😊 EasyAnimateは、高解像度および長時間動画を生成するためのエンドツーエンドソリューションです。トランスフォーマーベースの拡散生成器をトレーニングし、長時間動画を処理するためのVAEをトレーニングし、メタデータを前処理することができます。
😊 DITをベースに、トランスフォーマーを拡散器として使用して動画や画像を生成します。
😊 ようこそ!
English | 简体中文 | 日本語
EasyAnimateは、トランスフォーマーアーキテクチャに基づいたパイプラインで、AI画像および動画の生成、Diffusion TransformerのベースラインモデルおよびLoraモデルのトレーニングに使用されます。事前トレーニング済みのEasyAnimateモデルから直接予測を行い、さまざまな解像度で約6秒間、8fpsの動画を生成できます(EasyAnimateV5、1〜49フレーム)。さらに、ユーザーは特定のスタイル変換のために独自のベースラインおよびLoraモデルをトレーニングできます。
異なるプラットフォームからのクイックプルアップをサポートします。詳細はクイックスタートを参照してください。
新機能:
- バージョンv5.1に更新、Qwen2 VLがテキストエンコーダーとして使用され、Flowがサンプリング方法として使用されます。中国語と英語の両方でバイリンガル予測をサポートしています。CannyやPoseといった一般的なコントロールに加えて、軌道制御やカメラ制御もサポートしています。[2025.01.21]
- インセンティブ逆伝播を使用してLoraを訓練し、人間の好みに合うようにビデオを最適化します。詳細は、[ここ](scripts/README _ train _ REVARD.md)を参照してください。EasyAnimateV 5-7 bがリリースされました。[2024.11.27]
