, rgb, rgba, hsl, #hex). Separate multiple values with spaces, e.g., "#ff0000 #00ff00 #0000ff". Make sure individual colors have no spaces. For example, use rgba(255,0,0,0.3) instead of rgba(255, 0, 0, 0.3).
- If one color is given: a luminance based color scale will be used - If two colors are given: a divergent color scale will be used, with the first color corresponding to the min value, and the second color corresponding to the max value. - If three colors are given: a color scale with the first three colors corresponding to [min, mean, max] values will be used.
+
+
+
date
+
string
+
Specific date to show data for. ISO 8601 format (e.g. “YYYY”, “YYYY-MM”, “YYYY-MM-DD”).
Note: Ensure your variable has data available at the specified date using the Stat Var Explorer
Default: Most recent data available.
+
+
+
subscribe
+
string
+
Listen for data changes on this event channel. Channel name should match the publish name on a control component. Example: datacommons-slider
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
geoJsonProp
+
string
+
Optionally specify the property to use to get geojsons.
+
+
+
placeNameProp
+
string
+
Optionally specify the property to use to get the place names.
+
+
+
showExploreMore
+
boolean
+
Include to show “Explore more” link in the footer, which takes the user to Datacommons.org’s visualization tools.
+
+
+
+
+
Examples
+
+
Example 1: Show a population map for the year 2020
+
+
A map of population below poverty level in US States in the year 2020.
+
+
Code:
+
<datacommons-map
+ header="Population Below Poverty Level Status in Past Year in States of United States (2020)"
+ parentPlace="country/USA"
+ childPlaceType="State"
+ variable="Count_Person_BelowPovertyLevelInThePast12Months"
+ date="2020"
+></datacommons-map>
+
Variable DCID(s) to plot, as a space separated list of strings. Example: "Count_Person Count_Farm".
+
+
+
+
+
Optional
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
colors
+
list
+
Specify custom color for each variable. Pass in colors in the same order as variables.
Values should follow CSS specification (keywords, rgb, rgba, hsl, #hex). Separate multiple values with spaces, e.g., "#ff0000 #00ff00 #0000ff". Make sure individual colors have no spaces. For example, use rgba(255,0,0,0.3) instead of rgba(255, 0, 0, 0.3).
+
+
+
donut
+
boolean
+
Include to draw as a donut chart instead of a pie chart.
+
+
+
subheader
+
string
+
Text to add under the header.
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
+
+
Examples
+
+
Example 1: Multiple variables for a single place
+
+
Show the split of median income by gender in California as a pie chart.
+
+
Code:
+
<datacommons-pie
+ header="Median Income by gender in California"
+ place="geoId/06"
+ variables="Median_Income_Person_15OrMoreYears_Male_WithIncome Median_Income_Person_15OrMoreYears_Female_WithIncome"
+></datacommons-pie>
+
+
+
+
+
Example 2: Multiple variables for a single place, as a donut chart
+
+
Show the split of median income by gender in California as a donut chart.
+
+
Code:
+
<datacommons-pie
+ header="Median Income by gender in California"
+ place="geoId/06"
+ variables="Median_Income_Person_15OrMoreYears_Male_WithIncome Median_Income_Person_15OrMoreYears_Female_WithIncome"
+ donut
+></datacommons-pie>
+
Variable DCID(s) to plot, as a space separated list of strings. Example: "Count_Person Count_Farm". At least 2 variables must be provided, and only the first 2 variables will be plotted.
+
+
+
+
+
Optional
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
highlightBottomLeft
+
boolean
+
Include to label outliers in the bottom left quadrant. Defaults to false.
+
+
+
highlightBottomRight
+
boolean
+
Include to label outliers in the bottom right quadrant. Defaults to false.
+
+
+
highlightTopLeft
+
boolean
+
Include to label outliers in the top left quadrant. Defaults to false.
+
+
+
highlightTopRight
+
boolean
+
Include to label outliers in the top right quadrant. Defaults to false.
+
+
+
showPlaceLabels
+
boolean
+
Include to label all points with the place they correspond to. Defaults to false.
+
+
+
showQuadrants
+
boolean
+
Include to show grid lines delimiting top right, top left, bottom right, and bottom left quadrants. Defaults to false.
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
placeNameProp
+
string
+
Optionally specify the property to use to get the place names.
+
+
+
showExploreMore
+
boolean
+
Include to show “Explore more” link in the footer, which takes the user to Datacommons.org’s visualization tools.
+
+
+
+
+
Examples
+
+
Example 1: Plot population vs median household income for US states
+
+
Code:
+
<datacommons-scatter
+ header="Population vs Median Household Income for US States"
+ parentPlace="country/USA"
+ childPlaceType="State"
+ variables="Count_Person Median_Income_Household"
+></datacommons-scatter>
+
<!-- Bar chart listening for date change events on the "dc-bar" channel -->
+<datacommons-bar
+ header="Population below the poverty line in the US, Russia, and Mexico (${date})"
+ variables="sdg/SI_POV_DAY1"
+ places="country/USA country/RUS country/MEX"
+ subscribe="dc-bar"
+ date="HIGHEST_COVERAGE"
+>
+ <!-- Place slider in the component's footer and publish events on the "dc-bar" channel -->
+ <datacommons-slider
+ variables="sdg/SI_POV_DAY1"
+ places="country/USA country/RUS country/MEX"
+ publish="dc-bar"
+ slot="footer"
+ >
+ </datacommons-slider>
+</datacommons-bar>
+
+
+
+
+
+
+
Attributes
+
+
Required
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
childPlaceType
+
string
+
Child place types of date range. Example: State. For a list of available place types, see the place types page.
optional if dates is specified.
+
+
+
dates
+
list
+
Set date option range. Example: "2001 2002 2003"
optional if variable, parentPlace, and childPlaceType are specified.
+
+
+
parentPlace
+
string
+
Parent place DCID of date range. Example: country/USA.
optional if dates is specified.
+
+
+
publish
+
string
+
Event name to publish on slider change.
+
+
+
variable
+
string
+
Variable DCID of date range. Example: Count_Person.
optional if dates is specified.
+
+
+
+
+
Optional
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
header
+
string
+
Override default header text.
+
+
+
value
+
number
+
Initial slider value.
+
+
+
+
+
Advanced Configuration
+
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
apiRoot
+
string
+
Domain to make data fetch API calls from. Used primarily for fetching data from custom DCs.
Default: https://datacommons.org.
+
+
+
+
+
Examples
+
+
Example 1: Use slider to change dates on a datacommons-map web component
+
+
Code:
+
<!-- Listen for date changes on the "dc-map" channel -->
+<datacommons-map
+ header="Population"
+ parentPlace="country/USA"
+ childPlaceType="State"
+ subscribe="dc-map"
+ variable="Count_Person"
+></datacommons-map>
+
+<!-- Publish date changes on the "dc-map" channel -->
+<datacommons-slider
+ publish="dc-map"
+ variable="Count_Person"
+ parentPlace="country/USA"
+ childPlaceType="State"
+></datacommons-slider>
+
+
+
+
+
+
+
+
+
Example 2: Use slider to change dates on a datacommons-bar web component
+
+
Code:
+
<!-- Bar chart listening for date change events on the "dc-bar" channel -->
+<datacommons-bar
+ header="Population below the poverty line in the US, Russia, and Mexico (${date})"
+ variables="sdg/SI_POV_DAY1"
+ places="country/USA country/RUS country/MEX"
+ subscribe="dc-bar"
+ date="HIGHEST_COVERAGE"
+>
+ <!-- Place slider in the component's footer and publish events on the "dc-bar" channel -->
+ <datacommons-slider
+ variables="sdg/SI_POV_DAY1"
+ places="country/USA country/RUS country/MEX"
+ publish="dc-bar"
+ slot="footer"
+ >
+ </datacommons-slider>
+</datacommons-bar>
+
+ Custom footer here. This is a long custom footer. Lorem ipsum dolor sit
+ amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut
+ labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud
+ exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
+ Duis aute irure dolor in reprehenderit in voluptate velit esse cillum
+ dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non
+ proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
+
The Data Commons repository is available as BigQuery tables in the Analytics Hub. If you have a Google Cloud Platform account, you can use Analytics Hub to issue SQL queries against the Data Commons tables. For more information, see the Analytics Hub introduction.
+
+
+
Note: Analytics Hub is no longer being updated with Data Commons data, and the Data Commons tables may be turned down. If you want to continue to use this, please fill out this form to tell us about your use case.
+
+
+
Tip: Before you start, you may find it helpful to review Data Commons key concepts.
+
+
In these pages are sample SQL queries grouped together by category. You can copy and paste the queries into the BigQuery Studio in the Cloud Console.
This page illustrates how you can join external datasets with Data Commons by relying on unique IDs and geo locations. For the examples below, we use other public datasets in BigQuery Analytics Hub, but they can be any other private/public dataset.
We use the Fatal Accidents dataset from National Highway Traffic Safety Administration to compute counties with highest fatal accidents per capita. We map to DC counties using the FIPS or geoId, and use total population statistics. Loving County, TX (the least populated county in main US) and Kenedy County, TX are at the top.
We use Google’s Project SunRoof dataset to compute solar potential for low-income Zip code areas in the US. From 500 Zip code areas with the lowest median income, we compute those Zip codes that have the highest solar potential (among those that were sufficiently qualified). Of the 500, we find that 133 of them had > 50% potential.
From the OpenStreetMap Public Dataset, we compute the US counties with most fire-hydrants per unit area. To do this, we use the geo boundaries in DC to map latitude/longitude to US counties and get their corresponding land area values. Alexandria County, Virginia is at the top of the list.
The queries below include specific place DCID (e.g., ‘geoId/06’) and place type (e.g., ‘County’) string constants. Replace those to customize the queries to your needs.
Data Commons has benefited greatly from our collaborations with different government organizations and academic institutions and is looking to expand the set of collaborative projects. In particular, we are looking for partners to:
Data Commons welcomes patches and contributions to this project from everyone, new or experienced!
+
+
Ways to contribute
+
+
Add data
+
+
We welcome contributions of public data to the Data Commons knowledge graph. Data added will be accessible via Data Commons tools and APIs. We’ve bootstrapped the knowledge graph with these datasets from US Census, World Bank, CDC, NOAA, NASA, etc. However, Data Commons is meant to be for the community, by the community. We’re excited to work with you to make public data accessible to everyone. If you are interested in importing your data to Data Commons, please file a data request in our issue tracker. You can see a list of existing requests here.
+
+
Create new curriculum
+
+
Data Commons allows for easy acess to real data that can enrich the experience of students and instructors in educational contexts. We’re posting template data science assignments to assist educators with integrating real data into their courses on the courseware page. If you use Data Commons for your classes, have courseware to share, or find any of this material helpful, we want to hear about it! Please fill out this form.
+
+
Create a new tool
+
+
Data Commons welcomes the development of new tools that make the data on Data Commons more accessible to end users. We have an extensive REST API that can be used to power applications on top of our data. If you would like to build a new tool, contact the team through this form or create a PR in the Data Commons tools repo.
+
+
Share analysis
+
+
Example analyses are available on the tutorials page. To add your analysis on that page, open a PR in the Data Commons documentation repo with the title of the analysis and links to its Colab notebook and Github raw .ipynb file.
Contributions to this project must be accompanied by a Contributor License
+Agreement. You (or your employer) retain the copyright to your contribution;
+this simply gives us permission to use and redistribute your contributions as
+part of the project. Head over to https://cla.developers.google.com/ to see
+your current agreements on file or to sign a new one.
+You generally only need to submit a CLA once, so if you’ve already submitted one
+(even if it was for a different project), you probably don’t need to do it
+again.
+
+
Become familiar with the project
+
+
You can read about Data Commons concepts and explore existing data
+and tools on datacommons.org.
The curriculum is organized in self-contained modules. Instructors (and students) are welcome to consume or work through any of the modules or the components within any module. Each module is available as a detailed document with several pedagogical notes, objectives and an outline/table of contents to allow easy navigation.
+
+
To find what you may be looking for, or to use any content in your own courses/curriculum, we recommend the following approach:
+
+
+
+
Navigate to the Key Themes pages. It lists several key themes along with some pointers to specific modules which have the complete details.
+
+
+
Navigate to the Modules page. For each module, we describe its goal and include its table of contents. If you find what you are looking for (e.g., search “categorical vs numeric variables” and you should find yourself at the second module), you can then access the module directly for the content.
“Data literacy with Data Commons” comprises curriculum/course materials for instructors, students and other practitioners working on or helping others become data-literate. This includes detailed modules with pedagogical narratives, explanations of key concepts, examples, and suggestions for exercises/projects focused on advancing the consumption, understanding and interpretation of data in the contemporary world. In our quest to expand the reach and utility of this material, we assume no background in computer science or programming, thereby removing a key obstacle to many such endeavors.
+
+
Objectives
+
+
+
Exposing students (and practitioners) to the basics of data comprehension and interpretation.
+
Introducing some basic and intermediate data-driven decision making concepts.
+
Explicitly cater to the needs of students (and practitioners) who have no prior programming experience and a limited exposure to basic statistical concepts.
+
Adopt a narrative-based approach to appeal to a wide range of audiences.
+
Grounding most/all examples and illustrative assignments on real data.
+
Using as many of the out-of-the-box and freely available data exploration tools to preclude any advanced or specialized knowledge.
+
Make the curriculum materials openly available and support extensive customizations for any instructors who wish to adopt components/modules to suit their needs.
+
+
+
Who is this for?
+
+
Anyone and everyone. Instructors, students, aspiring data scientists and anyone interested in advancing their data comprehension and analysis skills without needing to code. For instructors, the rest of this page details the curriculum organization and how to find key concepts/ideas to use.
+
+
Suggested prerequisites
+
+
We suggest only the following prerequisites for this curriculum:
+
+
+
High-school level mathematics (basic).
+
High-school level statistics (basic).
+
+
+
Why Data Commons?
+
+
Data Commons (datacommons.org) is an open and public-access platform to all sorts of publicly available data in the world. From demographic data to economic/financial data to health indicators to weather/climate, Data Commons aggregates and makes available data about millions of places and thousands of metrics, e.g.,population growth rate.Additionally, Data Commons also provides some out-of-the-box data analysis tools, e.g., timeline charts, maps, scatter plots and the ability to download the data.
+
+
For the purpose of the data literacy, the Data Commons platform becomes an important component of the curriculum because it helps satisfy several curriculum development objectives:
+
+
+
Real data Data Commons provides open and easy access to a plethora of publicly available real data.
+
Open access Data Commons is available to everyone at no cost and with no restrictions of use.
The course consists of a set of modules focusing on several key concepts, including data modeling, analysis, visualization and the (ab)use of data to tell (false) narratives. Each module lists its objectives and builds on a pedagogical narrative around the explanation of key concepts, e.g.,, the differences between correlations and causation. We extensively use the Data Commons platform to point to real world examples without needing to write a single line of code!
+The course consists of a set of modules focusing on several key concepts, including data modeling, analysis, visualization and the (ab)use of data to tell (false) narratives. Each module lists its objectives and builds on a pedagogical narrative around the explanation of key concepts, e.g., the differences between correlations and causation. We extensively use the Data Commons platform to point to real world examples without needing to write a single line of code!
+
What is not covered?
+
+
We note that the curriculum objectives, themes, content and areas of focus are neither exhaustive nor a one size fits all. For example, we do not focus on the ethics of data collection in this curriculum. While these issues are of utmost importance, we chose to focus on a more basic and hands-on approach with the available resources.
This module is meant to serve as the introductory class(es) in a data literacy course. It provides motivation for why data literacy matters, introduces key concepts such as measurements, variables, models, etc., and defines some basic descriptive statistics and data visualization techniques.
Introduces students to the idea of a data “set” as well as some basic terms and statistical measures (e.g., mean, standard deviation, etc.) while highlighting important caveats and takeaways when drawing conclusions from these measures.
Introduces students to the idea of related data sets and describes how to merge data sets into one large data collection. Real data sets are analyzed in depth to demonstrate the benefits of building a nuanced, complete picture of the world.
Introduces students to some common plots and graphs and discusses when to use each depending on the data and the context. It also defines and explores various distributions with analysis of their properties and examples from the real world.
Introduces students to the idea of correlation between two variables and describes how to observe, quantify, and label correlations, with a focus on linear correlations. Strategies for distinguishing real correlations from noise are provided and common pitfalls, such as correlation vs causation, are discussed in depth.
Data Commons can help develop exciting new course content for several pedagogical use cases. From foundational data science and machine learning courses to more specialized curricula focusing on specific use cases and skills development, e.g., data analytics and analytical tools for public policy, public health etc. All courses and training materials need data, preferably real world data. We take a hands-on approach and work through several examples and case studies to illustrate useful concepts with real data. Instructors and students are welcome to modify any/all components to suit their needs. We encourage you to try different/related datasets which are also available through the Data Commons data graph!
+
+
License
+
+
All material is provided publicly and free of charge, under a Creative Commons license (CC BY).
+
+
FERPA compliance
+
+
Data Commons collects no personal information (PII), records, or private information from users and can be used in compliance with FERPA. For specific questions about FERPA compliance, please contact your organization’s legal counsel for advice.
A general audience course focused on the basics of data comprehension, interpretation, and data-based decision making. No programming experience required!
Introductory data science and machine learning courses crave real world datasets to enhance student interest and enrich their learning experience. However, identifying, accessing and preparing real data can be a painstaking task. As a result, several foundational courses tend to rely on a similar subset of datasets. We hope to demonstrate that Data Commons can help increase the diversity of real world data used in such foundational courses taught across the world and enrich students’ (and instructors’) experience.
+
+
We make available an (increasing) sample of data science course assignments developed around illustrating key concepts at an introductory college level. In addition to revolving around core data science ideas, we use real world data provided by the Data Commons APIs with the aim of enhancing the pedagogical goals of each topic. Each assignment is implemented as a Python notebook. These notebooks are not teaching notes; they serve as self-contained templates for implementing, interpreting and/or analyzing a subset of core concepts. The entire assignment revolves around using some publicly available dataset, most often directly using the Data Commons APIs.
+
+
Each assignment notebook should ideally be adapted to suit the needs of your curriculum and serve the needs of a complete and coherent course. We intend for them to serve as examples (templates) for you to customize extensively. We encourage course instructors and teaching assistants to use different datasets (and variables) for each iteration of their course. Luckily, Data Commons makes this easy.
+
+
Why use this?
+
+
These materials were designed to:
+
+
+
+
Use real data. Via the Data Commons API, students engage with real world data from the get-go — no more stale, synthetic datasets.
+
+
+
Be interactive. Each concept is illustrated with examples that instructors and teaching assistants can tinker with minimal effort, allowing students to learn in a hands-on way.
+
+
+
Easy to adapt. The notebook format and Data Commons Python API makes everything modular and easy to edit.
+
+
+
+
Who is this for?
+
+
Teachers, professors, instructors, teaching assistants, and anyone else developing and teaching data science curriculum. We also believe early practitioners can benefit greatly from the exercises.
+
+
As an example, MIT’s large Introduction to Machine Learning course has adapted several of the examples covered in these notebooks to suit their pedagogical needs. From using the same datasets to dive deeper into the material, to modifying the data/variables to illustrate a similar effect, the adaptations span a wide spectrum.
+
+
How can these be used?
+
+
We strongly encourage you to change and adapt these notebooks to fit your needs! You can download any notebook in either .ipynb or .py format by clicking on its link and File > Download.
+
+
Datasets can be changed by editing the list of variables queried (see the Data Commons for Data Science tutorial for more on this); editing framing and questions is as easy as editing text cells.
+
+
Some ideas:
+
+
Add additional cells for any additional topics you want covered.
+
For students with stronger programming skills, ask to implement the methods covered on their own.
+
Some of the questions posed to students in the notebooks are open ended – these can be adapted to discussion sessions with students.
+
+
+
Python notebooks
+
+
+
+
Data Commons for Data Science Tutorial
+A quick tutorial introducing the key concepts of working with the Data Commons Python API. Great for familiarizing yourself with how to adapt datasets to your particular needs.
+
+
+
Feature Engineering
+Explores the first steps of any data science pipeline: feature selection, data visualization, preprocessing and standardization. Pairs well with “Classification and Model Evaluation”.
+
+
+
Classification and Model Evaluation
+Explores the second half of a data science pipeline: training and test splits, cross validation, metrics for model evaluation. Focus is on classification models. Pairs well with “Feature Engineering”.
+
+
+
Regression: Basics and Prediction
+An introduction to linear regression as a tool for prediction, from a modern machine learning perspective.
+
+
+
Regression: Evaluation and Interpretation
+A more in-depth look at linear regression, with an emphasis on interpreting model parameters and evaluation metrics beyond simple accuracy. Provides a more statistical perspective.
+
+
+
Clustering
+An introduction to clustering analysis for unsupervised learning. Explores the mechanics of K-means clustering and cluster interpretation.
While you are just testing out data changes, you don’t need to build the website, but can just use a prebuilt Data Commons image.
+
+
Data Commons provides two prebuilt images in the Google Artifact Registry that you can download to run in a Docker container:
+
+
+
gcr.io/datcom-ci/datacommons-data:stable and gcr.io/datcom-ci/datacommons-services:stable. These are tested, stable versions but may be several weeks old.
+
gcr.io/datcom-ci/datacommons-data:latest and gcr.io/datcom-ci/datacommons-services:latest. These are the latest versions built from head.
+
+
+
If you want to pick up the latest prebuilt version, do the following:
+
+
+
From the root directory (e.g. website), run the following command:
+
You will need to build a local image in any of the following cases:
+
+
You are making substantive changes to the website UI
+
You are ready to deploy your custom site to GCP
+
+
+
Building from the master branch includes the very latest changes in Github, that may not have been tested. Instead, we recommend that you use the tested “stable” branch equivalent of the stable Docker image. This branch is customdc_stable, and is available at https://github.com/datacommonsorg/website/tree/customdc_stable.
+
+
+
Note: If you are working on a large-scale customization, we recommend that you use a version control system to manage your code. We provide some procedures for Github.
