You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
I've been experimenting with XTTS V2 fine-tuning, and I'm simply curious as to when the fine-tuning becomes sufficient. Most people seem to only be training their fine-tunes for 10 or so epochs while others train for thousands. Every top article online says why fine-tuning is important, what its benefits are, blah blah blah. But none seem to address issues on what you need to fix once you start getting results.
From what I understand, I want to reach a state of convergence from the fine-tuning. What I have now shows that my learning rate is probably too high, as per this graphic:
I'd also think that my average loss should be decreasing and not increasing. Is there anywhere I'm wrong? For reference, I'm largely using the significant values from the Coqui XTTS V2 training script, such as the learning rate. Also, I have the initial sample_rate set to 48000 to match my dataset.
I also saw that Coqui "recommend(s) that BATCH_SIZE * GRAD_ACUMM_STEPS needs to be at least 252 for more efficient training," so what would be their recommended values?
reacted with thumbs up emoji reacted with thumbs down emoji reacted with laugh emoji reacted with hooray emoji reacted with confused emoji reacted with heart emoji reacted with rocket emoji reacted with eyes emoji
-
I've been experimenting with XTTS V2 fine-tuning, and I'm simply curious as to when the fine-tuning becomes sufficient. Most people seem to only be training their fine-tunes for 10 or so epochs while others train for thousands. Every top article online says why fine-tuning is important, what its benefits are, blah blah blah. But none seem to address issues on what you need to fix once you start getting results.
From what I understand, I want to reach a state of convergence from the fine-tuning. What I have now shows that my learning rate is probably too high, as per this graphic:
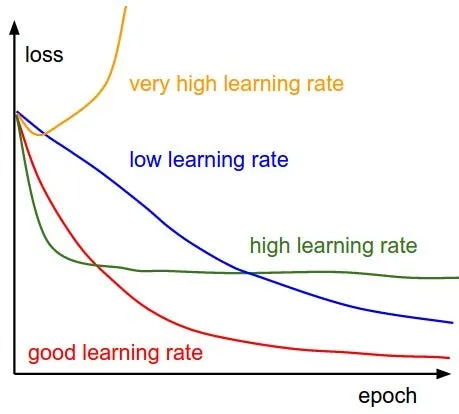
I'd also think that my average loss should be decreasing and not increasing. Is there anywhere I'm wrong? For reference, I'm largely using the significant values from the Coqui XTTS V2 training script, such as the learning rate. Also, I have the initial
sample_rateset to 48000 to match my dataset.I also saw that Coqui "recommend(s) that BATCH_SIZE * GRAD_ACUMM_STEPS needs to be at least 252 for more efficient training," so what would be their recommended values?
Beta Was this translation helpful? Give feedback.
All reactions