- v5に更新、1024x1024までの動画生成をサポート、49フレーム、6秒、8fps、モデルスケールを12Bに拡張、MMDIT構造を組み込み、さまざまな入力を持つ制御モデルをサポート。中国語と英語のバイリンガル予測をサポート。[2024.11.08]
- v4に更新、1024x1024までの動画生成をサポート、144フレーム、6秒、24fps、テキスト、画像、動画からの動画生成をサポート、512から1280までの解像度を単一モデルで処理。中国語と英語のバイリンガル予測をサポート。[2024.08.15]
- v3に更新、960x960までの動画生成をサポート、144フレーム、6秒、24fps、テキストと画像からの動画生成をサポート。[2024.07.01]
- ModelScope-Sora “データディレクター” クリエイティブレース — 第三回Data-Juicerビッグモデルデータチャレンジが正式に開始されました!EasyAnimateをベースモデルとして使用し、データ処理がモデルトレーニングに与える影響を探ります。詳細は競技ウェブサイトをご覧ください。[2024.06.17]
- v2に更新、768x768までの動画生成をサポート、144フレーム、6秒、24fps。[2024.05.26]
- コード作成! 現在、WindowsおよびLinuxをサポート。[2024.04.12]
機能:
私たちのUIインターフェースは次のとおりです:
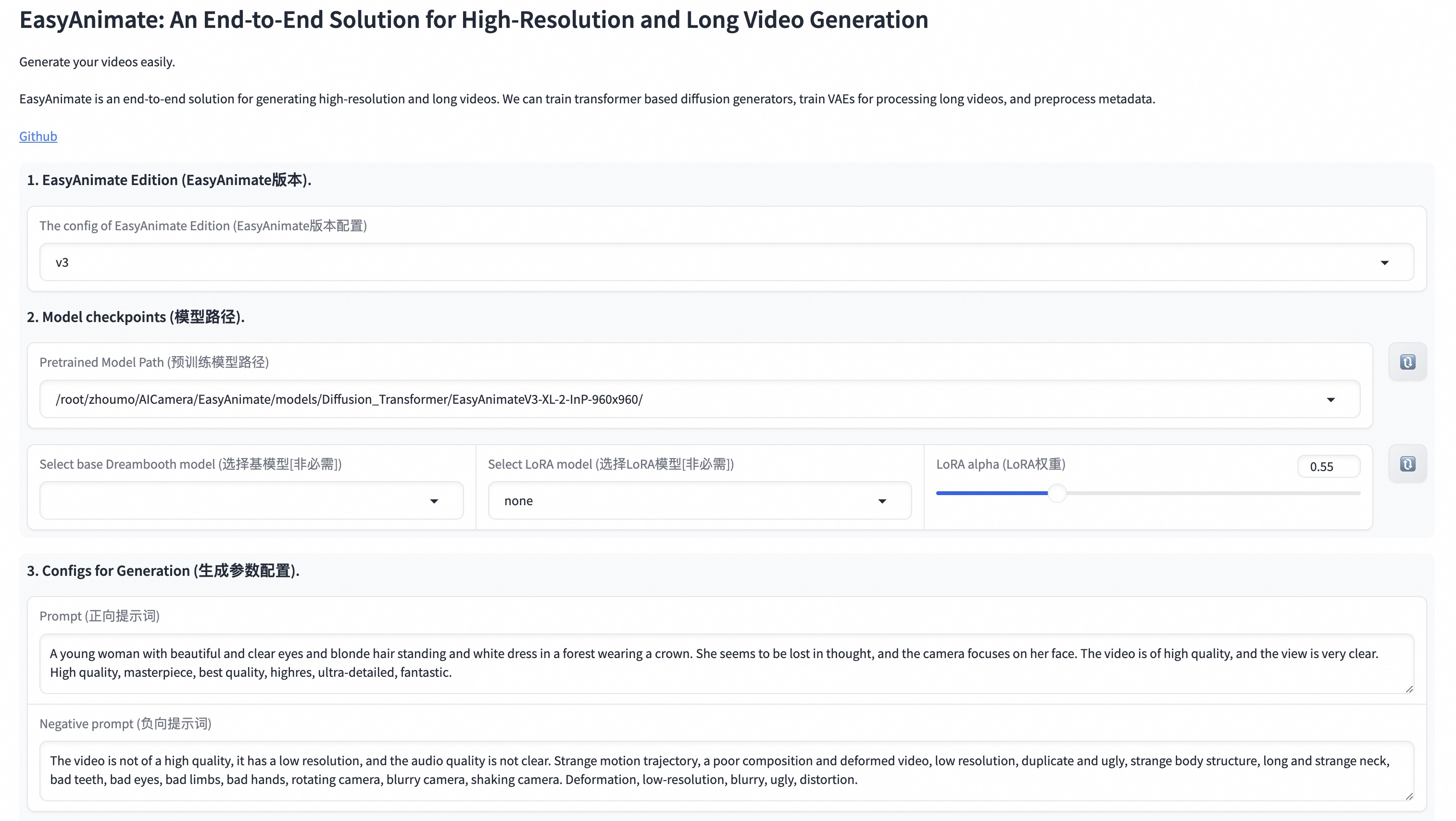
DSWには無料のGPU時間があり、ユーザーは一度申請でき、申請後3ヶ月間有効です。
AliyunはFreetierで無料のGPU時間を提供しており、取得してAliyun PAI-DSWで使用し、5分以内にEasyAnimateを開始できます!