+
+
+
Clone the stable branch only
+
+
Use this procedure if you are not using Github, or if you are using Github and want to create a new source directory and start from scratch.
Start the services using the locally built repo. If you have made changes to any of the UI components (or directories), be sure to map the custom directories (or alternative directories) to the Docker workspace directory.
Custom Data Commons requires that you provide your data in a specific schema, format, and file structure. We strongly recommend that, before proceeding, you familiarize yourself with the basics of the Data Commons data model by reading through Key concepts, in particular, entities, statistical variables, and observations.
+
+
At a high level, you need to provide the following:
+
+
+
All data must be in CSV format, using the schema described below.
+
You must also provide a JSON configuration file, named config.json, that specifies how to map and resolve the CSV contents to the Data Commons schema knowledge graph. The contents of the JSON file are described below.
+
Depending on how you define your statistical variables (metrics), you may need to provide MCF (Meta Content Framework) files.
+
+
+
Files and directory structure
+
+
You can have as many CSV and MCF files as you like, and they can be in multiple subdirectories. There must only be one JSON config file, in the top-level input directory. For example:
The following sections walk you through the process of setting up your data.
+
+
Step 1: Identify your statistical variables
+
+
Your data undoubtedly contains metrics and observed values. In Data Commons, the metrics themselves are known as statistical variables, and the time series data, or values over time, are known as observations. While observations are always numeric, statistical variables must be defined as nodes in the Data Commons knowledge graph.
+
+
Statistical variables must follow a certain model: it includes a measure (e.g. “median age”) on a set of things of a certain type (e.g. “persons”) that satisfy some set of constraints (e.g. “gender is female”). To explain what this means, consider the following example. Let’s say your dataset contains the number of schools in U.S. cities, broken down by level (elementary, middle, secondary) and type (private, public), reported for each year (numbers are not real, but are just made up for the sake of example):
+
+
+
+
+
CITY
+
YEAR
+
SCHOOL_TYPE
+
SCHOOL_LEVEL
+
COUNT
+
+
+
+
+
San Francisco
+
2023
+
public
+
elementary
+
300
+
+
+
San Francisco
+
2023
+
public
+
middle
+
300
+
+
+
San Francisco
+
2023
+
public
+
secondary
+
200
+
+
+
San Francisco
+
2023
+
private
+
elementary
+
100
+
+
+
San Francisco
+
2023
+
private
+
middle
+
100
+
+
+
San Francisco
+
2023
+
private
+
secondary
+
50
+
+
+
San Jose
+
2023
+
public
+
elementary
+
400
+
+
+
San Jose
+
2023
+
public
+
middle
+
400
+
+
+
San Jose
+
2023
+
public
+
secondary
+
300
+
+
+
San Jose
+
2023
+
private
+
elementary
+
200
+
+
+
San Jose
+
2023
+
private
+
middle
+
200
+
+
+
San Jose
+
2023
+
private
+
secondary
+
100
+
+
+
+
+
The measure here is a simple count; the set of things is “schools”; and the constraints are the type and levels of the schools, namely “public”, “private”, “elementary”, “middle” and “secondary”. All of these things must be encoded as separate variables. Therefore, although the properties of school type and school level may already be defined in the Data Commons knowledge graph (or you may need to define them), they cannot be present as columns in the CSV files that you store in Data Commons. Instead, you must create separate “count” variables to represent each case. In our example, you would actually need 6 different variables:
+
+
Count_School_Public_Elementary
+
Count_School_Public_Middle
+
Count_School_Public_Secondary
+
Count_School_Private_Elementary
+
Count_School_Private_Middle
+
Count_School_Private_Secondary
+
+
+
If you wanted totals or subtotals of combinations, you would need to create additional variables for these as well.
+
+
Step 2: Choose between “implicit” and “explicit” schema definition
+
+
Custom Data Commons supports two ways of importing your data:
+
+
Implicit schema definition. This method is simplest, and does not require that you write MCF files, but it is more constraining on the structure of your data. You don’t need to provide variables and entities in DCID format, but you must follow a strict column ordering, and variables must be in variable-per-column format, described below. Naming conventions are loose, and the Data Commons importer will generate DCIDs for your variables and observations, based on a predictable column order. This method is simpler and recommended for most datasets.
+
Explicit schema definition. This method is a bit more involved, as you must explicitly define DCIDs for all your variables as nodes in MCF files. All variables and entities in the CSVs must reference DCIDs. Using this method allows you to specify variables in variable-per-row format, which is a bit more flexible. There are a number of cases for which this option might be a better choice:
+
+
You have hundreds of variables, which may be unmanageable as separate columns or files.
+
You want to be able to specify additional properties, for example, unit of measurement, of the observations at a more granular level than per-file. As an example, let’s say you have a variable that measures financial expenses, across multiple countries; you may want to be able to specify the country-specific currency of each observation.
+
In the case that you are missing observations for specific entities (e.g. places) or time periods for specific variables, and you don’t want to have lots of null values in columns (sparse tables).
+
+
+
+
+
To illustrate the difference between variable-per-column and variable-per-row schemas, let’s use the schools example data again. In variable-per-column, you would represent the dataset as follows:
+
+
Variable-per-column schema
+
+
+
+
+
CITY
+
YEAR
+
COUNT_SCHOOL_PUBLIC_ELEMENTARY
+
COUNT_SCHOOL_PUBLIC_MIDDLE
+
COUNT_SCHOOL_PUBLIC_SECONDARY
+
COUNT_SCHOOL_PRIVATE_ELEMENTARY
+
COUNT_SCHOOL_PRIVATE_MIDDLE
+
COUNT_SCHOOL_PRIVATE_SECONDARY
+
+
+
+
+
San Francisco
+
2023
+
300
+
300
+
200
+
100
+
100
+
50
+
+
+
San Jose
+
2023
+
400
+
400
+
300
+
200
+
200
+
100
+
+
+
+
+
The names that appear in the columns and rows don’t need to be DCIDs or follow any convention, because the columns must always be specified in this exact sequence:
In variable-per-row, the same dataset would be provided as follows:
+
+
Variable-per-row schema
+
+
+
+
+
CITY
+
YEAR
+
VARIABLE
+
OBSERVATION
+
+
+
+
+
geoId/0667000
+
2023
+
Count_School_Public_Elementary
+
300
+
+
+
geoId/0667000
+
2023
+
Count_School_Public_Middle
+
300
+
+
+
geoId/0667000
+
2023
+
Count_School_Public_Secondary
+
200
+
+
+
geoId/0667000
+
2023
+
Count_School_Private_Elementary
+
100
+
+
+
geoId/0667000
+
2023
+
Count_School_Private_Middle
+
100
+
+
+
geoId/0667000
+
2023
+
Count_School_Private_Secondary
+
50
+
+
+
geoId/06085
+
2023
+
Count_School_Public_Elementary
+
400
+
+
+
geoId/06085
+
2023
+
Count_School_Public_Middle
+
400
+
+
+
geoId/06085
+
2023
+
Count_School_Public_Secondary
+
300
+
+
+
geoId/06085
+
2023
+
Count_School_Private_Elementary
+
200
+
+
+
geoId/06085
+
2023
+
Count_School_Private_Middle
+
200
+
+
+
geoId/06085
+
2023
+
Count_School_Private_Secondary
+
100
+
+
+
+
+
The names and order of the columns aren’t important, as you can map them to the expected columns in the JSON file. However, the city and variable names must be existing DCIDs. If such DCIDs don’t already exist in the base Data Commons, you must provide definitions of them in MCF files.
The ENTITY is an existing entity, most commonly a place. The best way to think of the entity is as a key that could be used to join to other data sets. The column heading can be expressed as any existing place-related property; see Place types for a full list. It may also be any of the special DCID prefixes listed in Special place names.
+
+
+
Note: The type of the entities in a single file should be unique; do not mix multiple entity types in the same CSV file. For example, if you have observations for cities and counties, put all the city data in one CSV file and all the county data in another one.
+
+
+
The DATE is the date of the observation and should be in the format YYYY, YYYY-MM, or YYYY-MM-DD. The heading can be anything, although as a best practice, we recommend using a corresponding identifier, such as year, month or date.
+
+
The VARIABLE should contain a metric observation at a particular time. It could be an existing variable in the knowledge graph, to which you will add a different provenance, or it can be a new one. The heading can be anything, but you should encode the relevant attributes being measured, so that the importer can correctly create a new variable for you.
+
+
The variable values must be numeric. Zeros and null values are accepted: zeros will be recorded and null values ignored. Here is an example of some real-world data from the WHO on the prevalance of smoking in adult populations, broken down by sex, in the correct CSV format:
+
+
country,year,Adult_curr_cig_smokers,Adult_curr_cig_smokers_female,Adult_curr_cig_smokers_male
+Afghanistan,2019,7.5,1.2,13.4
+Angola,2016,,1.8,14.3
+Albania,2018,,4.5,35.7
+United Arab Emirates,2018,6.3,1.6,11.1
+
+
Note that the data is missing values for the total population percentage for Angola and Albania.
+
+
You can have as many CSV files as you like, and they can be stored in a single directory, or one directory and multiple subdirectories.
+
+
Special place names
+
+
In addition to the place names listed in Place types, you can also use the following special names as headings:
+
+
+
dcid — An already resolved DCID. Examples:country/USA, geoId/06
+
country3AlphaCode — Three-character country codes. Examples: USA, CHN
+
geoId — Place geo IDs. Examples: 06, 023
+
lat#lng — Latitude and longitude of the place using the format lat#long. Example: 38.7#-119.4
+
wikidataId — Wikidata place identifiers. Example: Q12345
+
+
+
You can also simply use the heading name or place and the importer will resolve it automatically.
You must define a config.json in the top-level directory where your CSV files are located. With the implicit schema method, you need to provide 3 specifications:
+
+
The input files location and entity type
+
The sources and provenances of the data
+
Optionally, additional properties of the statistical variables you’ve used in the CSV files
+
+
+
Here is an example of how the config file would look for WHO CSV file we defined earlier. More details are below.
+
+
{
+ "inputFiles":{
+ "adult_cig_smoking.csv":{
+ "entityType":"Country",
+ "provenance":"UN_WHO",
+ "observationProperties":{
+ "unit":"percentage"
+ }
+ }
+ },
+ "variables":{
+ "Adult_curr_cig_smokers":{
+ "name":"Adult Current Cigarette Smokers",
+ "description":"Percentage of smokers in the total adult population",
+ "searchDescriptions":[
+ "Prevalence of smoking among adults in world countries in the years 2016 - 2019."
+ ],
+ "group":"WHO"
+ },
+ "Adult_curr_cig_smokers_female":{
+ "name":"Adult Current Cigarette Smokers Female",
+ "description":"Percentage of smokers in the female adult population",
+ "searchDescriptions":[
+ "Prevalence of smoking among adult women in world countries in the years 2016 - 2019."
+ ],
+ "group":"WHO"
+ },
+ "Adult_curr_cig_smokers_male":{
+ "name":"Adult Current Cigarette Smokers Male",
+ "description":"Percentage of smokers in the male adult population",
+ "searchDescriptions":[
+ "Prevalence of smoking among adult men in world countries in the years 2016 - 2019."
+ ],
+ "group":"WHO"
+ }
+ },
+ "sources":{
+ "custom.who.int":{
+ "url":"https://custom.who.int",
+ "provenances":{
+ "UN_WHO":"https://custom.who.int/data/gho/indicator-metadata-registry/imr-details/6128"
+ }
+ }
+ }
+}
+
+
The following fields are specific to the variable-per-column format:
+
+
+
input_files:
+
+
entityType: This must be an existing entity class in the Data Commons knowledge graph; it’s most commonly a place type.
+
+
+
variables: This section is optional but recommended. You can use it to override names and associate additional properties with the statistical variables in the files, using the parameters described below. All parameters are optional.
+
+
name: A human-friendly readable name that will be shown throughout the UI.
+
description: A more detailed name that will be shown in the Statistical Variable Explorer.
+
searchDescriptions: This is a comma-separated list of natural-language text descriptions of the variable; these descriptions will be used to generate embeddings for the NL query interface.
+
group: This will display the variables as a group in the Statistical Variable Explorer, using the name you provide as heading.
In this section, we will walk you through a concrete example of how to go about setting up your CSV, MCF and JSON files.
+
+
Write the MCF file
+
+
Nodes in the Data Commons knowledge graph are defined in Metadata Content Format (MCF). For custom Data Commons using explicit schema, you must define your statistical variables using MCF. The MCF file should have a .mcf suffix and be placed in the same top-level directory as the config.json file.
+
+
Here’s an example of defining the same statistical variables in the WHO data in MCF:
+
+
Node: dcid:Adult_curr_cig_smokers
+typeOf: dcid:StatisticalVariable
+name: "Prevalence of current cigarette smoking among adults (%)"
+populationType: dcid:Person
+measuredProperty: dcid:percent
+
+Node: dcid:Adult_curr_cig_smokers_female
+typeOf: dcid:StatisticalVariable
+name: "Prevalence of current cigarette smoking among adults (%) [Female]"
+populationType: dcid:Person
+measuredProperty: dcid:percent
+gender: dcid:Female
+
+Node: dcid:Adult_curr_cig_smokers_male
+typeOf: dcid:StatisticalVariable
+name: "Prevalence of current cigarette smoking among adults (%) [Male]"
+populationType: dcid:Person
+measuredProperty: dcid:percent
+gender: dcid:Male
+
+
+
The order of nodes and fields within nodes does not matter.
+
+
The following fields are always required:
+
+
Node: This is the DCID of the entity you are defining.
+
typeOf: In the case of statistical variable, this is always dcid:StatisticalVariable.
+
name: This is the descriptive name of the variable, that is displayed in the Statistical Variable Explorer and various other places in the UI.
+
populationType: This is the type of thing being measured, and its value must be an existing Class type. It is mainly used to classify variables into categories that appear in the Statistical Variable Explorer. In this example it is dcid:Person. For a full list of supported classes, you will have to send an API request, as described in Get a list of all existing statistical variables.
+
measuredProperty: This is a property of the thing being measured. It must be a domainIncludes property of the populationType you have specified. In this example, it is the percent of persons being measured. You can see the set of domainIncludes properties for a given populationType, using either of the following methods:
+
+
+
Go to https://datacommons.org/browser/POPULATION_TYPE, e.g. https://datacommons.org/browser/Person and scroll to the domainIncludes section of the page. For example:
Note that all non-quoted field values must be prefixed with dcid: or dcs:, which are interchangeable. You may wish to add an optional namespace, separated by a slash (/); for example, who/Adult_curr_cig_smokers.
+
+
The following fields are optional:
+
+
statType: By default this is dcid:measuredValue, which is simply a raw value of an observation. If your variable is a calculated value, such as an average, a minimum or maximum, you can use minValue, maxValue, meanValue, medianValue, sumvalue, varianceValue, marginOfError, stdErr. In this case, your data set should only include the observations that correspond to those calculated values.
+
measurementQualifier: This is similar to the observationPeriod field for CSV observations (see below) but applies to all observations of the variable. It can be any string representing additional properties of the variable, e.g. Weekly, Monthly, Annual. For instance, if the measuredProperty is income, you can use Annual or Monthly to distinguish income over different periods. If the time interval affects the meaning of variable and and values change significantly by the time period, you should use this field keep them separate.
+
measurementDenominator: For percentages or ratios, this refers to another statistical variable. For example, for per-capita, the measurementDenominator is Count_Person.
+
+
+
Additionally, you can specify any number of property-value pairs representing the constraints on the type identified by populationType. In our example, there is one constraint property, gender, which is a property of Person. The constraint property values are typically enumerations; such as genderType, which is a rangeIncludes property of gender. These will become additional sub-categories of the population type and displayed as such in the Statistical Variable Explorer. Using our example:
+
+
+
+
Prepare the CSV data files
+
+
CSV files using explicit schema contain the following columns using the following headings:
The columns can be in any order, and you can specify custom names for the headings and use the columnMappings field in the JSON file to map them accordingly (see below for details).
+
+
These columns are required:
+
+
entity: The DCID of an existing entity in the Data Commons knowledge graph, typically a place.
+
variable: The DCID of the node you have defined in the MCF.
+
date: The date of the observation and should be in the format YYYY, YYYY-MM, or YYYY-MM-DD.
+
value: The value of the observation and must be numeric. The variable values must be numeric. Zeros and null values are accepted: zeros will be recorded and null values ignored.
+
+
+
+
Note: The type of the entities in a single file should be unique; do not mix multiple entity types in the same CSV file. For example, if you have observations for cities and counties, put all the city data in one CSV file and all the county data in another one.
+
+
+
The remaining columns are optional, and allow you to specify additional per-observation properties; see the descriptions of these in the JSON config file reference.
+
+
Here is an example of some real-world data from the WHO on the prevalance of smoking in adult populations, broken down by sex, in the correct CSV format:
In this case, the columns need to be mapped to the expected columns listed above; see below for details.
+
+
Write the JSON config file
+
+
You must define a config.json in the top-level directory where your CSV files are located. With the explicit schema method, you need to provide these specifications:
+
+
The input files location and entity type
+
The sources and provenances of the data
+
Column mappings, if you are using custom names for the column headings
+
+
+
Here is an example of how the config file would look for the CSV file we defined above. More details are below.
The following fields are specific to the variable-per-row format:
+
+
input_files:
+
+
format must be variablePerRow (the default is variablePerColumn if not specified)
+
columnMappings are required if you have used custom column heading names. The format is DEFAULT_NAME : CUSTOM_NAME.
+
+
+
groupStatVarsByProperty is optional, and allows you to group your variables together according to population type. They will be displayed together in the Statistical Variable Explorer.
Each section contains some required and optional fields, which are described in detail below.
+
+
Input files
+
+
The top-level inputFiles field should encode a map from the CSV input file name to parameters specific to that file. Keys can be individual file names or wildcard patterns if the same configuration applies to multiple files.
+
+
You can use the * wildcard; matches are applied in the order in which they are specified in the config. For example, in the following:
The first set of parameters only applies to foo.csv. The second set of parameters applies to bar.csv, bar1.csv, bar2.csv, etc. The third set of parameters applies to all CSVs except the previously specified ones, namely foo.csv and bar*.csv.
+
+
If you are using subdirectories, specify the file names using paths relative to the top-level directory (which you specify in the env.list file as the input directory), and be sure to set "includeInputSubdirs": true (the default is false if the option is not specified.) For example:
Note: Although you don’t need to specify the names of MCF files in the inputFiles block, if you want to store them in subdirectories, you still need to set "includeInputSubdirs": true here.
+
+
+
Input file parameters
+
+
+
entityType (implicit schema only)
+
+
Required: All entities in a given file must be of a specific type. This type should be specified as the value of the entityType field. The importer tries to resolve entities to DCIDs of that type. In most cases, the entityType will be a supported place type; see Place types for a list.
+
+
ignoreColumns
+
+
Optional: The list of column names to be ignored by the importer, if any.
+
+
provenance
+
+
Required: The provenance (name) of this input file. Provenances typically map to a dataset from a source. For example, WorldDevelopmentIndicators provenance (or dataset) is from the WorldBank source.
+
+
+
+
You must specify the provenance details under sources.provenances; this field associates one of the provenances defined there to this file.
+
+
+
observationProperties (implicit schema only)
+
+
Optional: Additional information about each contained in the CSV file. Currently, the following properties are supported:
+
+
unit: The unit of measurement used in the observations. This is a string representing a currency, area, weight, volume, etc. For example, SquareFoot, USD, Barrel, etc.
+
measurementPeriod: The period of time in which the observations were recorded. This must be in ISO duration format, namely P[0-9][Y|M|D|h|m|s]. For example, P1Y is 1 year, P3M is 3 months, P3h is 3 hours.
+
measurementMethod: The method used to gather the observations. This can be a random string or an existing DCID of MeasurementMethodEnum type; for example, EDA_Estimate or WorldBankEstimate.
+
scalingFactor: An integer representing the denominator used in measurements involving ratios or percentages. For example, for percentages, the denominator would be 100.
+
+
+
+
+
Note that you cannot mix different property values in a single CSV file. If you have observations using different properties, you must put them in separate CSV files.
+
+
+
format
+
+
Only needed to specify variablePerRow for explicit schemas. The assumed default is variablePerColumn.
+
+
columnMappings (explicit schema only)
+
+
Optional: If headings in the CSV file does not use the default names, the equivalent names for each column.
+
+
+
+
Variables (implicit schema only)
+
+
The variables section is optional. You can use it to override names and associate additional properties with the statistical variables in the files, using the parameters described below. All parameters are optional. If you don’t provide this section, the importer will automatically derive the variable names from the CSV file.
+
+
Variable parameters
+
+
+
name
+
+
The display name of the variable, which will show up throughout the UI. If not specified, the column name is used as the display name.
+The name should be concise and precise; that is, the shortest possible name that allow humans to uniquely identify a given variable. The name is used to generate NL embeddings.
+
+
description
+
+
A long-form description of the variable.
+
+
properties
+
+
Additional Data Commons properties associated with this variable. This section is analogous to the fields specified in an MCF Node definition.
+
+
+
+
Each property is specified as a key:value pair. Here are some examples:
By default, the Statistical Variables Explorer will display all custom variables as a group called “Custom Variables”. You can use this option to create multi-level hierarchies, and assign different variables to groups. The value of the group option is used as the heading of the group. For example, in the sample data, the group name OECD is used to group together the two variables from the two CSV files:
+
+
+
+
+
+
You can have a multi-level group hierarchy by using / as a separator between each group.
+
+
+
searchDescriptions
+
+
An array of descriptions to be used for creating more NL embeddings for the variable. This is only needed if the variable name is not sufficient for generating embeddings.
+
+
+
+
groupStatVarsByProperty (explicit schema only)
+
+
Optional: Causes the Statistical Variable Explorer to create a top-level category called “Custom Variables”, and groups together variables with the same population types and measured properties. For example:
+
+
+
+
If you would like your custom variables to be displayed together, rather than spread among existing categories, this option is recommended.
+
+
Sources
+
+
The sources section encodes the sources and provenances associated with the input dataset. Each named source is a mapping of provenances to URLs.
+
+
Source parameters
+
+
+
url
+
Required: The URL of the named source. For example, for named source U.S. Social Security Administration, it would be https://www.ssa.gov.
+
provenances
+
Required: A set of NAME:URL pairs. Here are some examples:
+
+
+
{
+ "USA Top Baby Names 2022":"https://www.ssa.gov/oact/babynames/",
+ "USA Top Baby Names 1923-2022":"https://www.ssa.gov/oact/babynames/decades/century.html"
+}
+
+
+
Load local custom data
+
+
The following procedures show you how to load and serve your custom data locally.
Edit the env.list file you created previously as follows:
+
+
Set the INPUT_DIR variable to the full path to the directory where your input files are stored.
+
Set the OUTPUT_DIR variable to the full path to the directory where you would like the output files to be stored. This can be the same or different from the input directory. When you rerun the Docker data management container, it will create a datacommons subdirectory under this directory.
+
+
+
Start the Docker containers with local custom data
+
+
Once you have configured everything, use the following commands to run the data management container and restart the services container, mapping your input and output directories to the same paths in Docker.
+
+
Step 1: Start the data management container
+
+
In one terminal window, from the root directory, run the following command to start the data management container:
(Optional) Start the data management container in schema update mode
+
+
If you have tried to start a container, and have received a SQL check failed error, this indicates that a database schema update is needed. You need to restart the data management container, and you can specify an additional, optional, flag, DATA_RUN_MODE=schemaupdate. This mode updates the database schema without re-importing data or re-building natural language embeddings. This is the quickest way to resolve a SQL check failed error during services container startup.
+
+
To do so, add the following line to the above command:
+
+
docker run \
+...
+-e DATA_RUN_MODE=schemaupdate \
+...
+gcr.io/datcom-ci/datacommons-data:stable
+
+
+
Once the job has run, go to step 2 below.
+
+
Step 2: Start the services container
+
+
In another terminal window, from the root directory, run the following command to start the services container:
Any time you make changes to the CSV or JSON files and want to reload the data, you will need to rerun the data management container, and then restart the services container.
+
+
Inspect the SQLite database
+
+
If you need to troubleshoot custom data, it is helpful to inspect the contents of the generated SQLite database.
+
+
To do so, from a terminal window, open the database:
The default custom Data Commons image provides a bare-bones UI that you will undoubtedly want to customize to your liking. Data Commons uses the Python Flask web framework and Jinja HTML templates. If you’re not familiar with these, the following documents are good starting points:
Note that the custom parent directory is customizable as the FLASK_ENV environment variable. You can rename the directory as desired and update the environment variable in custom_dc/env.list.
+
+
To enable the changes to be picked up by the Docker image, and allow you to refresh the browser for further changes, restart the Docker image with this additional flag to map the directories to the Docker workspace:
If you have renamed the parent custom directory, be sure to use that name in the flag.
+
+
Customize HTML templates
+
+
You can customize the page header and footer (by default, empty) in base.html by adding or changing the HTML elements within the <header></header> and <footer></footer> tags, respectively.
+
+
+
+
Customize Javascript and styles
+
+
Use the overrides.css file to customize the default Data Commons styles. The file provides a default color override. You can add all style overrides to that file.
+
+
Alternatively, if you have existing existing CSS and Javascript files, put them under the /static/custom_dc/custom folder. Then include these files in the <head> section of the corresponding HTML files as:
Note: Currently, making changes to any of the files in the static/ directory, even if you’re testing locally, requires that you rebuild a local version of the repo to pick up the changes, as described in Build a local image. We plan to fix this in the near future.
This page shows you how to store your custom data in Google Cloud, and create the data management container as a Google Cloud Run job. This is step 4 of the recommended workflow.
Once you have tested locally, the next step is to get your data into the Google Cloud Platform. You upload your CSV and JSON files to Google Cloud Storage, and run the Data Commons data management Docker container as a Cloud Run job. The job will transform and store the data in a Google Cloud SQL database, and generate NL embeddings stored in Cloud Storage.
+
+
+
+
Alternatively, if you have a very large data set, you may find it faster to store your input files and run the data management container locally, and output the data to Google Cloud Storage. If you would like to use this approach, follow steps 1 to 3 of the one-time setup steps below and then skip to Run the data management container locally.
While you are testing, you can start with a single Google Cloud region; to be close to the base Data Commons data, you can use us-central1. However, once you launch, you may want to host your data and application closer to where your users will be. In any case, you should use the same region for your Google Cloud SQL instance, the Google Cloud Storage buckets, and the Google Cloud Run service where you will host the site. For a list of supported regions, see Cloud SQL Manage instance locations.
+
+
Step 2: Create a Google Cloud Storage bucket
+
+
This stores the CSV and JSON files that you will upload whenever your data changes. It also stores generated files files in a datacommons subdirectory when you run the data management job.
For the Location type, choose the same regional options as for Cloud SQL above.
+
When you have finished setting all the configuration options, click Create.
+
In the Bucket Details page, click Create Folder to create a new folder to hold your data and name it as desired.
+
+
Optionally, create separate folders to hold input and output files, or just use the same one as for the input.
+
+
Note: If you plan to run the data management container locally, you only need to create a single folder to hold the output files.
+
+
Record the folder path(s) as gs://BUCKET_NAME/FOLDER_PATH for setting the INPUT_DIR and OUTPUT_DIR environment variables below.
+
+
+
Step 3: Create a Google Cloud SQL instance
+
+
This stores the data that will be served at run time. The Data Commons data management job will create the SQL tables and populate them when you start the job.
Set an instance ID. Record the instance connection name in the form of INSTANCE_ID for setting environment variables below.
+
Set a root password, and record it for setting environment variables below.
+
For the Location type, choose the relevant regional option.
+
When you have finished setting all the configuration options, click Create Instance. It may take several minutes for the instance to be created.
+
When the instance is created and the left navigation bar appears, select Users.
+
Add at least one user and password.
+
Select Databases.
+
Click Create Database.
+
Choose a name for the database or use the default, datacommons.
+
Click Create.
+
In the Overview page for the new instance, record the Connection name to set in environment variables in the next step.
+
+
+
Step 4 (optional but recommended): Add secrets to the Google Cloud Secret Manager
+
+
Although this is not strictly required, we recommend that you store secrets, including your API keys and DB passwords, in Google Cloud Secret Manager, where they are encrypted in transit and at rest, rather than stored and transmitted in plain text. See also the Secret Manager documentation for additional options available.
In the Container image URL field, enter gcr.io/datcom-ci/datacommons-data:stable.
+
Optionally, in the Job name field, enter an alternative name as desired.
+
In the Region field, select the region you chose as your location.
+
Leave the default Number of tasks as 1.
+
Expand Container, Volumes, Connections, Security and expand Settings, and set the following options:
+
+
Resources > Memory: 8 GiB
+
Resources > CPU: 2
+
+
+
+
+
+
+
Now set environment variables:
+
+
+
Click the Variables and Secrets tab.
+
Click Add variable.
+
Add names and values for the following environment variables:
+
+
USE_CLOUDSQL: Set to true.
+
INPUT_DIR: Set to the Cloud Storage bucket and input folder that you created in step 2 above.
+
OUTPUT_DIR: Set to the Cloud Storage bucket (and, optionally, output folder) that you created in step 2 above. If you didn’t create a separate folder for output, specify the same folder as the INPUT_DIR.
+
CLOUDSQL_INSTANCE: Set to the full connection name of the instance you created in step 3 above.
+
DB_USER: Set to a user you configured when you created the instance in step 3, or to root if you didn’t create a new user.
+
DB_NAME: Only set this if you configured the database name to something other than datacommons.
+
+
+
If you are not storing API keys and passwords in Google Secret Manager, add variables for DC_API_KEY and DB_PASS. Otherwise, click Reference a secret, in the Name field, enter DC_API_KEY, and from the Secret drop-down field, select the relevant secret you created in step 4. Repeat for DB_PASS.
+
+
When you are finished, click Done.
+
+
+
+
If you have a large amount of data, adjust the Task capacity > Task timeout option accordingly. See Set task timeout (jobs) for more details.
+
Click Create (but don’t run it immediately).
+
+
+
Manage your data
+
+
Step 1: Upload data files to Google Cloud Storage
+
+
As you are iterating on changes to the source CSV and JSON files, you can re-upload them at any time, either overwriting existing files or creating new folders. If you want versioned snapshots, we recommend that you create a new subfolder and store the latest version of the files there. If you prefer to simply incrementally update, you can simply overwrite files in a pre-existing folder. Creating new subfolders is slower but safer. Overwriting files is faster but riskier.
Note: Do not upload the local datacommons subdirectory or its files.
+
+
+
Once you have uploaded the new data, you must rerun the data management Cloud Run job.
+
+
Step 2: Run the data management Cloud Run job
+
+
Now that everything is configured, and you have uploaded your data in Google Cloud Storage, you simply have to start the Cloud Run data management job to convert the CSV data into tables in the Cloud SQL database and generate the embeddings (in a datacommons/nl subfolder).
+
+
Every time you upload new input CSV or JSON files to Google Cloud Storage, you will need to rerun the job.
From the list of jobs, click the link of the "datacommons-data" job you created above.
+
Optionally, if you have received a SQL check failed error when previously trying to start the container, and would like to minimize startup time, click Execute with overrides and click Add variable to set a new variable with name DATA_RUN_MODE and value schemaupdate.
+
Click Execute. It will take several minutes for the job to run. You can click the Logs tab to view the progress.
+
+
+
+
+
From any local directory, run the following command:
+
gcloud run jobs execute JOB_NAME
+
+
To view the progress of the job, run the following command:
+
(Optional) Run the data management Cloud Run job in schema update mode
+
+
If you have tried to start a container, and have received a SQL check failed error, this indicates that a database schema update is needed. You need to restart the data management container, and you can specify an additional, optional, flag, DATA_RUN_MODE=schemaupdate. This mode updates the database schema without re-importing data or re-building natural language embeddings. This is the quickest way to resolve a SQL check failed error during services container startup.
In the Sign in to SQL Studio page, from the Database field, select the database you created earlier, e.g. datacommons.
+
Enter the user name and password and click Authenticate.
+
In the left Explorer pane that appears, expand the Databases icon, your database name, and Tables. The table of interest is observations. You can see column names and other metadata.
+
To view the actual data, in the main window, click New SQL Editor tab. This opens an environment in which you can enter and run SQL queries.
+
+
Enter a query and click Run. For example, for the sample OECD data, if you do select * from observations limit 10;, you should see output like this:
+
+
+
+
+
+
Advanced setup (optional): Run the data management container locally
+
+
This process is similar to running both data management and services containers locally, with a few exceptions:
+
+
Your input directory will be the local file system, while the output directory will be a Google Cloud Storage bucket and folder.
+
You must start the job with credentials to be passed to Google Cloud, to access the Cloud SQL instance.
+
+
+
Before you proceed, ensure you have completed steps 1 to 3 of the One-time setup steps above.
+
+
Step 1: Set environment variables
+
+
To run a local instance of the services container, you need to set all the environment variables in the custom_dc/env.list file. See above for the details, with the following differences:
+
+
For the INPUT_DIR, specify the full local path where your CSV and JSON files are stored, as described in the Quickstart.
+
Set GOOGLE_CLOUD_PROJECT to your GCP project name.
+
+
+
Step 2: Generate credentials for Google Cloud authentication
+
+
For the services to connect to the Cloud SQL instance, you need to generate credentials that can be used in the local Docker container for authentication. You should refresh the credentials every time you rerun the Docker container.
+
+
Open a terminal window and run the following command:
+
+
gcloud auth application-default login
+
+
+
This opens a browser window that prompts you to enter credentials, sign in to Google Auth Library and allow Google Auth Library to access your account. Accept the prompts. When it has completed, a credential JSON file is created in
+$HOME/.config/gcloud/application_default_credentials.json. Use this in the command below to authenticate from the docker container.
+
+
The first time you run it, may be prompted to specify a quota project for billing that will be used in the credentials file. If so, run this command:
To verify that the data is correctly created in your Cloud SQL database, use the procedure in Inspect the Cloud SQL database above.
+
+
(Optional) Run the data management Docker container in schema update mode
+
+
If you have tried to start a container, and have received a SQL check failed error, this indicates that a database schema update is needed. You need to restart the data management container, and you can specify an additional, optional, flag, DATA_RUN_MODE to miminize the startup time.
+
+
To do so, add the following line to the above command:
+
+
docker run \
+...
+-e DATA_RUN_MODE=schemaupdate \
+...
+gcr.io/datcom-ci/datacommons-data:stable
+
+
+
Advanced setup (optional): Access Cloud data from a local services container
+
+
For testing purposes, if you wish to run the services Docker container locally but access the data in Google Cloud, use the following procedures.
+
+
Step 1: Set environment variables
+
+
To run a local instance of the services container, you will need to set all the environment variables, as described above in the custom_dc/env.list. You must also set the MAPS_API_KEY to your Maps API key.
+
+
Step 2: Generate credentials for Google Cloud default application
This page shows you how to build a custom services Docker container as a GCP artifact, upload it to the Artifact Registry, and create a Google Cloud Run service. This is step 5 of the recommended workflow.
When you are ready to host your custom Data Commons site in production, you create a Google Cloud Run service for the site. This is the production setup:
+
+
+
+
You push a locally built Docker image to the Google Cloud Artifact Registry, and then deploy the image as a Cloud Run service.
+
+
One-time setup: Create a Google Artifact Registry repository
In Location type, select Region, and specify the region you chose for your Google Cloud SQL instance .
+
Enable or disable Immutable image tags according to the workflow you prefer; that is, if you want to be able to reuse the same Docker tag for new images, keep this option disabled.
+
Click Create.
+
+
+
Upload the Docker container to the Artifact Registry
+
+
This procedure creates a “dev” Docker package that you upload to the Google Cloud Artifact Registry. Any time you rebuild the image and want to deploy it to the cloud, you need to rerun this procedure.
+
+
+
Build a local version of the Docker image, following the procedure in Build a local image.
+
+
Authenticate to gcloud:
+
+
gcloud auth login
+
+
+
This opens a browser window that prompts you to enter credentials, sign in to Google Cloud SDK and allow Google Cloud SDK to access your account. Accept the prompts.
+
+
+
Generate credentials for the Docker package you will build in the next step. Docker package names must be in the format LOCATION-docker-pkg.dev, where the LOCATION is the region you have selected in the repository creation step previously; for example, us-central1.
Under Authentication, select the relevant option depending on whether your site will be public or not. If it is public, enable Allow unauthenticated invocations.
+
Set the following options:
+
+
CPU allocation and pricing: CPU is always allocated
+
Service autoscaling > Minimum number of instances: 1
+
+
+
+
+
Expand Container, Volumes, Connections, Security > Container > Settings, and set the following options:
+
+
Resources > Memory: 8 GiB
+
Resources > CPU: 2
+
+
+
+
+
Expand the Variables and secrets tab.
+
Click the Variables and Secrets tab.
+
Click Add variable.
+
Add the same environment variables and secrets, with the same names and values as you did when you created the data management run job You can omit the INPUT_DIR variable. Add a variable or reference a secret for MAPS_API_KEY.
+
+
When you are finished, click Done.
+
+
+
+
Under Execution environment > Autoscaling, set the following options:
+
+
Minimum number of instances: 1
+ - Maximum number of instances: 1
+
+
+
Disable Startup CPU boost.
+
+
Under Cloud SQL connections click Add connection and select your Cloud SQL instance from the menu.
+
+
+
+
+
+
Click Create to kick off the deployment. Click the Logs tab to see the status details of the operation. Once it completes, a link to the deployed image URL is listed at the top of the page. Click on the link to see the running instance.
+
+
Manage the service
+
+
Every time you make changes to the code and release a new Docker artifact, or rerun the data management job, you need to restart the service as well.
Should I contribute my data to the base Data Commons or should I run my own instance?
+
+
If you have determined that your data is a good fit for Data Commons, the main considerations for whether to host your data in the base Data Commons or in your own custom instance are as follows:
+
+
If you have any private data, or you want to restrict access to your data, you must use your own instance.
+
If you want to maintain governance and licensing over your data, you should use your own instance.
+
If you want to control the UI of the website hosting your data, use your own instance.
+
If you want the widest possible visibility of your data, including direct access through Google Search, add your data to base Data Commons.
+
+
+
For detailed comparison on the differences between base and custom Data Commons, see the Overview page.
+
+
How can I request new features or provide feedback?
+
+
We use Google Issue Tracker to track bugs and feature requests. All tickets are publicly viewable.
+
+
Before opening a new ticket, please see if an existing feature request or bug report covering your issue has already been filed. If yes, upvote (click the +1 button ) and subscribe to it. If not, open a new feature request or bug report.
+
+
For any issue you file, make sure to indicate that it affects your Data Commons instance.
+
+
Privacy and security
+
+
Can I restrict access to my custom instance?
+
+
Yes; there are many options for doing so. If you want an entirely private site with a non-public domain, you may consider using a Google Virtual Private Cloud to host your instance. If you want to have authentication and authorization controls on your site, there are also many other options. Please see Restricting ingress for Cloud Run for more information.
+
+
Note that you cannot apply fine-grained access restrictions, such as access to specific data or pages. Access is either all or nothing. If you want to be able to partition off data, you would need to create additional custom instances.
+
+
Will my data or queries end up in base Data Commons?
+
+
Your user queries, observations data, or property values are never transferred to base Data Commons. The NL model built from your custom data lives solely in your custom instance. The custom Data Commons instance does make API calls to the base Data Commons instance (as depicted in this diagram) only in the following instances:
+
+
At data load time, API calls are made from the custom instance to the base instance to resolve entity names to DCIDs; for example, if your data refers to a particular country name, the custom instance will send an API request to look up its DCID.
+
At run time, when a user enters an NL query, the custom instance uses its local NL model to identify the relevant statistical variables. The custom instance then issues two requests for statistical variable observations: a SQL query to your custom SQL database and an API call to the base Data Commons database. These requests only include DCIDs and contain no information about the original query or context of the user request. The data is joined by entity DCIDs.
+
At run time, when the website frontend renders a data visualization, it will also make the same two requests to get observations data.
+
+
+
Natural language processing
+
+
How does the natural language (NL) interface work?
+
+
The Data Commons NL interface has the ability to use a combination of different embedding models, heuristics and large-language models (LLMs) (as fallback). Given an NL query, it first detects schema information (variables, properties, etc.) and entities (e.g., places like “California”) in the query, and then responds with a set of charts chosen based on the query shape (ranking, etc.) and data existence constraints.
When you load data into a custom instance, the Data Commons NL server generates embeddings for both the base Data Commons data, and for your custom data, based on the statistical variables and search descriptions you have defined in your configuration. When a query comes in, the server generates equivalent embeddings, and the variables are assigned a relevance score based on cosine similarity.
+
+
Does the model use any Google technologies, such as Vertex AI?
+
+
No. While the base Data Commons uses Vertex AI, the custom instance uses open-source ML technologies only.
+
+
Where does the ML model run and where are embeddings stored?
+
+
The ML model runs entirely on your custom Data Commons instance, inside the Docker image. It does not use any Google-hosted systems, and data is never leaked to the base Data Commons. If a natural-language query requires data to be joined from the base data store, the custom site will use the embeddings that are locally generated before making the call to the base Data Commons to fetch the data.
+
+
Does the model use feedback from user behavior to adjust scoring?
+
+
No. However, you have the ability to improve query quality by improving your search descriptions.
+
+
How can I find out what terms my users are searching on?
A custom instance natively joins your data and the base Data Commons data (from datacommons.org) in a unified fashion. Your users can visualize and analyze the data seamlessly without the need for further data preparation.
+
+
You have full control over your own data and computing resources, with the ability to limit access to specific individuals or open it to the general public.
+
+
Note that each new Data Commons is deployed using the Google Cloud Platform (GCP).
+
+
Why use a custom Data Commons instance?
+
+
If you have the resources to develop and maintain a custom Data Commons instance, this is a good option for the following use cases:
+
+
+
You want to host your data on your own website, and take advantage of Data Commons natural-language query interface, and exploration and visualization tools.
+
You want to add your own data to Data Commons but want to maintain ownership of the Cloud data.
+
You want to add your own data to Data Commons but want to customize the UI of the site.
+
You want to add your own private data to Data Commons, and restrict access to it.
+
+
+
For the following use cases, a custom Data Commons instance is not necessary:
+
+
+
You want to share your data publicly on datacommons.org. In this case, please file a data request in our issue tracker to get started.
+
You want to make the base public data or visualizations available in your own site. For this purpose, you can call the Data Commons APIs from your site; see Data Commons web components for more details.
For example, Virtual Private Cloud, Cloud IAM, and so on. Please see the GCP Restricting ingress for Cloud Run for more information on these options.
+
You cannot set access controls on specific data, only the entire custom site.
+
+
+
System overview
+
+
Essentially, a custom Data Commons instance is a mirror of the public Data Commons, that runs in Docker containers hosted in the cloud. In the browsing tools, the custom data appears alongside the base data in the list of variables. When a query is sent to the custom website, a Data Commons server fetches both the custom and base data to provide multiple visualizations. At a high level, here is a conceptual view of a custom Data Commons instance:
+
+
+
+
A custom Data Commons instance uses custom data that you provide as raw CSV files. An importer script converts the CSV data into the Data Commons format and stores this in a SQL database. For local development, we provide a lightweight, open-source SQLite database; for production, we recommend that you use Google Cloud SQL.
+
+
+
Note: You have full control and ownership of your data, which will live in SQL data stores that you own and manage. Your data is never transferred to the base Data Commons data stores managed by Google; see full details in this FAQ.
+
+
+
In addition to the data, a custom Data Commons instance consists of two Docker containers:
+
+
A “data management” container, with utilities for managing and loading custom data and embeddings used for natural-language processing
+
A “services” container, with the core services that serve the data and website
+
+
+
Details about the components that make up the containers are provided in the Quickstart guide.