私たちのComfyUIは次のとおりです。詳細はComfyUI READMEを参照してください。
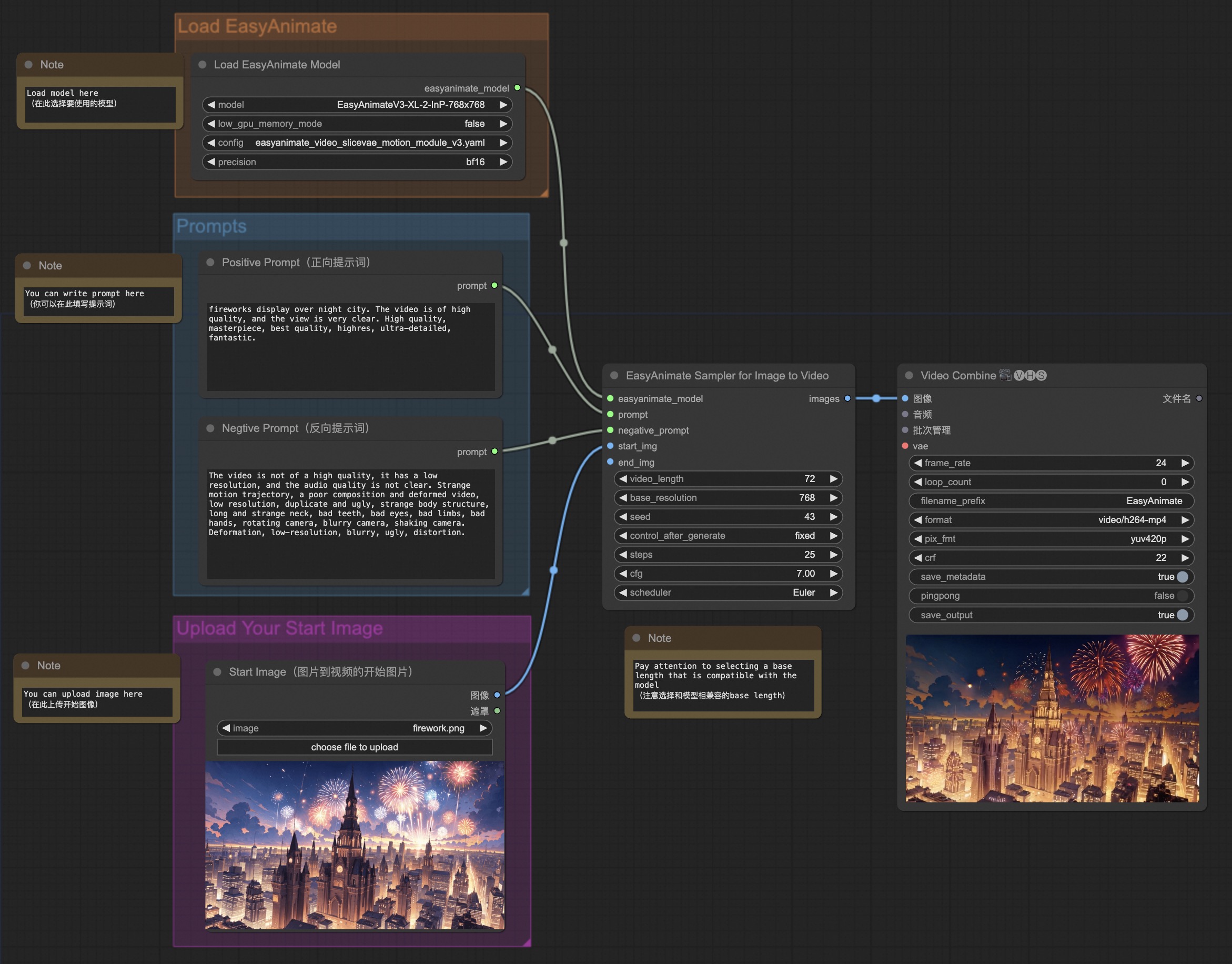
Dockerを使用している場合は、マシンにグラフィックスカードドライバとCUDA環境が正しくインストールされていることを確認してください。
次のコマンドを実行します:
# イメージをプル
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# イメージに入る
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# コードをクローン
git clone https://github.com/aigc-apps/EasyAnimate.git
# EasyAnimateのディレクトリに入る
cd EasyAnimate
# 重みをダウンロード
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
# EasyAnimateV5モデルをダウンロードするには、hugginfaceリンクまたはmodelscopeリンクを使用してください。
# I2Vモデル
# https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP
# https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-InP
# T2Vモデル
# https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh
# https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh
次の環境でEasyAnimateの実行を確認しました:
Windowsの詳細:
- OS: Windows 10
- python: python3.10 & python3.11
- pytorch: torch2.2.0
- CUDA: 11.8 & 12.1
- CUDNN: 8+
- GPU: Nvidia-3060 12G
Linuxの詳細:
- OS: Ubuntu 20.04, CentOS
- python: python3.10 & python3.11
- pytorch: torch2.2.0
- CUDA: 11.8 & 12.1
- CUDNN: 8+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
ディスクに約60GBの空き容量が必要です(重みを保存するため)、確認してください!