+
+
Requirements and cost
+
+
A custom Data Commons site runs in a Docker container on Google Cloud Platform (GCP), using Google Cloud Run, a serverless solution that provides auto-scaling and other benefits. You will need the following:
If you will be customizing the site’s UI, familiarity with the Python Flask web framework and Jinja HTML templating
+
+
+
+
Note: Data Commons does not support local Windows development natively. If you wish to develop Data Commons on Windows, you will need to use the Windows Subsystem for Linux.
+
+
+
If you already have an account with another cloud provider, we can provide a connector; please contact us if you are interested in this option.
+
+
In terms of development time and effort, to launch a site with custom data in compatible format and no UI customization, you can expect it to take less than three weeks. If you need substantial UI customization it may take up to four months.
+
+
The cost of running a site on Google Cloud Platform depends on the size of your data, the traffic you expect to receive, and the amount of geographical replication you want. For a singly-homed service with 5 GB of data serving 1 M queries per month, you can expect a cost of approximately $400 per month.
+
+
You can get precise information and cost estimation tools at Google Cloud pricing. A GCP setup must include:
+
+
Cloud SQL
+
Cloud Storage
+
Cloud Run: Job + Service
+
Artifact Registry (< 1 GB storage>)
+
+
+
You may also need Cloud DNS, Networking - Cloud Loadbalancing, and Redis Memorystore + VPC networking (see Launch your Data Commons for details).
+
+
Recommended workflow
+
+
+
Work through the Quickstart page to learn how to run a local Data Commons instance and load some sample data.
+
Prepare your real-world data and load it in the local custom instance. Data Commons requires your data to be in a specific format. See Prepare and load your own data for details.
+
+
Note: This section is very important! If your data is not in the scheme Data Commons expects, it won’t load.
+
+
+
If you want to customize the look of the feel of the site, see Customize the site.
+
When you have finished testing locally, host your data and code in Google Cloud Platform: first, upload your data to Google Cloud Storage and create a Cloud Run job to load the data into Google Cloud SQL. See Load data in Google Cloud.
+
Build a custom image, upload it to the Google Cloud Artifact Registry and create a Cloud Run service to run the site. See Deploy services to Google Cloud
Optionally, add a caching layer to improve performance. We have provided specific procedures to set up a Redis Memorystore in Improve database performance.
We recommend that you use a caching layer to improve the performance of your database. We recommend Google Cloud Redis Memorystore, a fully managed solution, which will boost the performance of both natural-language searches and regular database lookups in your site. Redis Memorystore runs as a standalone instance in a Google-managed virtual private cloud (VPC), and connects to your VPC network (“default” or otherwise) via direct peering. Your Cloud Run service connects to the instance using a VPC connector.
+We recommend that you use a caching layer to improve the performance of your database. We recommend Google Cloud Redis Memorystore, a fully managed solution, which will boost the performance of both natural-language searches and regular database lookups in your site. Redis Memorystore runs as a standalone instance in a Google-managed virtual private cloud (VPC), and connects to your VPC network (“default” or otherwise) via direct peering. Your Cloud Run service connects to the instance using a VPC connector.
+
+
In the following procedures, we show you how to create a Redis instance that connects to your project’s “default” VPC network.
+
+
Step 1: Create the Redis instance
+
+
The following is a sample configuration that you can tune as needed. For additional information, see Create and manage Redis instances.
+The following is a sample configuration that you can tune as needed. For additional information, see Create and manage Redis instances.
Step 4: Configure your Cloud Run service to connect to the VPC
+
+
+
In the Cloud Console, go to the Cloud Run service from which you are serving your app.
+
Click Edit & Deploy New Revision.
+
Click the Networking tab and enable Connect to a VPC for outbound traffic.
+
Enable Use Serverless VPC Access connectors.
+
From the Network field, select the connector you created in step 3.
+
Click Deploy.
+
+
+
Step 5: Verify that everything is working
+
+
To verify that your Cloud Run service is using the connector:
+
+
+
Go to the Service details page for your service
+
Click the Networking tab. Under VPC, you should see your connector listed.
+
+
+
To verify that traffic is hitting the cache:
+
+
+
Run some queries against your running Cloud Run service.
+
In the Cloud Console, go to the Memorystore page and select Redis instance.
+
Under Instance Functions, click Monitoring.
+
Scroll to the Cache Hit Ratio graph. You should see a significant percentage of your traffic hitting the cache.
+
+
+
Add Google Analytics reporting
+
+
Google Analytics provides detailed reports on user engagement with your site. In addition, Data Commons provides a number of custom parameters you can use to report on specific attributes of a Data Commons site such as, search queries, specific page views, etc.
+
+
Enable Analytics tracking
+
+
+
If you don’t already have a Google Analytics account, create one, following the procedures in Set up Analytics for a website and/or app. Record the Analytics tag ID assigned to your account.
+
Go to the Cloud Console for your Cloud Run service, and click Edit & deploy new revision.
+
Expand Variables and secrets and click Add new variable.
+
Add the name GOOGLE_ANALYTICS_TAG_ID and in the value field, type in your tag ID.
+
Click Deploy to redeploy the service. Data collection will take a day or two to start and begin showing up in your reports.
+
+
+
Report on custom dimensions
+
+
Data Commons exports many Google Analytics custom events and parameters, to allow Data Commons-specific features to be logged, such as search queries, specific page views, etc. You can use these to create custom reports and explorations. The full set is defined in website/static/js/shared/ga_events.ts. Before you can get reports on them, you need to create custom dimensions from them.
+
+
To create a custom dimension for a Data Commons custom event:
Keep the Scope as Event and click the Event parameter > Select event parameter drop-down to see the list of custom event parameters.
+
+
+
+
Select the parameter you need, for example, query.
+
Add a dimension name and description. These can be anything you want but the name should be meaningful as it will show up in reports; for example, Search query.
+
When done, click Save.
+
Select Data display > Events and you should see a number of new custom events that have been added to your account.
+
+
+
To create a report based on a custom event:
+
+
+
In the Google Analytics dashboard for your account, go to the Explore page and select Blank - create a new exploration.
+
Select Variables > Dimensions > + to open the Select dimensions window.
+
+
Select the Custom, select the dimension you want, for example, Search query, and click Import.
+
+
+
+
Select Variables > Metrics > + to open the Select metrics window.
+
Select the relevant metric you want, such as users, sessions, or views, etc. and click Import.
+
Select Settings > Rows > Drop or select dimension and from the drop-down menu, select the dimension you want, such as Search query.
+
Select Settings > Values > Drop or select metric and from the drop-down menu, select the metric of interest, such as users, sessions, views, etc.
+
Edit any other settings you like and name the report. For the first 48 hours you will see (not set) for the first row. Afterwards, rows will be populated with real values.
This page shows you how to run a local custom Data Commons instance inside Docker containers and load sample custom data from a local SQLite database. A custom Data Commons instance uses code from the public open-source repo, available at https://github.com/datacommonsorg/.
A Python-Flask web server, which handles interactive requests from users
+
An Python-Flask NL server, for serving natural language queries
+
A Go Mixer, also known as the API server, which serves programmatic requests using Data Commons APIs. The SQL query engine is built into the Mixer, which sends queries to both the local and remote data stores to find the right data. If the Mixer determines that it cannot fully resolve a user query from the custom data, it will make an REST API call, as an anonymous “user” to the base Data Commons Mixer and data.
If you are developing on Windows, install WSL 2 (any distribution will do, but we recommend the default, Ubuntu), and enable WSL 2 integration with Docker.
Optional: Get a Github account, if you would like to browse the Data Commons source repos using your browser.
+
+
+
One-time setup steps
+
+
Get a Data Commons API key
+
+
An API key is required to authorize requests from your site to the base Data Commons site. API keys are managed by a self-serve portal. To obtain an API key, go to https://apikeys.datacommons.org and request a key for the api.datacommons.org domain.
Click on the newly created key to open the Edit API Key window.
+
Under API restrictions, select Restrict key.
+
From the drop-down menu, enable Places API and Maps Javascript API. (Optionally enable other APIs for which you want to use this key.)
+
Click OK and Save.
+
+
+
Clone the Data Commons repository
+
+
Note: If you are using WSL on Windows, open the Linux distribution app as your command shell. You must use the Linux-style file structure for Data Commons to work correctly.
+
+
+
Open a terminal window, and go to a directory to which you would like to download the Data Commons repository.
If you don’t specify a directory name, this creates a local website subdirectory. If you specify a directory name, all files are created under that directory, without a website subdirectory.
+
+
+
+
When the downloads are complete, navigate to the root directory of the repo (e.g. website). References to various files and commands in these procedures are relative to this root.
+
+
+cd website
+
+
+
Set environment variables
+
+
+
Using your favorite editor, copy custom_dc/env.list.sample and save it as a new file custom_dc/env.list. It provides a template for getting started.
+
Enter the relevant values for DC_API_KEY and MAPS_API_KEY.
+
Set the INPUT_DIR to the full path to the website/custom_dc/sample/ directory. For example if you have cloned the repo directly to your home directory, this might be /home/USERNAME/website/custom_dc/sample/. (If you’re not sure, type pwd to get the working directory.)
+
For the OUTPUT_DIR, set it to the same path as the INPUT_DIR.
+
+
+
Warning: Do not use any quotes (single or double) or spaces when specifying the values.
Sample supplemental data that is added to the base data in Data Commons. This page describes the model and format of this data and how you can load and view it.
Contains customizable CSS file and default logo. To modify the styles or replace the logo, see Customize Javascript and styles.
+
+
+
+
+
Look at the sample data
+
+
Before you start up a Data Commons site, it’s important to understand the basics of the data model that is expected in a custom Data Commons instance. Let’s look at the sample data in the CSV files in the custom_dc/sample/ folder. This data is from the Organisation for Economic Co-operation and Development (OECD): “per country data for annual average wages” and “gender wage gaps”:
+
+
+
+
+
countryAlpha3Code
+
date
+
average_annual_wage
+
+
+
+
+
BEL
+
2000
+
54577.62735
+
+
+
BEL
+
2001
+
54743.96009
+
+
+
BEL
+
2002
+
56157.24355
+
+
+
BEL
+
2003
+
56491.99591
+
+
+
…
+
…
+
…
+
+
+
+
+
+
+
+
countryAlpha3Code
+
date
+
gender_wage_gap
+
+
+
+
+
DNK
+
2005
+
10.16733044
+
+
+
DNK
+
2006
+
10.17206126
+
+
+
DNK
+
2007
+
9.850297951
+
+
+
DNK
+
2008
+
10.18354903
+
+
+
…
+
…
+
…
+
+
+
+
+
There are a few important things to note:
+
+
There are only 3 columns: one representing a place (countryAlpha3Code, a special Data Commons place type); one representing a date (date); and one representing a statistical variable, which is a Data Commons concept for a metric: average_annual_wage and gender_wage_gap. (Actually, there can be any number of statistical variable columns – but no other types of additional columns – and these two CSV files could be combined into one.)
+
Every row is a separate observation, or a value of the variable for a given place and time. In the case of multiple statistical variable columns in the same file, each row would, of course, consist of multiple observations.
+
+
+
This is the format to which your data must conform if you want to take advantage of Data Commons’ simple import facility. If your data doesn’t follow this model, you’ll need to do some more work to prepare or configure it for correct loading. (That topic is discussed in detail in Preparing and loading your data.)
+
+
Load sample data
+
+
To load the sample data:
+
+
+
If you are running on Windows or Mac, start Docker Desktop and ensure that the Docker Engine is running.
+
+
Open a terminal window, and from the root directory, run the following command to run the data management Docker container:
+
+
docker run \
+--env-file$PWD/custom_dc/env.list \
+-v$PWD/custom_dc/sample:$PWD/custom_dc/sample \
+gcr.io/datcom-ci/datacommons-data:stable
+
+
This does the following:
+
+
+
+
+
The first time you run it, downloads the latest stable Data Commons data image, gcr.io/datcom-ci/datacommons-data:stable, from the Google Cloud Artifact Registry, which may take a few minutes. Subsequent runs use the locally stored image.
+
Maps the input sample data to a Docker path.
+
Starts a Docker container.
+
Imports the data from the CSV files, resolves entities, and writes the data to a SQLite database file, custom_dc/sample/datacommons/datacommons.db.
+
Generates embeddings in custom_dc/sample/datacommons/nl. (To learn more about embeddings generation, see the FAQ).
+
+
+
Once the container has executed all the functions in the scripts, it shuts down.
+
+
Start the services
+
+
+
Open a new terminal window.
+
From the root directory, run the following command to start the services Docker container:
Note: If you are running on Linux, depending on whether you have created a “sudoless” Docker group, you may need to preface every docker invocation with sudo.
+
+
+
This command does the following:
+
+
+
The first time you run it, downloads the latest stable Data Commons image, gcr.io/datcom-ci/datacommons-services:stable, from the Google Cloud Artifact Registry, which may take a few minutes. Subsequent runs use the locally stored image.
+
Starts a services Docker container.
+
Starts development/debug versions of the Web Server, NL Server, and Mixer, as well as the Nginx proxy, inside the container.
+
Maps the output sample data to a Docker path.
+
+
+
Stop and restart the services
+
+
If you need to restart the services for any reason, do the following:
+
+
+
In the terminal window where the container is running, press Ctrl-c to kill the Docker container.
Tip: If you close the terminal window in which you started the Docker services container, you can kill it as follows:
+
+
+
Open another terminal window, and from the root directory, get the Docker container ID.
+
docker ps
+
+
The CONTAINER ID is the first column in the output.
+
+
Run:
+
docker kill CONTAINER_ID
+
+
+
+
View the local website
+
+
Once the services are up and running, visit your local instance by pointing your browser to http://localhost:8080. You should see something like this:
+
+
+
+
Now click the Timeline link to visit the Timeline explorer. Click Start, enter an OECD country (e.g. Canada) and click Continue. Now, in the Select variables tools, you’ll see the new variables:
+
+
+
+
Select one (or both) and click Display to show the timeline graph:
+
+
+
+
To issue natural language queries, click the Search link. Try NL queries against the sample data you just loaded, e.g. “Average annual wages in Canada”.
+
+
+
+
Send an API request
+
+
A custom instance can accept REST API requests at the endpoint /core/api/v2/, which can access both the custom and base data. To try it out, here’s an example request you can make to your local instance that returns the same data as the interactive queries above, using the observation API. Try entering this query in your browser address bar:
docker: Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: ...
+dial unix /var/run/docker.sock: connect: permission denied.
+
+
+
or this:
+
+
docker: Error response from daemon: pull access denied for datacommons-services, repository does not exist or may require 'docker login': denied: requested access to the resource is denied.
+
If you’ve just installed Docker, try rebooting the machine.
+
+
+
Startup errors
+
+
“Failed to create metadata: failed to create secret manager client: google: could not find default credentials.”
+
+
If you try to run the services and fail with this error:
+
+
Failed to create metadata: failed to create secret manager client: google: could not find default credentials. See https://cloud.google.com/docs/authentication/external/set-up-adc for more information. See https://cloud.google.com/docs/authentication/external/set-up-adc for more information
+
+
+
This indicates that you have not specified API keys in the environment file. Follow procedures in One-time setup steps to obtain and configure API keys.
+
+
“SQL schema check failed”
+
+
This error indicates that there has been an update to the database schema, and you need to update your database schema by re-running the data management job as follows:
+
+
+
Rerun the data management Docker container, optionally adding the flag -e DATA_RUN_MODE=schemaupdate to the docker run command. This updates the database schema without re-importing data or re-building natural language embeddings.
+
Restart the services Docker container.
+
+
+
For full command details, see the following sections:
If you are building a local instance and get this error:
+
+
Step 7/62 : COPY mixer/go.mod mixer/go.sum ./
+COPY failed: file not found in build context or excluded by .dockerignore: stat mixer/go.mod: file does not exist
+
+
You need to download/update additional submodules (derived from other repos). See Build a local image.
+
+
NL queries not returning custom data
+
+
If you have previously been able to get custom data in your natural-language query results, but this has suddenly stopped working, this is due to embeddings incompatibility issues between releases. To fix this, do the following:
+
+
Delete the datacommons subdirectory from your output directory, either locally or in your Google Cloud Storage bucket.
+
Rerun the data management container, as described in Load data in Google Cloud, and restart the services container.
+
+
+
Website display problems
+
+
If styles aren’t rendering properly because CSS, logo files or JS files are not loading, check your Docker command line for invalid arguments. Often Docker won’t give any error messages but failures will show up at runtime.
+
+
Website form input problems
+
+
If you try to enter input into any of the explorer tools fields, and you get this:
+
+
+
+
This is because you are missing a valid API key or the necessary APIs are not enabled. Follow procedures in Enable Google Cloud APIs and get a Maps API key, and be sure to obtain a permanent Maps/Places API key.
+
+
Cloud Run Service problems
+
+
In general, whenever you encounter problems with any Google Cloud Run service, check the Logs page for your Cloud Run service, to get detailed output from the services.
+
+
“403 Forbidden: Your client does not have permission to get URL / from this server”
+
+
This error indicates that your application requires authenticated requests but you have not provided an authentication token. If your site is intended to be public, first check to see that the Cloud Run service is not set up to require authentication:
From the list of services, select the relevant service and select the Security tab.
+
Ensure that you have enabled Allow unauthenticated invocations and restart the Cloud Run service.
+
+
+
If you are unable to select this option, this indicates that there is an IAM permissions setup issue with your project or account. See the Cloud Run Troubleshooting for details on how to fix this.
+
+
“502 Bad Gateway”
+
+
This is a general indication that the Data Commons servers are not running. Check the **Logs ** page for the Cloud Run service in the Google Cloud Console. Here are common errors:
+
+
403 Forbidden: Not authorized to access resources
+
+
This may be due to multiple reasons. First try the following:
+
+
In the Cloud Run service page in the Cloud Console, select the Revisions tab, and scroll to view the Environment variables.
+
Ensure that the DB_USER and DB_PASS variables are set to the values you set when creating the SQL database.
+
+
+
If you see no errors in the logs, except connect() failed (111: Connection refused) while connecting to upstream, try the following:
+
+
+
Wait a few minutes and try to access the app again. Sometimes it appears to be deployed, but some of the services haven’t yet started up.
+
In the Cloud Run Service details page, click the Revisions tab. Under the Containers tab, under General, check that CPU Allocation is set to CPU is always allocated. If it is not, click Edit & Deploy New Revision, and the Containers tab. Under CPU allocation and pricing enable CPU is always allocated and click Deploy.
Whether you’re just exploring the data on datacommons.org, using the programmatic APIs, or contributing data, it’s helpful to have a basic understanding of some of the key concepts in Data Commons. Use the following guidance:
+
+
If you are only using Data Commons interactive tools, Google Sheets or CSV download, you should at least be familiar with entities and statistical variables. You may wish to just skip directly to those sections.
+
If you plan to use the programmatic APIs, contribute data, or run your own Data Commons, you should read this entire page.
To allow data from hundreds of organizations around the world, in a myriad of models and formats to be interoperable and queryable in a unified way, Data Commons needs to have a common way of understanding and representing this data. To do so, it applies a schema, or vocabulary to all its data, that is largely derived from earlier schemes developed for semantic understanding of web pages – most notably, the data models and schemas of Schema.org (which were in turn based on earlier schemes such as Microformats and Resource Description Framework (RDF)).
+
+
The Data Commons schema is in fact a superset of Schema.org schemas, with a particular emphasis on time series and statistical data. Every data set must have an associated schema, written in Meta Content Format (MCF) language, that maps the provider’s data to existing concepts in the Data Commons.
+
+
Knowledge Graph
+
+
Data Commons models the world as a directed labeled graph, consisting of a set of nodes and edges with labels, known as properties. This general framework allows Data Commons to represent information about a wide range of domains: from time series about demographics and employment, to hurricanes, to protein structures.
+
+
As a simple example, here are a set of nodes and edges that represent the following statements:
+
+
+
California is a state
+
Santa Clara county and Berkeley are contained in the state of California
+
The latitude of Berkeley, CA is 37.8703
+
+
+
+
+
Each node consists of some kind of entity or value, and each edge describes some kind of property. More specifically, each node consists of the following objects:
As in other knowledge graphs, each pair of connected nodes is a triple consisting of a subject node, predicate (or “edge”) and object node. The Data Commons knowledge graph is made up of billions of triples. The triple is not generally exposed in Data Commons as a concept that you need to know (although it can be queried from some APIs).
+
+
You can get all the information about a node and its edges by looking at the Knowledge Graph browser. If you know the DCID for a node, you can access it directly by typing https://datacommons.org/browser/DCID. For example, here is the entry for the City node, available at https://datacommons.org/browser/City:
+
+
+
+
Every node entry shows a list of outgoing edges, or properties, and incoming edges. Properties are discussed in more detail below.
+
+
Type
+
+
Every node has at least one type, where each type may be a sub-class of multiple types. For entities and events, their type is typically another entity. For example, Berkeley is a type of City. At the root, all types are instances of the Class type. For statistical variables and observations, their type is always StatisticalVariable and StatVarObservation, respectively.
+
+
Entity
+
+
An entity represents a persistent, physical thing in the real world. While Data Commons has information about a wide variety of types of entities (cities, states, countries, schools, companies, facilities, etc.), most of the information today is about places. Data Commons contains a catalog of about 2.9 million places. In addition to basic metadata like the location, type and containment information, many places also contain information about their shape, area, etc. For a list of available place types, take a look at the place types page.
+
+
Event
+
+
An event is what it sounds like: an occurrence at a specific point in time, such as an extreme weather event, a criminal incident, an election, etc.
+
+
Statistical variable
+
+
In Data Commons, even statistical measurements and time series data are modeled as nodes. A statistical variable represents any type of metric, statistic, or measurement that can be taken at a place and time, such as a count, an average, a percentage, etc. A statistical variable for a specific place is a time series, consisting of a set of observed values over a time period.