EasyAnimateV5.1-12Bのビデオサイズは異なるGPUメモリにより生成できます。以下の表をご覧ください:
| GPUメモリ | 384x672x25 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|---|---|---|---|---|---|---|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ |
| 24GB | 🧡 | 🧡 | 🧡 | 🧡 | 🧡 | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
qwen2-vl-7bのfloat16の重みのため、16GBのVRAMでは実行できません。もしお使いのVRAMが16GBである場合は、[Huggingface](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct-GPTQ-
EasyAnimateV5-7Bのビデオサイズは異なるGPUメモリにより生成できます。以下の表をご覧ください:
| GPU memory | 384x672x25 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|---|---|---|---|---|---|---|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ |
| 24GB | ✅ | ✅ | ✅ | 🧡 | 🧡 | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
✅ は"model_cpu_offload"の条件で実行可能であることを示し、🧡は"model_cpu_offload_and_qfloat8"の条件で実行可能を示し、⭕️ は"sequential_cpu_offload"の条件では実行可能であることを示しています。❌は実行できないことを示します。sequential_cpu_offloadにより実行する場合は遅くなります。
一部のGPU(例:2080ti、V100)はtorch.bfloat16をサポートしていないため、app.pyおよびpredictファイル内のweight_dtypeをtorch.float16に変更する必要があります。
EasyAnimateV5-12Bは異なるGPUで25ステップ生成する時間は次の通りです:
| GPU | 384x672x25 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|---|---|---|---|---|---|---|
| A10 24GB | 約120秒 (4.8s/it) | 約240秒 (9.6s/it) | 約320秒 (12.7s/it) | 約750秒 (29.8s/it) | ❌ | ❌ |
| A100 80GB | 約45秒 (1.75s/it) | 約90秒 (3.7s/it) | 約120秒 (4.7s/it) | 約300秒 (11.4s/it) | 約265秒 (10.6s/it) | 約710秒 (28.3s/it) |
(廃止予定) EasyAnimateV3:
EasyAnimateV3のビデオサイズは異なるGPUメモリにより生成できます。以下の表をご覧ください: | GPUメモリ | 384x672x72 | 384x672x144 | 576x1008x72 | 576x1008x144 | 720x1280x72 | 720x1280x144 | |----------|----------|----------|----------|----------|----------|----------| | 12GB | ⭕️ | ⭕️ | ⭕️ | ⭕️ | ❌ | ❌ | | 16GB | ✅ | ✅ | ⭕️ | ⭕️ | ⭕️ | ❌ | | 24GB | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | | 40GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | | 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |(⭕️) はlow_gpu_memory_mode=Trueの条件で実行可能であるが、速度が遅くなることを示しています。また、❌は実行できないことを示します。
重みを指定されたパスに配置することをお勧めします:
EasyAnimateV5:
📦 models/
├── 📂 Diffusion_Transformer/
│ ├── 📂 EasyAnimateV5.1-12b-zh-InP/
│ └── 📂 EasyAnimateV5.1-12b-zh/
├── 📂 Personalized_Model/
│ └── あなたのトレーニング済みのトランスフォーマーモデル / あなたのトレーニング済みのLoraモデル(UIロード用)
1.mp4 |
2.mp4 |
3.mp4 |
4.mp4 |
1.mp4 |
2.mp4 |
3.mp4 |
4.mp4 |
1.mp4 |
2.mp4 |
3.mp4 |
4.mp4 |
1.mp4 |
2.mp4 |
3.mp4 |
4.mp4 |
5.mp4 |
6.mp4 |
7.mp4 |
8.mp4 |
Trajectory Control:
EasyAnimate-Trajectory_00030.mp4 |
EasyAnimate-Trajectory-Merge_00009.mp4 |
EasyAnimate_00105.mp4 |
Generic Control Video (Canny, Pose, Depth, etc.):
demo_pose.mp4 |
demo_scribble.mp4 |
demo_depth.mp4 |
demo_pose_out.mp4 |
demo_scribble_out.mp4 |
demo_depth_out.mp4 |
| Pan Up | Pan Left | Pan Right |
Up.mp4 |
Left.mp4 |
Right.mp4 |
| Pan Down | Pan Up + Pan Left | Pan Up + Pan Right |
Down.mp4 |
Up_Left.mp4 |
Up_Right.mp4 |
EasyAnimateV5およびV5.1のパラメータが非常に大きいため、消費者向けグラフィックスカードに適応させるためにメモリの節約策を考慮する必要があります。各予測ファイルにはGPU_memory_modeを提供しており、model_cpu_offload、model_cpu_offload_and_qfloat8、sequential_cpu_offloadから選択することができます。