+
+
Data Commons comprises hundreds of thousands of statistical variables, which you can view using the Statistical Variable Explorer.
A statistical variable can be simple, such as Total Population, or more complex, such as Hispanic Female Population. Complex variables may be broken down into constituent parts, or not.
+
+
Task: Find places available for a statistical variable
+
+
Note that not all statistical variables have observations for all places or other entities. To find out which places have data for a given variable, you can do the following:
On the other hand, the Average Retail Price of Electricity, or Quarterly_Average_RetailPrice_Electricity, is only available at the state level states in the US but not at the city or county level.
+
+
+
+
Unique identifier: DCID
+
+
Every node has a unique identifier, called a Data Commons ID, or DCID. In the Knowledge Graph browser, you can view the DCID for any node or edge. For example, the DCID for the city of Berkeley is geoid/0606000:
+
+
+
+
DCIDs are not restricted to entities; statistical variables also have DCIDs. For example, the DCID for the Gini Index of Economic Activity is GiniIndex_EconomicActivity:
+
+
+
+
Task: Find a DCID for an entity or variable
+
+
Many Data Commons tools and APIs require that you provide a DCID as input for a query. There are a few ways to do this.
+
+
To find the DCID for a place using the datacommons.org website:
Use the REST v2 Resolve API, either interactively (e.g. using curl or the browser address bar) or programmatically.
+
+
+
To find the DCID for a statistical variable:
+
+
+
Open the Statistical Variable Explorer.
+
Search for the variable of interest, and optionally filter by data source and dataset.
+
Look under the heading for the DCID.
+
+
+
+
+
Property
+
+
Every node also contains properties or characteristics that describe its entity, event, or statistical variable. Each property is actually an edge to another node, with a label. If the object node is a primitive type, such as a string, date, or number, it is a “leaf”, or terminal node, which we call an attribute. Examples are properties such as latitude, year, various unique IDs and so on.
+
+
Other properties are links to other entities/events/ etc. In the Knowledge Graph, you can click through links to non-terminal nodes.
+
+
For example, in this node for the city of Addis Ababa, Ethiopia, the typeOf and containedInPlace edges link to other entities, namely City and Ethiopia, whereas all the other values are terminal.
+
+
+
+
Note that the DCID for a property is the same as its name.
+
+
Observation
+
+
An observation is a single measured value for a statistical variable, at or during a specified period of time, for a specific entity.
+
+
For example, the value of the statistical variable Median Age of Female Population for the city of San Antonio, Texas in 2014 could have an observation Observation_Median_Age_Person_Female_SanAntonio_TX_2014. The type of an observation is always the special sub-class StatVarObservation.
Every node and triple also have some important properties that indicate the origin of the data.
+
+
+
Provenance: All triples have a provenance, typically the URL of the data provider’s website; for example, www.abs.gov.au. In addition, all entity types also have a provenance, defined with a DCID, such as AustraliaStatistics. It also (For many property types, which are defined by the Data Commons schema, their provenance is always datacommons.org.)
+
Source: This is a property of a provenance, and a dataset, usually the name of an organization that provides the data or the schema. For example, for provenance www.abs.gov.au, the source is the Australian Bureau of Statistics.
+
Dataset: This is the name of a specific dataset provided by a provider. Many sources provide multiple datasets. For example, the source Australian Bureau of Statistics provides two datasets, Australia Statistics (not to be confused with the provenance above), and Australia Subnational Administrative Boundaries.
+
+
+
+
+
Note that a given statistical variable may have multiple provenances, since many data sets define the same variables. You can see the list of all the data sources for a given statistical variable in the Statistical Variable Explorer. For example, the explorer shows multiple sources (Censuses from India, Mexico, Vietnam, OECD, World Bank, etc.) for the variable Life Expectancy:
+
+
+
+
You can see a list of all sources and data sets in several places:
Conducted by the National Agricultural Statistics Service, this survey contains information about agricultural production, economics, demographics and the environment.
The Census of Agriculture contains information about land use, operators, production, and finances of US farms and ranches. Data Commons contains several of the Census tables relating to crop production and operator demographics from the 2017 Census.
The ENCODE experimental dataset contains information for approximately 7000 experiments along with 14,000 BED files collected by The Encyclopedia of DNA Elements (ENCODE) Consortium. Examples of experiment metadata captured include the target biosample, assay type, gene assembly, etc. Data Commons include the meta data for all experimental datasets in ENCODE as of 2019.
+
+
Data made available under: ENCODE Data Use Policy for External Users. This data was formatted for Data Commons through a collaboration with Dr. Anthony Oro’s group at Stanford University.
Data Commons includes protein sequence and functional information including protein interaction with chemical compounds maintained by the UniProt Consortium. The data is made available by the Creative Commons Attribution (CC BY 4.0) License. Further information on UniProt License and Disclaimer can be found here. The UniProt Consortium states how to cite UniProt data used in a journal article.
“The Sequence Ontology is a set of terms and relationships used to describe the features and attributes of biological sequence. SO includes different kinds of features which can be located on the sequence. Biological features are those which are defined by their disposition to be involved in a biological process. Examples are ‘binding site’ and ‘exon’. Biomaterial features are those which are intended for use in an experiment such as aptamer and PCR_product. There are also experimental features which are the result of an experiment. SO also provides a rich set of attributes to describe these features such as ‘polycistronic’ and ‘maternally imprinted’.”
+Gene Ontology Consortium data and data products are licensed under the Creative Commons Attribution 4.0 Unported License. When using or citing GO data please mention the particular release. For example, include where applicable the date (e.g. ‘2024-01-17’), Zenodo DOI (e.g. ‘10.5281/zenodo.10536401’), and links. More information on licensing and attribution in regards to the Gene Ontology Consortium can be found here.
The official, current virus taxonomy approved by the ICTV. To accomplish the task of organizing and maintaining this virus taxonomy, the ICTV is composed of 7 subcommittees covering Animal DNA viruses and Retroviruses, Animal dsRNA and ssRNA (-) viruses, Animal ssRNA (+) viruses, Bacterial viruses, Archaeal Viruses, Fungal and Protist viruses, and Plant viruses. The ICTV has established over 100 international Study Groups (SGs) covering all major virus families and genera. The MSL version currently in the graph is MSL38 v3 released on 2023-09-11.
The ICTV chooses an exemplar virus for each species and the VMR provides a list of these exemplars. An exemplar virus serves as an example of a well-characterized virus isolate of that species and includes the GenBank accession number for the genomic sequence of the isolate as well as the virus name, isolate designation, suggested abbreviation, genome composition, and host source. The VMR version currently in the graph is VMR MSL38 v2 released on 2023-09-13.
+This data is made available under Creative Commons Attribution ShareAlike 4.0 International (CC BY-SA 4.0).
DISEASES is a weekly updated web resource that integrates evidence on disease-gene associations from automatic text mining, manually curated literature, cancer mutation data, and genome-wide association studies. This dataset further unifies the evidence by assigning confidence scores that facilitate comparison of the different types and sources of evidence. All files start with the following four columns: gene identifier, gene name, disease identifier, and disease name. The knowledge files further contain the source database, the evidence type, and the confidence score. For further details please refer to the following Open Access articles about the database: DISEASES: Text mining and data integration of disease-gene associations and DISEASES 2.0: a weekly updated database of disease–gene associations from text mining and data integration. The data is made available under the CC-BY license.
DISEASES is a weekly updated web resource that integrates evidence on disease-gene associations from automatic text mining, manually curated literature, cancer mutation data, and genome-wide association studies. This dataset further unifies the evidence by assigning confidence scores that facilitate comparison of the different types and sources of evidence. All files start with the following four columns: gene identifier, gene name, disease identifier, and disease name. The experiments files instead contain the source database, the source score, and the confidence score. For further details please refer to the following Open Access articles about the database: DISEASES: Text mining and data integration of disease-gene associations and DISEASES 2.0: a weekly updated database of disease–gene associations from text mining and data integration. The data is made available under the CC-BY license.
DISEASES is a weekly updated web resource that integrates evidence on disease-gene associations from automatic text mining, manually curated literature, cancer mutation data, and genome-wide association studies. This dataset further unifies the evidence by assigning confidence scores that facilitate comparison of the different types and sources of evidence. All files start with the following four columns: gene identifier, gene name, disease identifier, and disease name. The textmining files contain the z-score, the confidence score, and a URL to a viewer of the underlying abstracts. For further details please refer to the following Open Access articles about the database: DISEASES: Text mining and data integration of disease-gene associations and DISEASES 2.0: a weekly updated database of disease–gene associations from text mining and data integration. The data is made available under the CC-BY license.
The Pharmacogenomics Knowledge Base, PharmGKB, is an interactive tool for researchers investigating how genetic variation affects drug response. PharmGKB displays genotype, molecular, and clinical knowledge integrated into pathway representations and Very Important Pharmacogene (VIP) summaries with links to additional external resources. Users can search and browse the knowledge base by genes, variants, drugs, diseases, and pathways. The Primary Data contains summary information on chemicals, drugs, genes, genetic variants, and phenotypes.
PharmGKB reports association between chemicals, diseases, genes, and genetic variants, both with themselves and with each other.
+
+
Data made available under Creative Commons Attribution-ShareAlike 4.0 Intergovernmental Organization (CC BY-SA 4.0 IGO) licence. Explicit licensing for PharmGKB can be viewed on the download page.
The Human Protein Tissue Atlas contains information about the distribution of proteins on human tissues derived from the antibody-based protein profiling from 44 normal human tissues types and mRNA expression data from 37 different normal tissue types.
“The NCBI Assembly database provides stable accessioning and data tracking for genome assembly data. The model underlying the database can accommodate a range of assembly structures, including sets of unordered contig or scaffold sequences, bacterial genomes consisting of a single complete chromosome, or complex structures such as a human genome with modeled allelic variation. The database provides an assembly accession and version to unambiguously identify the set of sequences that make up a particular version of an assembly, and tracks changes to updated genome assemblies. The Assembly database reports metadata such as assembly names, simple statistical reports of the assembly (number of contigs and scaffolds, contiguity metrics such as contig N50, total sequence length and total gap length) as well as the assembly update history. The Assembly database also tracks the relationship between an assembly submitted to the International Nucleotide Sequence Database Consortium (INSDC) and the assembly represented in the NCBI RefSeq project” (Kitts et al. 2016). In this import we include the metadata for all genome assemblies documented in assembly_summary_genbank.txt and assembly_summary_refseq.txt. Assemblies are stored in GenomeAssembly nodes whose information is integrated from both the GenBank and RefSeq datasets.
“NCBI Gene supplies gene-specific connections in the nexus of map, sequence, expression, structure, function, citation, and homology data. Unique identifiers are assigned to genes with defining sequences, genes with known map positions, and genes inferred from phenotypic information. These gene identifiers are used throughout NCBI’s databases and tracked through updates of annotation. Gene includes genomes represented by NCBI Reference Sequences (or RefSeqs) and is integrated for indexing and query and retrieval from NCBI’s Entrez and E-Utilities systems. Gene comprises sequences from thousands of distinct taxonomic identifiers, ranging from viruses to bacteria to eukaryotes. It represents chromosomes, organelles, plasmids, viruses, transcripts, and millions of proteins.”
“NCBI Taxonomy “consists of a curated set of names and classifications for all of the source organisms represented in the International Nucleotide Sequence Database Collaboration (INSDC). The NCBI Taxonomy database contains a list of names that are determined to be nomenclaturally correct or valid (as defined according to the different codes of nomenclature), classified in an approximately phylogenetic hierarchy (depending on the level of knowledge regarding phylogenetic relationships of a given group) as well as a number of names that exist outside the jurisdiction of the codes. That is, it focuses on nomenclature and systematics, rather than documenting the description of taxa.”
The Medical Subject Headings (MeSH) thesaurus is a controlled and hierarchically-organized vocabulary produced by the National Library of Medicine. It is used for indexing, cataloging, and searching of biomedical and health-related information. Data Commons includes the Concept, Descriptor, Qualifier, Supplementary Concept Record, and Term elements of MeSH as described here defined by all four xml files provided by MeSH (desc, pa, qual, and supp). Data Commons includes production year 2024 MeSH.
PubChem is the world’s largest collection of freely accessible chemical information. Search chemicals by name, molecular formula, structure, and other identifiers. Find chemical and physical properties, biological activities, safety and toxicity information, patents, literature citations and more.
+
+
This data is from the National Library of Medicine (NLM) and is not subject to copyright and is freely reproducible as stated in the NLM’s copyright policy.
The Disease Ontology was developed as a project by the Institute of Genome Sciences at the University of Maryland School of Medicine. It “is a community driven, open source ontology that is designed to link disparate datasets through disease concepts”. It provides a “standardized ontology for human disease with the purpose of providing the biomedical community with consistent, reusable and sustainable descriptions of human disease terms, phenotype characteristics and related medical vocabulary disease concepts”.
Data Commons has imported variables related to demographics, in particular concerning literacy, work, housing, and religion from the Indian Census on the state, district, and city level.
Feeding america’s mission is to advance change in America by ensuring equitable access to nutritious food for all in partnership with food banks, policymakers, supporters, and the communities we serve.
India Local Government Directory provides unique codes for revenue entities such as districts, villages, local government bodies.
+Copyright, Terms of Use.
India National Family Health Survey - Data on population dynamics and health indicators as well as data on emerging issues in health and family welfare and associated domains.
Outcomes (social mobility and a variety of other outcomes from life expectancy to patent rates) by neighbourhood, college, parental income level and racial background. For Census tracts, county and commuting zone.
+
Neighbourhood characteristics for Census tracts, county and commuting zones.
Information related to transportation characteristics for households which includes data at Census Tract level on daily personal travel, including information on household and demographic characteristics, employment status, vehicle ownership, trips taken, modal choice, and other related transportation data pertinent to U.S. households.
The American Community Survey covers a broad range of topics about social, economic, demographic, and housing characteristics of the U.S. population. The ACS 5-year (and 1-year) estimates are updated every year, based on the last 5 years (1 year) of collected data. Data Commons includes thousands of variables across the full range of ACS topics at the country, state, county, city, zip code tabulation area, school district, census tract levels, and more.
The Census Bureau’s Population Estimates Program (PEP) produces yearly estimates of the population for the United States, its states, counties, cities, and towns, as well as for the Commonwealth of Puerto Rico and its municipios. Data Commons imports the total population estimate data for the US and its states, counties, and cities.
Basic population, race demographics and housing statistics from the redistricting data release of US Decennial Census mapped down to block-group level.
+U.S. Census Terms of Service.
The statistics for prevalence of asthma among adults is for counties in 50 states and prevalence of asthma among children is for counties in 27 participating states. The data source is the 2016–2018 Behavioral Risk Factor Surveillance System (BRFSS) which is merged with the 2013 National Center for Health Statistics (NCHS) Urban-Rural Classification Scheme for Counties.
Weekly and Annual cases of selected national notifiable (infectious and non-infectious) diseases reported by the 50 states, New York City, the District of Columbia, and the U.S. territories.
Includes “counts of live births occurring within the United States to U.S. residents. Counts can be obtained by a variety of demographic characteristics, such as state and county of residence, mother’s race, and mother’s age, and health and medical items, such as tobacco use, method of delivery, and congenital anomalies. The data are derived from birth certificates.”
EDA has led the federal economic development agenda by promoting innovation and competitiveness, preparing American regions for growth and success in the worldwide economy.
NTIA programs and policymaking focus largely on expanding broadband Internet access and adoption in America, expanding the use of spectrum by all users.
Data Commons has imported 80th and 150th percentile median family income estimates for different household sizes for US counties and county subdivisions.
General descriptive information such as name, address, and phone number; select demographic characteristics about students and staff; and fiscal data such as revenues and current expenditures. Data Commons includes school and school district level data about student populations by race, gender, lunch eligibility, and grade, as well as student-teacher ratio and teacher count statistics.
General descriptive information such as name, address, and phone number; select demographic characteristics about students and staff. Data Commons includes school data about student populations by race, grade, as well as student-teacher ratio and teacher count statistics.
The Open Geography portal from the Office for National Statistics (ONS) provides free and open access to the definitive source of geographic products, web applications, story maps, services and APIs.
Subnational administrative boundaries for a set of countries outside of the US and Europe. Includes state-equivalent and county-equivalent administrative levels. Terms of Use for this dataset.
Data Commons includes some information about administrative divisions, municipalities, cities, villages and neighborhoods of all countries in the world from Wikidata. This also includes population statistics and various well-known identifiers associated with the places.
This dataset represents the boundaries of the 10 main oceans and seas (Arctic Ocean, North and South Atlantic Ocean, North and South Pacific Ocean, Southern Ocean, Indian Ocean, Baltic Sea, Mediterranean Region, South China and Eastern Archipelagic Seas). The boundaries are largely based on the publication ‘Limits of Oceans & Seas, Special Publication No. 23’, published by the IHO in 1953. The dataset is available in World Geodetic System of 1984 (WGS84). This dataset was composed by the Flanders Marine Data Centre.
OpenFIGI is a system for identifying global financial instruments. It provides tools for Identifying, mapping, and requesting a free Financial Instrument Global Identifier (FIGI)
Price parity data measuring the differences in price levels across states and metropolitan areas for a given year and are expressed as a percentage of the overall national price level.
+Terms of Use.
Employment, unemployment, and labor force data for Census regions and divisions, States, counties, metropolitan areas, and many cities, by place of residence.
The American Community Survey covers a broad range of topics about social, economic, demographic, and housing characteristics of the U.S. population. The ACS 5-year (and 1-year) estimates are updated every year, based on the last 5 years (1 year) of collected data. Data Commons includes thousands of variables across the full range of ACS topics at the country, state, county, city, zip code tabulation area, school district, census tract levels, and more.
EDA has led the federal economic development agenda by promoting innovation and competitiveness, preparing American regions for growth and success in the worldwide economy.
Data Commons has imported 80th and 150th percentile median family income estimates for different household sizes for US counties and county subdivisions.
Data Commons includes all published statistics for 1-Month, 3-Month, 6-Month, 1-Year, 2-Year, 3-Year, 5-Year, 7-Year, 10-Year, 20-Year, and 30-Year constant maturities.
Participation in early childhood education by sex (children aged 4 and over). The indicator measures the share of the children between the age of four and the starting age of compulsory primary education who participated in early childhood education.
The Unified District Information System for Education (UDISE), by the Ministry of Education, India, collects and provides data related to schools and their resources.
The National Center for Education Statistics collaborates with the US Census Bureau to create a variety of custom data files that describe the condition of school-age children in the United States at the country, state, and school district level. ACS-ED is updated annually based on ACS five-year period estimates.
General descriptive information such as name, address, and phone number; select demographic characteristics about students and staff; and fiscal data such as revenues and current expenditures. Data Commons includes school and school district level data about student populations by race, gender, lunch eligibility, and grade, as well as student-teacher ratio and teacher count statistics.
General descriptive information such as name, address, and phone number; select demographic characteristics about students and staff. Data Commons includes school data about student populations by race, grade, as well as student-teacher ratio and teacher count statistics.
National Center for Science and Engineering Statistics provide data on the status of the science and engineering enterprise in the U.S. and other countries.
County, state, and plant-level data on generation, consumption, and sales for different energy sources and “sectors” (residential, commercial, etc). Data Commons has imported data about coal, electricity, natural gas, nuclear outages, and petroleum.
Historical Data about Greehouse Gas (GHG) emissions from 10 sectors and various sub-sectors at country level.
+The Climate TRACE data is made available through the Climate TRACE terms of use.
The events for places with unusual temperatures, either too hot or too cold, computed with reference to long term temperature averages, e.g. the average maximum daily temperature in January over the years 1980-2010.
Places with WetBulb Temperature exceeding 30 degree Celsius as per NASA’s Modern-Era Retrospective analysis for Research and Applications version 2 (MERRA-2) dataset on Google Earth Engine.
This dataset includes flooded regions computed from the Dynamic World dataset. These are regions labelled as water and outside regions marked as permanent water in the Hansen Global Forest Change dataset.
+
+
This dataset is produced for the Dynamic World Project by Google in partnership with National Geographic Society and the World Resources Institute.
ERA5 is the fifth generation ECMWF atmospheric reanalysis of the global climate. Reanalysis combines model data with weather observations from across the world into a globally complete and consistent dataset.
The National Flood Insurance Program (NFIP), managed by the Federal Emergency Management Agency (FEMA), enables homeowners, business owners and renters in participating communities to purchase federally backed flood insurance. The data includes insurance claims and amounts paid for flood damage to buildings and its contents aggregated by census-tracts, counties and states.
+This product uses the Federal Emergency Management Agency’s OpenFEMA API, but is not endorsed by FEMA. The Federal Government or FEMA cannot vouch for the data or analyses derived from these data after the data have been retrieved from the Agency’s website(s).
Data Commons includes relative measures of risk from the 18 natural hazards included in the study for counties and census tracts, as well as annual expected loss figures in USD from individual hazards and in aggregate. This study and associated data are released with this disclaimer.
Water quality data measured at ground and surface water qualiy stations across India providing concentrations of dissolved constituents in water in terms of physical, chemical and biological parameters.
Population connected to the waste water treatment using different methods from the Organisation for Economic Co-operation and Development (OECD) for different countries.
+License
This dataset incorporates statistics aggregated by RFF from the following
+sources:
+
+
+
+
Temperature, precipitation, and vapor pressure deficit data were obtained
+from PRISM Climate Group, Oregon State University. Available at:
+https://prism.oregonstate.edu/recent/. All data span the years 1981 to 2020.
+Data on maximum temperature, vapor pressure deficit, and precipitation are
+monthly. Data on minimum temperature are daily.
+
+
License: All data retrieved from https://prism.oregonstate.edu may be freely
+reproduced and distributed for non-commercial purposes only.
+
+
+
Palmer Drought Severity Index (PDSI) data come from gridMET. Data are daily for the years 1981 to 2020.
+
+
License: These data are freely available for public use.
+
+
+
Data on forest cover and fire severity in the western US is from Parks &
+Abatzoglou (2020), available here.