- model_cpu_offloadは、使用後にモデル全体がCPUに移動することを示し、メモリの一部を節約できます。
- model_cpu_offload_and_qfloat8は、使用後にモデル全体がCPUに移動し、トランスフォーマーモデルをfloat8に量子化することを示し、さらに多くのメモリを節約できます。
- sequential_cpu_offloadは、使用後に各レイヤーが順次CPUに移動することを示し、速度は遅くなりますが、大量のメモリを節約できます。
qfloat8はモデルの性能を低下させますが、さらに多くのメモリを節約できます。メモリが十分にある場合は、model_cpu_offloadを使用することをお勧めします。
詳細はComfyUI READMEをご覧ください。
- ステップ1:対応する重みをダウンロードし、modelsフォルダに入れます。
- ステップ2:異なる重みと予測目標に応じて異なるファイルを使用して予測を行います。
- テキストからビデオの生成:
- predict_t2v.pyファイルでprompt、neg_prompt、guidance_scale、seedを変更します。
- 次にpredict_t2v.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videosフォルダに保存されます。
- 画像からビデオの生成:
- predict_i2v.pyファイルでvalidation_image_start、validation_image_end、prompt、neg_prompt、guidance_scale、seedを変更します。
- validation_image_startはビデオの開始画像、validation_image_endはビデオの終了画像です。
- 次にpredict_i2v.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videos_i2vフォルダに保存されます。
- ビデオからビデオの生成:
- predict_v2v.pyファイルでvalidation_video、validation_image_end、prompt、neg_prompt、guidance_scale、seedを変更します。
- validation_videoはビデオの参照ビデオです。以下のビデオを使用してデモを実行できます:デモビデオ
- 次にpredict_v2v.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videos_v2vフォルダに保存されます。
- 通常のコントロールビデオ生成(Canny、Pose、Depthなど):
- predict_v2v_control.pyファイルでcontrol_video、validation_image_end、prompt、neg_prompt、guidance_scale、seedを変更します。
- control_videoはCanny、Pose、Depthなどのフィルタを適用した後のビデオです。以下のビデオを使用してデモを実行できます:デモビデオ
- 次にpredict_v2v_control.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videos_v2v_controlフォルダに保存されます。
- トラジェクトリーコントロールビデオ:
- predict_v2v_control.pyファイルでcontrol_video、ref_image、validation_image_end、prompt、neg_prompt、guidance_scale、seedを変更します。
- control_videoはトラジェクトリーコントロールビデオのコントロールビデオ、ref_imageは参照の初期フレーム画像です。以下の画像とコントロールビデオを使用してデモを実行できます:デモ画像、デモビデオ
- 次にpredict_v2v_control.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videos_v2v_controlフォルダに保存されます。
- 交互利用にComfyUIの使用を推奨します。
- カメラコントロールビデオ:
- predict_v2v_control.pyファイルでcontrol_video、ref_image、validation_image_end、prompt、neg_prompt、guidance_scale、seedを変更します。
- control_camera_txtはカメラコントロールビデオのコントロールファイル、ref_imageは参照の初期フレーム画像です。以下の画像とコントロールビデオを使用してデモを実行できます:デモ画像、デモファイル(CameraCtrlから)
- 次にpredict_v2v_control.pyファイルを実行し、生成結果を待ちます。結果はsamples/easyanimate-videos_v2v_controlフォルダに保存されます。
- 交互利用にComfyUIの使用を推奨します。
- テキストからビデオの生成:
- ステップ3:他のトレーニング済みバックボーンとLoraを組み合わせたい場合、predict_t2v.pyでpredict_t2v.pyとlora_pathを適宜変更してください。
webuiはテキストからビデオ、画像からビデオ、ビデオからビデオ、および通常のコントロールビデオ(Canny、Pose、Depthなど)の生成をサポートしています。
- ステップ1:対応する重みをダウンロードし、modelsフォルダに入れます。
- ステップ2:app.pyファイルを実行し、gradioページに入ります。
- ステップ3:ページで生成モデルを選択し、prompt、neg_prompt、guidance_scale、seedなどを入力して生成をクリックし、生成結果を待ちます。結果はsampleフォルダに保存されます。
完全なEasyAnimateトレーニングパイプラインには、データ前処理、Video VAEトレーニング、およびVideo DiTトレーニングが含まれる必要があります。これらの中で、Video VAEトレーニングはオプションです。すでにトレーニング済みのVideo VAEを提供しているためです。
私たちは2つの簡単なデモを提供します:
長時間動画のセグメンテーション、クリーニング、および説明のための完全なデータ前処理リンクは、ビデオキャプションセクションのREADMEを参照してください。
テキストから画像および動画生成モデルをトレーニングする場合は、データセットを次の形式で配置する必要があります。
📦 project/
├── 📂 datasets/
│ ├── 📂 internal_datasets/
│ ├── 📂 train/
│ │ ├── 📄 00000001.mp4
│ │ ├── 📄 00000002.jpg
│ │ └── 📄 .....