+
+
License: This work is licensed under a CC0 1.0 Universal (CC0 1.0) Public Domain
+Dedication license.
+
+
+
County-level population estimates from the US Census Bureau. Available
+here
+
+
License: These data are freely available for public use.
+
+
+
Data on heatwaves come from Resources for the Future and Google Data Commons,
+available here.
+
+
License: RFF derives heatwave indicators from daily minimum temperature data
+ generated by PRISM Climate Group, University of Oregon. When using these
+ data, please clearly and prominently state the PRISM Climate Group and their
+ URL ( https://prism.oregonstate.edu/ ). According to PRISM’s terms of use,
+ these data may be freely reproduced and distributed for non-commercial
+ purposes only.
+
+
+
MTBS Data Access: Fire Level Geospatial Data. MTBS Project (USDA Forest
+Service/U.S. Geological Survey), available online
+here.
+
+
License: These data are freely available for public use.
+
+
+
Data on PM2.5 from wildfire smoke is from Childs et al. 2022, available
+here.
+
+
License: Permission is hereby granted, free of charge, to any person
+obtaining a copy, of this software and associated documentation files (the
+“Software”), to deal in the Software without restriction, including without
+limitation the rights to use, copy, modify, merge, publish, distribute,
+sublicense, and/or sell copies of the Software, and to permit persons to
+whom the Software is furnished to do so, subject to the following
+conditions:
+
+
+
+
The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+
+
The software is provided “as is”, without warranty of any kind, express or
+implied, including but not limited to the warranties of merchantability,
+fitness for a particular purpose and noninfringement. In no event shall
+the authors or copyright holders be liable for any claim, damages or other
+liability, whether in an action of contract, tort or otherwise, arising
+from, out of or in connection with the software or the use or other
+dealings in the software.
+
+
+
+
+
+
This data is made available for non-commercial purposes only.
Information related to transportation characteristics for households which includes data at Census Tract level on daily personal travel, including information on household and demographic characteristics, employment status, vehicle ownership, trips taken, modal choice, and other related transportation data pertinent to U.S. households.
Data Commons has imported data on Palmer Drought Severity Index, Standardiazed Precipitation Evapotranspiration Index, Standardized Precipitation Index, Ozone, and PM2.5.
The National Emissions Inventory (NEI) is a comprehensive and detailed estimate of air emissions of criteria pollutants, hazardous pollutants and greenhouse gases from 188 onroad air emission sources (mobile sources such as highway and border crossing vehicles electricity measurement), 248 nonroad air emissions sources (mobile sources such as off-highway vehicle gasoline measurement), 703 nonpoint air emissions sources (such as industrial processes, oil and gas exploration and production) and 5818 point air emissions sources (such as chemical and organic solvent evaporation measurement) at the US county level.
Sea Level projections from 2020 to 2150 for all future scenarios in CMIP6 on a regular global grid and local projections at individual tide gauge locations.
The Visible Infrared Imaging Radiometer Suite (VIIRS) aboard S-NPP satellite provides 375m resolution data for active fires. This dataset includes area under fire per level 13 S2 cell every day starting in 2012.
The IBTrACS project provides tropical cyclone best track data in a centralized location. Data Commons includes cyclone name, start date, end date, max wind speed, minimum pressure, max classification, oceanic basin, and affected places.
Occurrence of storms and other significant weather phenomena having sufficient intensity to cause loss of life, injuries, significant property damage, and/or disruption to commerce; rare, unusual, weather phenomena that generate media attention, such as snow flurries in South Florida or the San Diego coastal area; and other significant meteorological events, such as record maximum or minimum temperatures or precipitation that occur in connection with another event.
Water use data for states and counties in the US, broken down by water source (ground water, surface water), water type (fresh water, saline water), and category of use (domestic, industrial, etc.).
The Dartmouth Atlas Project “uses Medicare and Medicaid data to provide information and analysis about national, regional, and local markets, as well as hospitals and their affiliated physicians.” Data Commons includes the Medicare Reimbursements, Medicare Mortality Rates, and Selected Primary Care Access and Quality Measures datasets.
Health statistics measure both objective and subjective aspects of people’s health. They cover different kinds of health-related aspects, including key indicators on the functioning of the health care systems and health and safety at work.
Feeding america’s mission is to advance change in America by ensuring equitable access to nutritious food for all in partnership with food banks, policymakers, supporters, and the communities we serve.
Google’s COVID-19 Community Mobility Reports “chart movement trends over time by geography, across different categories of places such as retail and recreation, groceries and pharmacies, parks, transit stations, workplaces, and residential.” Data Commons includes all statistics for countries, US states, and US counties.
National Health Mission (NHM) is a flagship programme of the Government of India to address the health needs of under-served ruralareas and health concerns of the urban poor population.
The Health management Information System (HMIS) of the National Health Mission, India captures medical facility-wise information such as reproductive, meternal and child health, immunization, family planning and vector borne diseases on a monthly basis ats district, state and national levels.
The India National Sample Survey (NSS) Organizes and conducts large scale all-India sample surveys on different population groups in diverse socio economic areas, such as employment, consumer expenditure, housing conditions and environment, literacy levels, health, nutrition, family welfare, etc.
Household health survey on profile of ailments including their treatment, role of government and private facilities in providing healthcare, expenditure on medicines, expenditure on medical consultation and investigation, hospitalization and expenditure, maternity and childbirth, the condition of the aged, etc.
+Terms of Use
India National Family Health Survey - Data on population dynamics and health indicators as well as data on emerging issues in health and family welfare and associated domains.
The New York Times releases cumulative counts of coronavirus cases in the United States at the country, state, and county level, over time. The New York Times compiles this time series data from state and local governments and health departments in an attempt to provide a complete record of the ongoing outbreak. Data Commons imports this data and computes incremental counts for users.
The Small Area Health Insurance Estimates program provides yearly estimates of health insurance coverage status for all counties and states. Data Commons includes all estimates, available by age, race, sex, and income.
The statistics for prevalence of asthma among adults is for counties in 50 states and prevalence of asthma among children is for counties in 27 participating states. The data source is the 2016–2018 Behavioral Risk Factor Surveillance System (BRFSS) which is merged with the 2013 National Center for Health Statistics (NCHS) Urban-Rural Classification Scheme for Counties.
Weekly and Annual cases of selected national notifiable (infectious and non-infectious) diseases reported by the 50 states, New York City, the District of Columbia, and the U.S. territories.
National Outbreak Reporting System (NORS) data from reports of foodborne and waterborne disease outbreaks and enteric (intestinal) disease outbreaks spread by contact with environmental sources, infected people or animals, and other means.
“PLACES provides model-based, population-level analysis and community estimates of health measures to all counties, places (incorporated and census designated places), census tracts, and ZIP Code Tabulation Areas (ZCTAs) across the United States.”
Pregnancy Risk Assessment Monitoring System (PRAMS) is a population-based surveillance system designed to identify groups of women and infants at high risk for health problems, to monitor changes in health status, and to measure progress towards goals in improving the health of mothers and infants.
Includes “counts of live births occurring within the United States to U.S. residents. Counts can be obtained by a variety of demographic characteristics, such as state and county of residence, mother’s race, and mother’s age, and health and medical items, such as tobacco use, method of delivery, and congenital anomalies. The data are derived from birth certificates.”
Data from the Automated Reports and Consolidated Ordering System (ARCOS) is a data collection system in which manufacturers and distributors report their controlled substances transactions to the Drug Enforcement Administration (DEA). Data Commons includes quarterly retail drug distributions from ARCOS Report 1, provided annually from 2006-2017. The 3-digit zip prefixes from the report were aggregated to the county level using 2010 ZIP Code Tabulation Area (ZCTA) Relationship records from the US Census. Please see the disclaimers page about the scope of the data.
The World Health Organization publishes national COVID-19 cases and death counts for countries across the world. Data Commons imports this data on a daily basis.
The American Community Survey covers a broad range of topics about social, economic, demographic, and housing characteristics of the U.S. population. The ACS 5-year (and 1-year) estimates are updated every year, based on the last 5 years (1 year) of collected data. Data Commons includes thousands of variables across the full range of ACS topics at the country, state, county, city, zip code tabulation area, school district, census tract levels, and more.
Basic population, race demographics and housing statistics from the redistricting data release of US Decennial Census mapped down to block-group level.
+U.S. Census Terms of Service.
Data in the Data Commons Graph comes from a variety of sources, each of which often includes multiple surveys. Some sources/surveys include a very large number of variables, some of which might not yet have been imported into Data Commons. The sources have been grouped by category and are listed alphabetically within each category.
The following charts illustrate the data coverage in terms of global statistical variables at the country, state, and district levels. The first chart illustrates the total number of statistical variables available per country, excluding the USA where data coverage is currently most extensive
+
+
+
+
+
+
This chart goes a level deeper and illustrates the total number of statistical variables available at the state level for each country worldwide.
+
+
+
+
+
Finally, this third chart illustrates the total number of statistical variables available at the district/county level worldwide.
+
+
+
+
+
+
+
+
+
diff --git a/datasets/international.html b/datasets/international.html
new file mode 100644
index 000000000..6af0d0f19
--- /dev/null
+++ b/datasets/international.html
@@ -0,0 +1,14 @@
+
+
+
+
+
+
+ Page Redirection
+
+
+ The content has moved. If you are not redirected automatically, please follow this link.
+
+
diff --git a/datasets/sustainability.html b/datasets/sustainability.html
new file mode 100644
index 000000000..6af0d0f19
--- /dev/null
+++ b/datasets/sustainability.html
@@ -0,0 +1,14 @@
+
+
+
+
+
+
+ Page Redirection
+
+
+ The content has moved. If you are not redirected automatically, please follow this link.
+
+
diff --git a/datasets/united_states.html b/datasets/united_states.html
new file mode 100644
index 000000000..6af0d0f19
--- /dev/null
+++ b/datasets/united_states.html
@@ -0,0 +1,14 @@
+
+
+
+
+
+
+ Page Redirection
+
+
+ The content has moved. If you are not redirected automatically, please follow this link.
+
+
diff --git a/feed.xml b/feed.xml
new file mode 100644
index 000000000..327ccd1a3
--- /dev/null
+++ b/feed.xml
@@ -0,0 +1,153 @@
+Jekyll2025-01-14T23:42:01+00:00https://docs.datacommons.org/feed.xmlData Commons DocsData Commons DocumentationData Commons’ New Natural Language Interface2023-09-13T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2023/09/13/explore<p>Data Commons is now harnessing the power of AI, specifically large language models (LLMs), to create a natural language interface. LLMs are used to understand the query and the results come straight from Data Commons, including a link to the original data source.</p>
+
+<p>Learn more in our <a href="https://blog.google/technology/ai/google-data-commons-ai/">Keyword blog post</a>.</p>R.V.GuhaData Commons is now harnessing the power of AI, specifically large language models (LLMs), to create a natural language interface. LLMs are used to understand the query and the results come straight from Data Commons, including a link to the original data source.New Courseware - Data Literacy with Data Commons2022-12-28T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2022/12/28/courseware<h3 id="tldr">tl;dr</h3>
+
+<p>Today, we are announcing the open and public availability of “Data Literacy with Data Commons” which comprises curriculum/course materials for instructors, students and other practitioners working on or helping others become <em>data literate</em>. This includes detailed modules with pedagogical narratives, explanations of key concepts, examples, and suggestions for exercises/projects focused on advancing the <em>consumption</em>, <em>understanding</em> and <em>interpretation</em> of data in the contemporary world. In our quest to expand the reach and utility of this material, we assume no background in computer science or programming, thereby removing a key obstacle to many such endeavors.</p>
+
+<p>This material can be accessed on our <a href="/courseware/data_literacy/course_materials/">courseware page</a> and it is open for anyone to take advantage of. If you use any of this material, we would love to hear from you! If you end up finding any of this material useful and would like to be notified of updates, do <a href="https://docs.google.com/forms/d/e/1FAIpQLSeVCR95YOZ56ABsPwdH1tPAjjIeVDtisLF-8oDYlOxYmNZ7LQ/viewform">drop us a line</a>.</p>
+
+<h3 id="what-is-it">What is it?</h3>
+
+<p>A set of <a href="/courseware/data_literacy/course_materials/modules.html">modules</a> focusing on several <a href="/courseware/data_literacy/course_materials/key_themes.html">key concepts</a> focusing on data modeling, analysis, visualization and the (ab)use of data to tell (false) narratives. Each module lists its objectives and builds on a pedagogical narrative around the explanation of key concepts, e.g. the differences between correlations and causation. We extensively use the Data Commons platform to point to <em>real world</em> examples without needing to write a single line of code!</p>
+
+<h3 id="who-is-this-for">Who is this for?</h3>
+
+<p>Anyone and everyone. Instructors, students, aspiring data scientists and anyone interested in advancing their data comprehension and analysis skills without needing to code. For instructors, the <a href="/courseware/data_literacy/course_materials/">curriculum page</a> details the curriculum organization and how to find key concepts/ideas to use.</p>
+
+<h3 id="whats-different">What’s Different?</h3>
+
+<p>There are several excellent courses which range from basic data analysis to advanced data science. We make no claim about “Data Literacy with Data Commons” being a replacement for them. Instead, we hope for this curriculum to become a useful starting point for those who want to whet their appetite in becoming data literate. This material uses a hands on approach, replete with <em>real world</em> examples but without requiring any programming. It also assumes only a high-school level of comfort with math and statistics. Data Commons is a natural companion platform to enable easy access to data and core visualizations. We hope that anyone exploring the suggested examples will rapidly be able to explore more and even generate new examples and case studies on their own! If you end up finding and exploring new examples and case studies, please <a href="https://docs.google.com/forms/d/e/1FAIpQLScJTtNlIItT-uSPXI98WT6yNlavF-kf5JS0jMrCvJ9TPLmelg/viewform">share them with us through this form</a>.</p>
+
+<h3 id="what-is-data-literacy">What is Data Literacy?</h3>
+
+<p>What does it mean to be “data literate”? Unsurprisingly, the answer depends on who one asks: from those who believe it implies being a casual consumer of data visualizations (in the media, for example) to those who believe that such a person ought to be able to run linear regressions on large volumes of data in a spreadsheet. Given that most (or all) of us are proliferate <em>consumers</em> of data, we take an opinionated approach to defining “data literacy”: someone who is data literate ought to be comfortable with <em>consuming</em> data across a wide range of modalities and be able to interpret it to make informed decisions. And we believe that data literacy ought not to be exclusionary and should be accessible to anyone and everyone.</p>
+
+<p>There is no shortage of data all around us. While some of it will always be beyond the comprehension of most of us, e.g. advanced clinical trials data about new drugs under development or data reporting the inner workings of complex systems like satellites, much of the data we consume is not as complex and should not need advanced degrees to consume and decipher. For example, the promise of hundreds of dollars in savings when switching insurance providers or that nine out of ten dentists recommend a particular brand of toothpaste or that different segments of the society (men, women, youth, veterans etc) tend to vote a certain way on specific issues. We <em>consume</em> this data regularly and being able to interpret it to draw sound conclusions ought not to require advanced statistics.</p>
+
+<p>Unfortunately, data literacy has been an elusive goal for many because it has been gated on relative comfort with programming or programming-like skills, e.g. spreadsheets. We believe data literacy should be more inclusive and require fewer prerequisites. There is no hiding from a basic familiarity with statistics, e.g. knowing how to take a sample average—after all, interpreting data is a sStatistical exercise. However, for a large majority of us the consumption, interpretation and decision-making based on data does not need a working knowledge of computer science (programming).</p>
+
+<p>As a summary, our view on “Data Literacy” can be described as follows:</p>
+
+<ul>
+ <li>Ability to consume, understand, create, and communicate with data.</li>
+ <li>Ability to make decisions based on data.</li>
+ <li>And to do so confidently, i.e. reduce “data anxiety”.</li>
+ <li>A skill for everyone, not just “data scientists”.</li>
+</ul>
+
+<p>With these goals in mind, we hope that this introductory curriculum can help the target audiences towards achieving data literacy and inspire many to dive deeper and farther to become data analysts and scientists.</p>
+
+<p>Crystal, Jehangir, and Julia, on behalf of the Data Commons team</p>Crystal Wang, Jehangir Amjad, and Julia Wutl;drNew Data Download Tool2022-09-14T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2022/09/14/download-tool<p>In the last year, we have added several interesting datasets and exciting new features to Data Commons. One such feature is the new <a href="https://datacommons.org/tools/download">Data Download tool</a> that allows you to easily download statistical variable data for a large number of places with just a few button clicks.</p>
+
+<p><img src="/assets/images/posts/download_tool.png" alt="The new data download tool" /></p>
+
+<p>The Data Commons knowledge graph is huge – there are over 240B data points for over 120K statistical variables. Sometimes, you may want to export just some of this data and use it in a custom tool. We now make that easy to do with the new data download tool. The new tool gives you the data in a csv file, does not require any coding experience to use, and allows you to select the statistical variables, places, and dates that you are interested in.</p>
+
+<p>Maybe you want to explore the population of all the countries in the world (get the data <a href="https://datacommons.org/tools/download#pt=Country&place=Earth&sv=Count_Person&dtType=LATEST&facets=%7B%7D">here</a>). Or you want to analyze poverty levels during COVID-19 (get the data <a href="https://datacommons.org/tools/download#pt=State&place=country%2FUSA&sv=Count_Person_BelowPovertyLevelInThePast12Months__CumulativeCount_MedicalConditionIncident_COVID_19_ConfirmedOrProbableCase&dtType=RANGE&facets=%7B%7D&dtMin=2020&dtMax=2021">here</a>). Or you’re interested in projected temperature differences (relative to 2006) and activities that can be affected by temperature rise (get the data <a href="https://datacommons.org/tools/download#pt=County&place=country%2FUSA&sv=DifferenceRelativeToBaseDate2006_Max_Temperature_RCP45__Percent_Person_WithCoronaryHeartDisease__WithdrawalRate_Water__Area_Farm_IrrigatedLand&dtType=LATEST&facets=%7B%7D">here</a>). The Data Download tool gives you the power to use the data in our knowledge graph to explore all of this and much more in your tool of choice.</p>
+
+<p>As always, we would love to hear from you! Please share your <a href="https://datacommons.org/feedback">feedback</a> with our team.</p>
+
+<p>Jennifer on behalf of the Data Commons team</p>Jennifer ChenIn the last year, we have added several interesting datasets and exciting new features to Data Commons. One such feature is the new Data Download tool that allows you to easily download statistical variable data for a large number of places with just a few button clicks.Sustainability Data Commons2022-04-22T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2022/04/22/earth-day<p>Data Commons now includes <a href="https://docs.datacommons.org/datasets/">100+ sources of Sustainability data</a>, covering topics from climate predictions (CMIP 5 and CMIP 6) from NASA, emissions from EPA, energy from EIA, NREL and UN, disasters from USGS and USFS, health from CDC and <a href="https://docs.datacommons.org/datasets/">more</a>. You can learn more about the launch of Sustainability Data Commons on the <a href="https://blog.google/outreach-initiatives/sustainability/data-commons-sustainability/">Google Keyword Blog</a>.</p>
+
+<p>As always, we are eager to hear your <a href="https://datacommons.org/feedback">feedback</a>.</p>
+
+<p>Jennifer on behalf of the Data Commons team</p>Jennifer ChenData Commons now includes 100+ sources of Sustainability data, covering topics from climate predictions (CMIP 5 and CMIP 6) from NASA, emissions from EPA, energy from EIA, NREL and UN, disasters from USGS and USFS, health from CDC and more. You can learn more about the launch of Sustainability Data Commons on the Google Keyword Blog.Data Commons Updates2021-10-10T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2021/10/10/updates<p>Over the past few months, we’ve continued to incorporate new data into our knowledge graph and develop new tools. Here are some of the highlights:</p>
+
+<h3 id="new-statistical-variable-explorer">New Statistical Variable Explorer</h3>
+<p>As Data Commons has grown, the number of <a href="https://docs.datacommons.org/glossary.html">Statistical Variables</a> has increased. With over 300k variables to choose from (and counting!), we wanted to make it easier for you to find the right variables for your analysis. To address this, we added a new <a href="https://datacommons.org/tools/statvar">tool for exploring Statistical Variables</a>. The tool provides metadata about the observations, places, and provenances we have for each variable.</p>
+
+<h3 id="new-data">New Data</h3>
+<p>Lately, we’ve been focused on building up our inventory of sustainability-related data. Some of recent our imports include:</p>
+<ul>
+ <li>Several of the IPCC RCP scenarios (e.g. <a href="https://datacommons.org/tools/map#%26sv%3DDaily_Max_Temperature_RCP85%26pc%3D0%26pd%3Dcountry%2FUSA%26pn%3DUnited%20States%20of%20America%26pt%3DCountry%26ept%3DCounty">Max Daily Temperature Based on RCP 8.5</a> in the US)</li>
+ <li>WHO’s Global Health Observatory (e.g. <a href="https://datacommons.org/tools/timeline#statsVar=WHO%2FNCD_BMI_30A_Female&place=country%2FUSA">Prevalence (%) of females in the US with BMI of 30 or greater</a>, <a href="https://datacommons.org/tools/timeline#statsVar=WHO%2FWSH_WATER_BASIC_Rural&place=country%2FZAF">Percent of rural population in South Africa with at least basic drinking water services</a>, and <a href="https://datacommons.org/tools/timeline#statsVar=WHO%2FFINPROTECTION_CATA_TOT_10_POP_Urban&place=country%2FUSA">Percent of urban population in the US with household expenditures on health greater than 10% of total household expenditure or income</a>)</li>
+ <li>UN’s Energy Statistics Database (e.g. <a href="https://datacommons.org/tools/timeline#statsVar=Annual_Generation_Energy_Coal&place=country%2FUSA">Annual Generation of Coal</a> in the US)</li>
+ <li>EPA’s Greenhouse Gas Reporting Program (e.g. Greenhouse Gas emissions from large facilities in <a href="https://datacommons.org/browser/geoId/06085?statVar=Annual_Emissions_GreenhouseGas_NonBiogenic">Santa Clara County</a>, and <a href="https://datacommons.org/browser/geoId/06?statVar=Annual_Emissions_GreenhouseGas_NonBiogenic">California</a>, as well as EPA reporting facilities such as <a href="https://datacommons.org/browser/epaGhgrpFacilityId/1002576">Anheuser Busch Baldwinsville Brewery</a> and <a href="https://datacommons.org/browser/epaGhgrpFacilityId/1002004">Glen Burnie Landfill</a>)</li>
+ <li>Stanford’s DeepSolar (e.g. <a href="https://datacommons.org/tools/map#%26sv%3DCount_SolarInstallation%26pc%3D1%26pd%3DgeoId%2F06%26pn%3DCalifornia%26pt%3DState%26ept%3DCounty">Count of Solar Installation</a> per capita in California)</li>
+</ul>
+
+<p>We’re also in the process of importing a large number of US Census American Community Survey Subject Tables, which contain detailed demographic data about a variety of topics. For example:</p>
+<ul>
+ <li><a href="https://datacommons.org/tools/map#%26sv%3DCount_Household_WithFoodStampsInThePast12Months_BelowPovertyLevelInThePast12Months%26pc%3D1%26pd%3Dcountry%2FUSA%26pn%3DUnited%20States%20of%20America%26pt%3DCountry%26ept%3DCounty">Count of With Food Stamps in The Past 12 Months, Below Poverty Level in The Past 12 Months</a> per capita</li>
+ <li><a href="https://datacommons.org/tools/map#%26sv%3DCount_Household_HouseholderEducationalAttainmentSomeCollegeOrAssociatesDegree_SingleMotherFamilyHousehold%26pc%3D0%26pd%3Dcountry%2FUSA%26pn%3DUnited%20States%20of%20America%26pt%3DCountry%26ept%3DCounty">Count of Single Mother Family Household, Some College or Associate’s Degree</a></li>
+</ul>
+
+<h3 id="new-import-tool">New Import Tool</h3>
+<p>We’ve made it easier for contributors to add datasets to Data Commons with our new open source command-line tool. This tool provides linting and detailed stats validation, streamlining our data ingestion process and making it more accessible.</p>
+
+<p>Check out our Github repo <a href="https://github.com/datacommonsorg/import">here</a>.</p>
+
+<p>As always, please feel free to share any <a href="https://datacommons.org/feedback">feedback</a>.</p>
+
+<p>Thanks!</p>
+
+<p>Natalie on behalf of the Data Commons team</p>Natalie DiazOver the past few months, we’ve continued to incorporate new data into our knowledge graph and develop new tools. Here are some of the highlights:Data Commons Updates2021-06-01T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2021/06/01/updates<p>We’ve been hard at work since we <a href="https://docs.datacommons.org/2020/10/15/search_launch.html">surfaced Data Commons in Google Search</a> last October. Some of the exciting features we’ve added include:</p>
+
+<h3 id="internationalization-support">Internationalization Support</h3>
+
+<p>Place Explorer is now available in 8 languages in addition to English: <a href="https://datacommons.org/place/country/DEU?hl=de">German</a>, <a href="https://datacommons.org/place/country/MEX?hl=es">Spanish</a>, <a href="https://datacommons.org/place/country/FRA?hl=fr">French</a>, <a href="https://datacommons.org/place/country/IND?hl=hi">Hindi</a>, <a href="https://datacommons.org/place/country/ITA?hl=it">Italian</a>, <a href="https://datacommons.org/place/country/JPN?hl=ja">Japanese</a>, <a href="https://datacommons.org/place/country/KOR?hl=ko">Korean</a> and <a href="https://datacommons.org/place/country/RUS?hl=ru">Russian</a>. Additionally, support for these languages are carried forward from Google Search, <a href="https://www.google.com/search?hl=es&q=Poblaci%C3%B3n+de+M%C3%A9xico">here’s an example</a>.</p>
+
+<h3 id="new-graph-browser">New Graph Browser</h3>
+
+<p>The <a href="https://datacommons.org/browser">Graph Browser</a> was rewritten from the ground up to be faster and more responsive. It includes search support for the growing number of <a href="https://github.com/datacommonsorg/data/blob/master/docs/representing_statistics.md#intro-to-statisticalvariable-and-statvarobservation">Statistical Variables</a> available for each node, as well as redesigned to improve information density. Try it out for some nodes such as <a href="https://datacommons.org/browser/country/IND">India</a>, <a href="https://datacommons.org/browser/geoId/2507000?statVar=UnemploymentRate_Person">Unemployment Rate in Boston</a> and <a href="https://datacommons.org/browser/dc/m28y35mxfwsdb">Renal Cell Carcinoma</a>.</p>
+
+<h3 id="new-scatter-plot-explorer">New Scatter Plot Explorer</h3>
+
+<p>The new <a href="https://datacommons.org/tools/scatter">Scatter Plot Explorer</a> enables quick visual exploration of any two statistical variables for a set of places. Try it out for <a href="https://datacommons.org/tools/scatter#%26svx%3DCount_Person_Female%26svpx%3D0-8-0%26svdx%3DCount_Person%26svnx%3DFemale%26pcx%3D1%26svy%3DCount_Person_EducationalAttainmentBachelorsDegree%26svpy%3D2-0-6%26svdy%3DCount_Person_25OrMoreYears%26svny%3DBachelors_Degree%26pcy%3D1%26epd%3DgeoId%2F06%26epn%3DCalifornia%26ept%3DCounty">Bachelor Degree Attainment vs Females per capita in California Counties</a> or <a href="https://datacommons.org/tools/scatter#%26svx%3DCount_Person_BlackOrAfricanAmericanAlone%26svpx%3D0-14-2%26svdx%3DCount_Person%26svnx%3DBlack_Or_African_American_Alone%26pcx%3D1%26svy%3DCumulativeCount_MedicalTest_ConditionCOVID_19_Positive%26svpy%3D5-2-0-1%26svdy%3DCount_Person%26svny%3DPositive%26pcy%3D1%26epd%3Dcountry%2FUSA%26epn%3DUnited%20States%20of%20America%26ept%3DState">Covid-19 cases vs African Americans per capita among US States</a>.</p>
+
+<h3 id="api-documentation-refresh">API Documentation Refresh</h3>
+
+<p>We participated in the <a href="https://developers.google.com/season-of-docs/docs/2020/participants/project-datacommons-kilimannejaro">2020 Season of Docs</a>, working with Anne Ulrich (<a href="https://gist.github.com/KilimAnnejaro">@KilimAnnejaro</a>) to completely <a href="https://gist.github.com/KilimAnnejaro/722b353875241131b15866e0cf4ab7ea">refresh and improve our API documentation</a>. Every API page was rewritten, in addition to <a href="https://docs.datacommons.org/tutorials/">new Google Sheets API tutorials</a>. We had a wonderful time collaborating with Anne on this project and hope the improved documentation enables more developers to harness the power of our APIs.</p>
+
+<h3 id="new-stats-api">New Stats API</h3>
+
+<p>We have also released a new set of APIs centered around statistics retrieval. There are different REST endpoints to retrieve <a href="https://docs.datacommons.org/api/rest/stat_value.html">a single statistical value</a>, <a href="https://docs.datacommons.org/api/rest/stat_series.html">a statistical time series</a> or <a href="https://docs.datacommons.org/api/rest/stat_all.html">the entire collection of statistical data for a set of places</a>. We have used these APIs to build the new Scatter Plot Explorer and hope this enables other applications too.</p>
+
+<h3 id="new-data">New Data</h3>
+
+<p>As always, we continue to add more data to the Data Commons Graph. Some recent additions include:</p>
+<ul>
+ <li>Indian Census (e.g. <a href="https://datacommons.org/browser/country/IND?statVar=Count_Household_Houseless_Rural">houseless</a> and <a href="https://datacommons.org/browser/wikidataId/Q15116?statVar=Count_Person_Literate_Rural">rural literacy</a> populations)</li>
+ <li>Reserve Bank of India’s Poverty data (e.g. <a href="https://datacommons.org/browser/wikidataId/Q1159?statVar=Count_Person_Rural_BelowPovertyLevelInThePast12Months">rural population below poverty in Andhra Pradesh</a>)</li>
+ <li>FDA and additional drug information (e.g. <a href="https://datacommons.org/browser/bio/CHEMBL512">drug</a> from FDA, ChEMBL, PharmGKB, etc.)</li>
+ <li>Improved Covid-19 statistics (e.g. <a href="https://datacommons.org/browser/country/IND?statVar=CumulativeCount_Vaccine_COVID_19_Administered">vaccination stats from ourworldindata.org</a>)</li>
+ <li>US Energy Information Administration (e.g. <a href="https://autopush.datacommons.org/browser/country/USA?statVar=Quarterly_Consumption_Coal_ElectricPower">coal</a> and <a href="https://autopush.datacommons.org/browser/country/USA?statVar=Quarterly_Consumption_Fuel_ForElectricityGeneration_NaturalGas">natural gas consumption</a> for electricity)</li>
+ <li>Expanded international data from World Bank (e.g., <a href="https://autopush.datacommons.org/browser/country/CHN?statVar=Count_CriminalActivities_MurderAndNonNegligentManslaughter_AsFractionOf_Count_Person">crime</a>, <a href="https://autopush.datacommons.org/browser/country/IND?statVar=Count_Person_15OrMoreYears_Smoking_AsFractionOf_Count_Person_15OrMoreYears">health</a><a href="https://autopush.datacommons.org/browser/country/IND?statVar=Count_Person_Upto4Years_Overweight_AsFractionOf_Count_Person_Upto4Years">stats</a>)</li>
+ <li>Updated data from existing sources, including:
+ <ul>
+ <li>FBI Crime (till <a href="https://datacommons.org/browser/geoId/06?statVar=Count_CriminalActivities_ViolentCrime">2019</a>)</li>
+ <li>BLS Unemployment (till <a href="https://datacommons.org/browser/geoId/06?statVar=UnemploymentRate_Person">2021 Q1</a>)</li>
+ <li>World Bank (till <a href="https://www.google.com/search?q=population+of+china&oq=population+of+china">2019</a>)</li>
+ </ul>
+ </li>
+</ul>
+
+<p>As always, we are eager to hear from you! Please <a href="https://datacommons.org/feedback">share your feedback</a> with our team.</p>
+
+<p>Carolyn on behalf of the Data Commons team</p>Carolyn AuWe’ve been hard at work since we surfaced Data Commons in Google Search last October. Some of the exciting features we’ve added include:Data Commons, now accessible on Google Search2020-10-15T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2020/10/15/search_launch<p>Today, we are excited to share that <a href="https://blog.google/products/search/search-on/">Data Commons is accessible via natural language queries in Google search</a>. At a time when data informs our understanding of so many issues–from public health and education to the evolving workforce and more–access to data has never been more important. Data Commons in Google search is a step in this direction, enabling users to explore data without the need for expertise or programming skills.</p>
+
+<p>Three years ago, the Data Commons journey started at Google with a simple observation: our ability to use data to understand our world is frequently hampered by the difficulties in working with data. The difficulties of finding, cleaning and joining <a href="https://datacommons.org/datasets">datasets</a> effectively limit who gets to work with data.</p>
+
+<p>Data Commons addresses this challenge head on, performing the tedious tasks of curating, joining and cleaning data sets at scale so that data users don’t have to. The result? Large scale and cloud accessible APIs to clean and normalize data originating from some of the most widely used datasets, including those from the US Census, World Bank, CDC and more. Available as a layer on top of the Knowledge Graph, Data Commons is now accessible to a much wider audience.</p>
+
+<p>Data Commons is Open. Open Data, Open Source. We hope that like its elder sister Schema.org, it becomes one of the foundational layers of the Web. We know this can only happen if it is built in an open and collaborative fashion. We are actively looking for partnerships on every aspect of this project, and we look forward to <a href="https://datacommons.org/feedback">hearing</a> from you!</p>
+
+<p>R.V.Guha & the Data Commons team</p>R.V.GuhaToday, we are excited to share that Data Commons is accessible via natural language queries in Google search. At a time when data informs our understanding of so many issues–from public health and education to the evolving workforce and more–access to data has never been more important. Data Commons in Google search is a step in this direction, enabling users to explore data without the need for expertise or programming skills.Data Commons Updates2020-07-26T00:00:00+00:002025-01-14T23:38:52+00:00https://docs.datacommons.org/2020/07/26/updates<p>Over the last month and a half, we have worked hard to add some exciting new features:</p>
+
+<h3 id="new-map-explorer">New Map Explorer</h3>
+<p>The new <a href="http://datacommons.org/tools/map">Map Explorer</a> offers an easy way to visualize how a statistical variable can vary across geographic regions. Try it out for <a href="https://datacommons.org/tools/map#&sv=Count_Person_EducationalAttainmentBachelorsDegreeOrHigher&pc=1&pd=geoId/53&pn=Washington&pt=State&ept=County">Attainment of Bachelor Degree or Higher across Washington Counties</a> or <a href="https://datacommons.org/tools/map#&sv=Median_Income_Person&pc=0&pd=country/USA&pn=United%20States%20of%20America&pt=Country&ept=State">Median Income across US States</a>.</p>
+
+<h3 id="new-statistical-variable-menu">New Statistical Variable Menu</h3>
+<p>The Statistical Variable Menu used for the <a href="http://datacommons.org/tools/scatter">Scatter Plot Explorer</a>, <a href="http://datacommons.org/tools/timeline">Timelines Explorer</a>, and <a href="http://datacommons.org/tools/map">Map Explorer</a> was revamped to serve a much more comprehensive list of over 287000 statistical variables in an easy to consume way. This new menu comes with useful features such as search support and information on the places that each statistical variable has data for.</p>
+
+<h3 id="new-data">New Data</h3>
+<p>We’ve continued to add new data to the Data Commons graph. Some of these new additions include:</p>
+<ul>
+ <li>Air quality data from US Environmental Protection Agency (eg. <a href="http://datacommons.org/browser/geoId/01049?statVar=AirQualityIndex_AirPollutant">Overall Air Quality Index</a>)</li>
+ <li>India wages data from Indian Periodic Labour Force Survey (eg. mean daily wages for <a href="http://datacommons.org/tools/timeline#place=country%2FIND&statsVar=Mean_WagesDaily_Worker_Urban">urban workers</a> and <a href="http://datacommons.org/tools/timeline#place=country%2FIND&statsVar=Mean_WagesDaily_Worker_Rural">rural workers</a>)</li>
+ <li>India unemployment rate data from Reserve Bank of India (eg. unemployment rate amongst <a href="http://datacommons.org/tools/timeline#place=country%2FIND&statsVar=UnemploymentRate_Person_Urban">urban residents</a> and <a href="http://datacommons.org/tools/timeline#place=country%2FIND&statsVar=UnemploymentRate_Person_Rural">rural residents</a>)</li>
+</ul>
+
+<p>We would love to <a href="https://datacommons.org/feedback">hear any feedback</a> you may have!</p>
+
+<p>Jennifer on behalf of the Data Commons team</p>Jennifer ChenOver the last month and a half, we have worked hard to add some exciting new features:
\ No newline at end of file
diff --git a/glossary.html b/glossary.html
new file mode 100644
index 000000000..f4e75b472
--- /dev/null
+++ b/glossary.html
@@ -0,0 +1,670 @@
+
+
+
+
+ Glossary - Docs - Data Commons
+
+
+
+
+
+
+
+
+
+
+
+
+
The date of measurement. Specified in ISO 8601 format. Examples include 2011 (the year 2011), 2019-06 (the month of June in the year 2019), and 2019-06-05T17:21:00-06:00 (5:17PM on June 5, 2019, in CST).
+
+
DCID
+
+
Every entity in the Data Commons graph has a unique identifier, called “DCID” (short for “Data Commons Identifier”). So, for example, the DCID of California is geoId/06 and of India is country/IND. DCIDs are not restricted to entities; every node in the graph has a DCID. Statistical variables have DCID, for example the DCID for the Gini Index of Economic Activity is GiniIndex_EconomicActivity.
+
+
To find a DCID for an entity or variable, see the Key concepts page.
+
+
Entity
+
+
An entity represented by a node in the Data Commons knowledge graph. These can represent a wide range of concepts, including cities, countries, elections, schools, plants, or even the Earth itself.
+
+
Facet
+
+
Metadata on properties of the data and its provenance. For example, multiple sources might provide data on the same variable, but use different measurement methods, cover data spanning different time spans, or use different underlying predictive models. Data Commons uses “facet” to refer to a data’s source and its associated metadata.
The technique used for measuring a variable. Describes how a measurement is made, whether by count or estimate or some other approach. May name the group making the measurement to indicate a certain organizational method of measurement is used. Examples include the American Community Survey and WorldHealthOrganizationEstimates. Multiple measurement methods may be specified for any given node.
A measurement of a variable for a particular place and time. For example, a StatVarObservation of the StatisticalVariableMedian_Income_Person for Brookmont, Maryland, in the year 2018 would be $126,199. A complete list of properties of statistical variable observations can be found in the Knowledge Graph.
Entities that describe specific geographic locations. Use the search box in Place Explorer to search for places in the graph, or view the Knowledge Graph entry for Place for a full view of the node. To learn more about place types, take a look at the place types page.
+
+
Preferred Facet
+
+
When a variable has values from multiple facets, one facet is designated the preferred facet. The preferred facet is selected by an internal ranking system which prioritizes the completeness and quality of the data. Unless otherwise specified, endpoints will default to returning values from preferred facets.
+
+
Property
+
+
Attributes of the entities in the Data Common knowledge graph. Instead of statistical values, properties describe unchanging characteristics of entities, like scientific name.
Property of variables that measure proportions, used in conjunction with the measurementDenominator property to indicate the multiplication factor applied to the proportion’s denominator (with the measurement value as the final result of the multiplication) when the numerator and denominator are not equal.
+
+
As an example, in 1999, approximately 36% of Canadians were Internet users. Here the measured value of Count_Person_IsInternetUser_PerCapita is 36, and the scaling factor or denominator for this per capita measurement is 100. Without the scaling factor, we would interpret the value to be 36/1, or 3600%.



















































































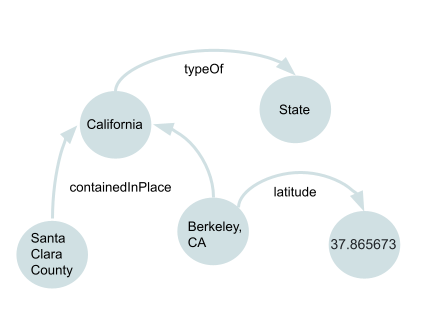
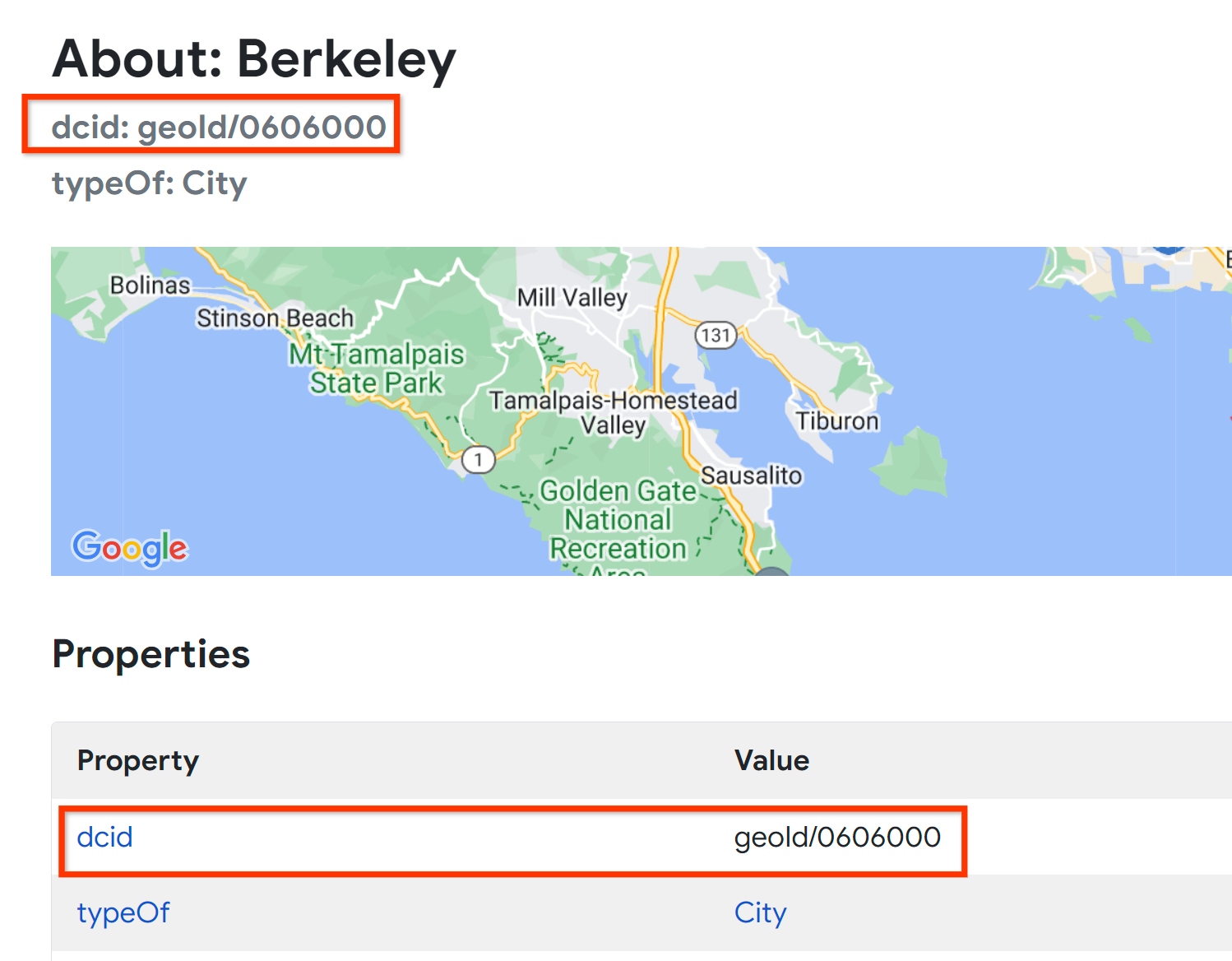
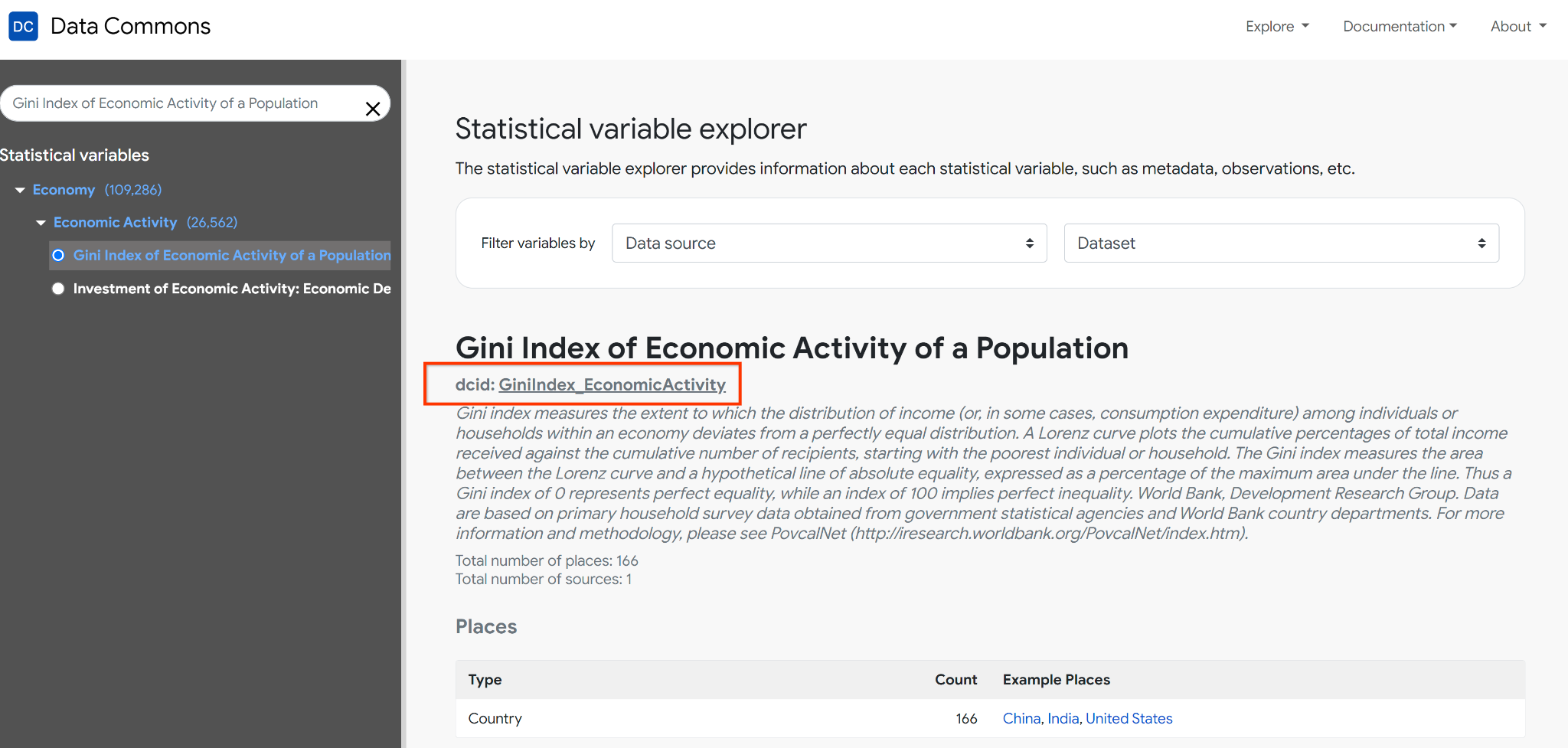
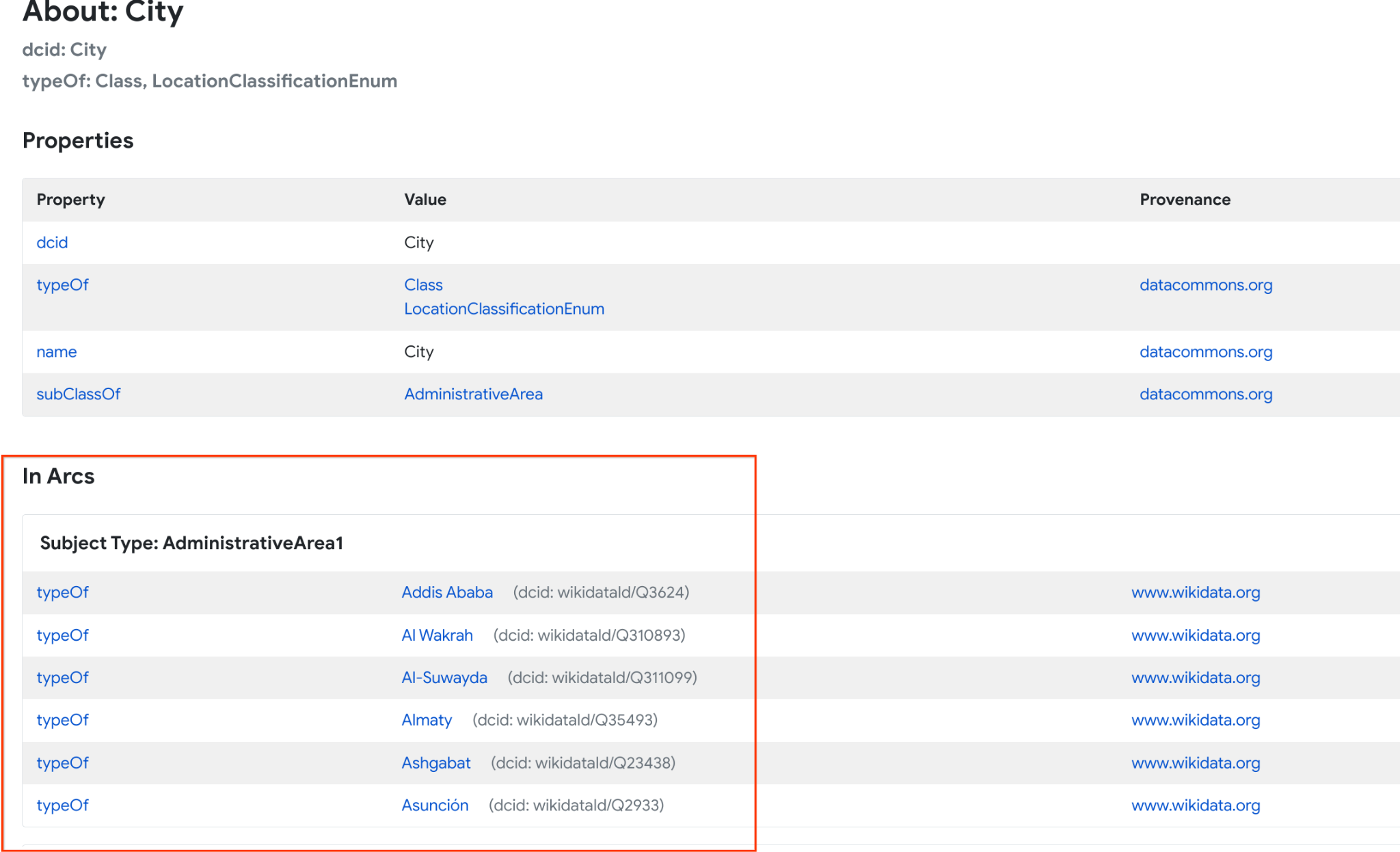
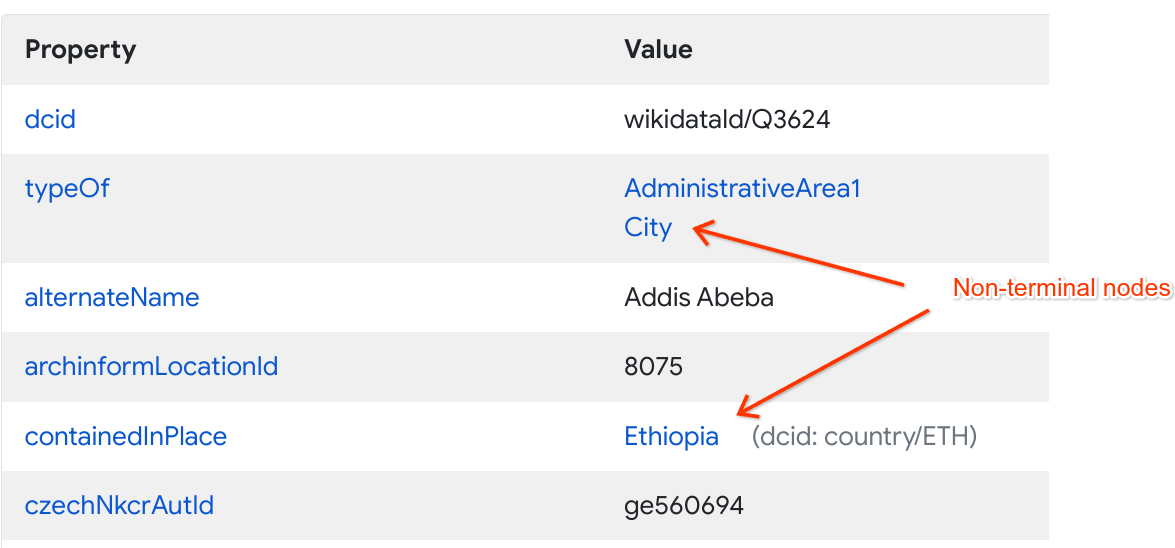
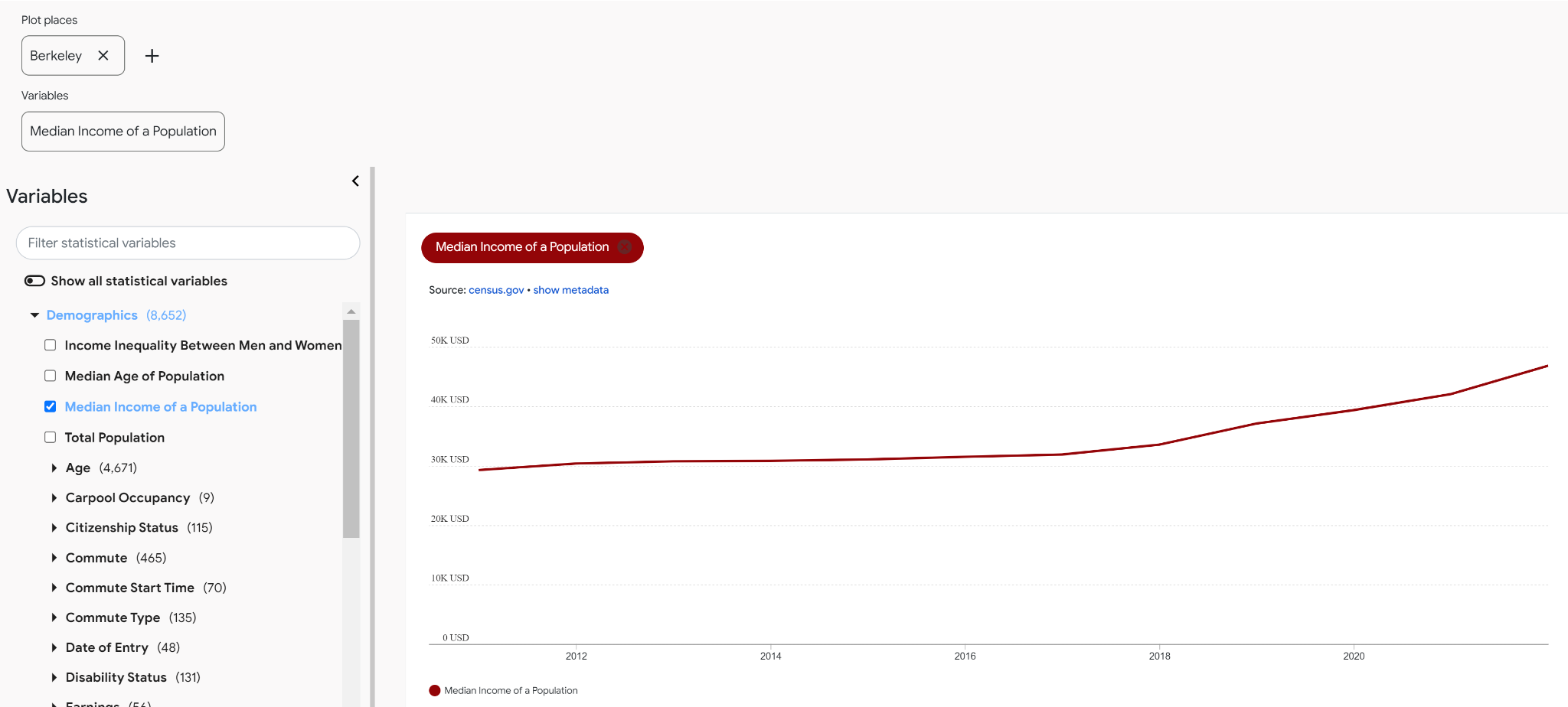
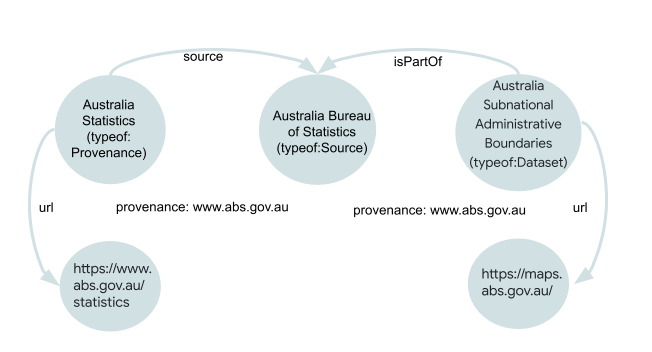
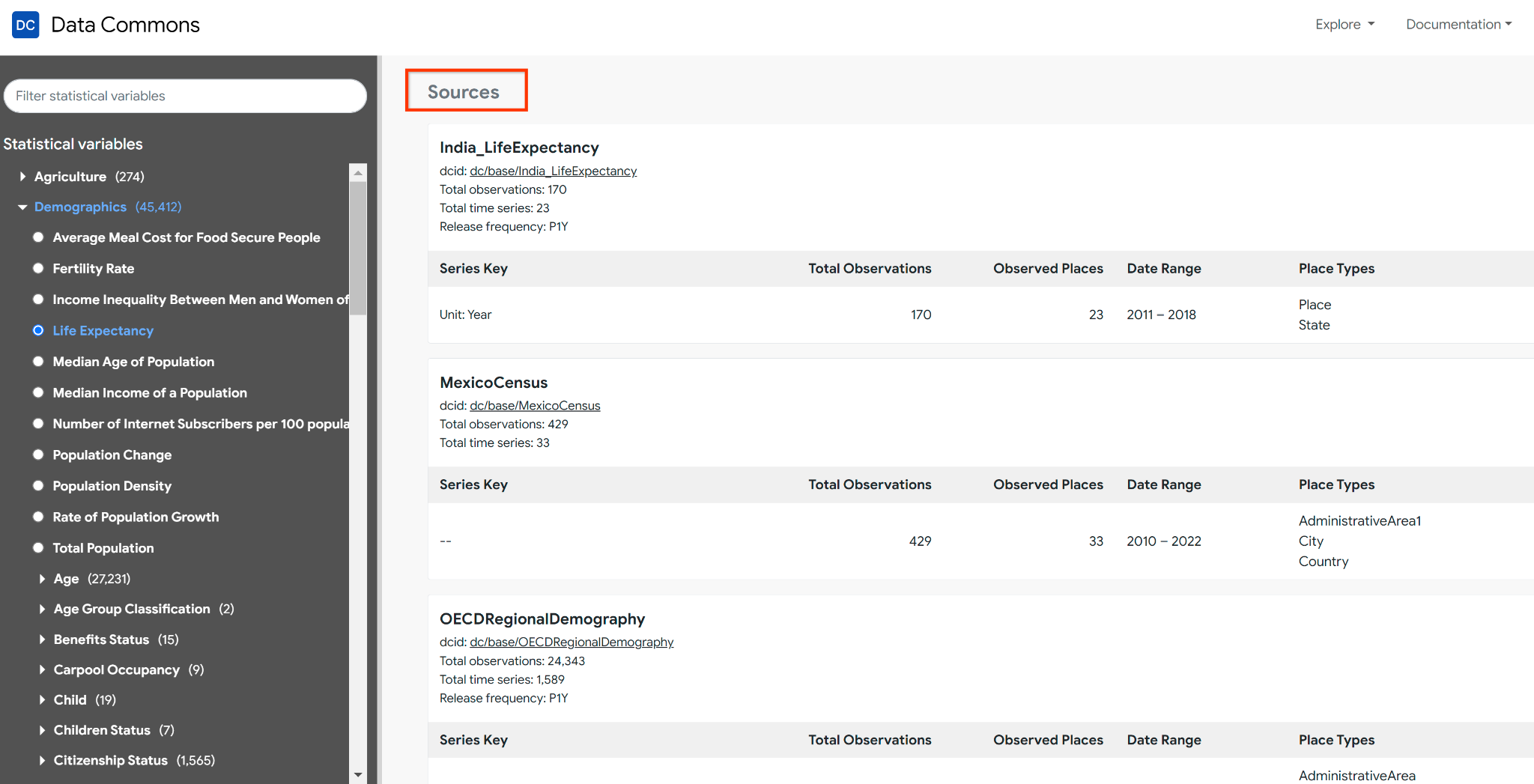
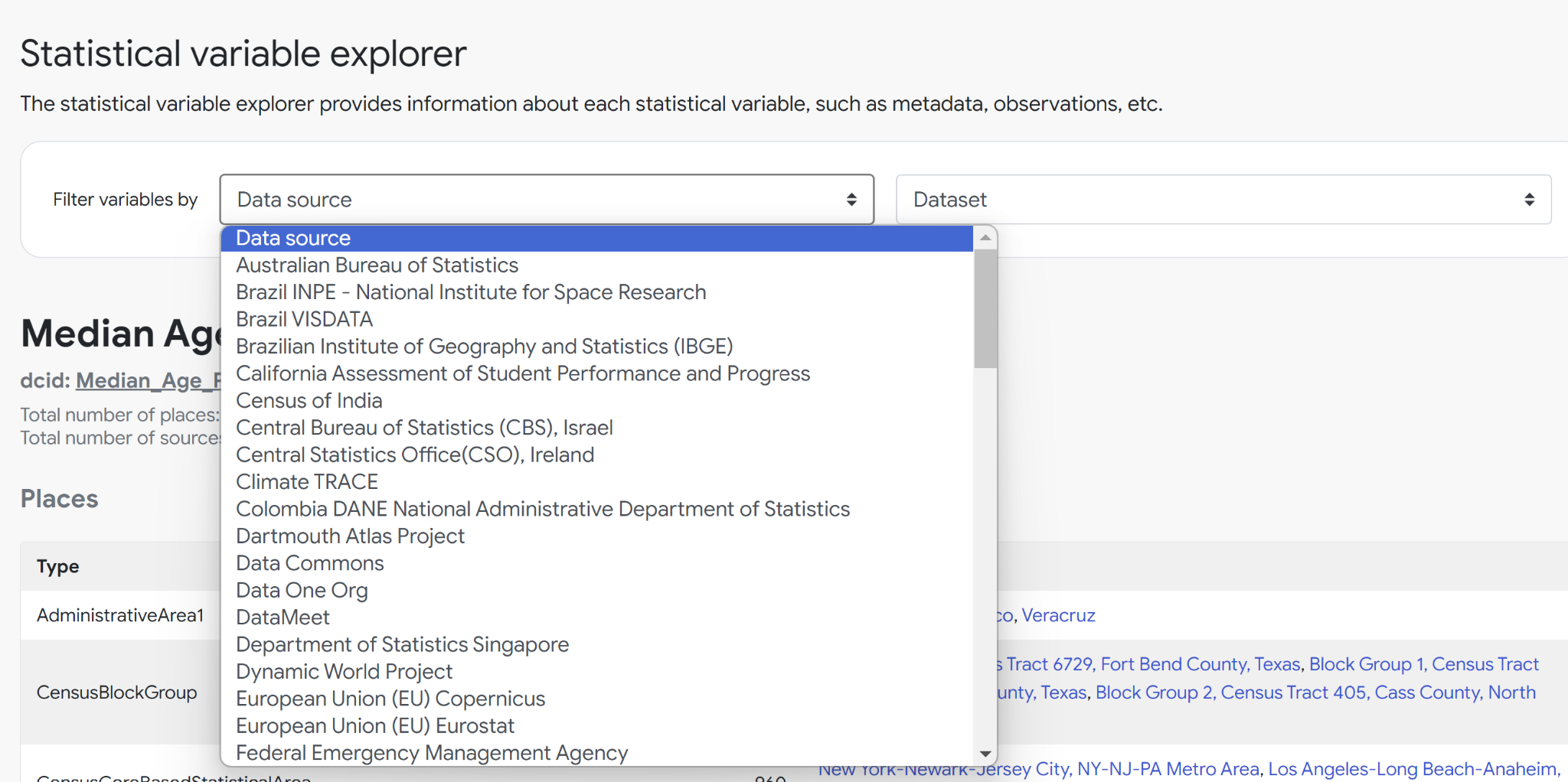
{kind=link}