│ └── 📄 json_of_internal_datasets.json
json_of_internal_datasets.jsonは標準のJSONファイルです。json内のfile_pathは相対パスとして設定できます。以下のように:
[
{
"file_path": "train/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "train/00000002.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]パスを絶対パスとして設定することもできます:
[
{
"file_path": "/mnt/data/videos/00000001.mp4",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "video"
},
{
"file_path": "/mnt/data/train/00000001.jpg",
"text": "A group of young men in suits and sunglasses are walking down a city street.",
"type": "image"
},
.....
]Video VAEトレーニングはオプションです。すでにトレーニング済みのVideo VAEを提供しているためです。 Video VAEをトレーニングする場合は、ビデオVAEセクションのREADMEを参照してください。
データ前処理時にデータ形式が相対パスの場合、scripts/train.shを次のように設定します。
export DATASET_NAME="datasets/internal_datasets/"
export DATASET_META_NAME="datasets/internal_datasets/json_of_internal_datasets.json"
データ前処理時にデータ形式が絶対パスの場合、scripts/train.shを次のように設定します。
export DATASET_NAME=""
export DATASET_META_NAME="/mnt/data/json_of_internal_datasets.json"
次に、scripts/train.shを実行します。
sh scripts/train.sh一部のパラメータの設定の詳細については、Readme TrainおよびReadme Loraを参照してください。
(Obsolete) EasyAnimateV1:
EasyAnimateV1をトレーニングする場合は、gitブランチv1に切り替えてください。12B:
| 名前 | タイプ | ストレージスペース | Hugging Face | モデルスコープ | 説明 |
|---|---|---|---|---|---|
| EasyAnimateV5.1-12b-zh-InP | EasyAnimateV5.1 | 39 GB | 🤗リンク | 😄リンク | 公式の画像からビデオへの変換用の重み。支持多解像度(512、768、1024)的ビデオ予測、49フレームで毎秒8フレームの訓練、多言語予測をサポート |
| EasyAnimateV5.1-12b-zh-Control | EasyAnimateV5.1 | 39 GB | 🤗リンク | 😄リンク | 公式のビデオ制御用の重み。Canny、Depth、Pose、MLSD、および軌道制御などのさまざまな制御条件をサポートします。支持多解像度(512、768、1024)的ビデオ予測、49フレームで毎秒8フレームの訓練、多言語予測をサポート |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | 🤗リンク | 😄リンク | 公式のビデオカメラ制御用の重み。カメラの動きの軌跡を入力することで方向生成を制御します。支持多解像度(512、768、1024)的ビデオ予測、49フレームで毎秒8フレームの訓練、多言語予測をサポート |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | 🤗リンク | 😄リンク | 公式のテキストからビデオへの変換用の重み。支持多解像度(512、768、1024)的ビデオ予測、49フレームで毎秒8フレームの訓練、多言語予測をサポート |
(Obsolete) EasyAnimateV5:
7B:
| 名前 | 種類 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|---|---|---|---|---|---|
| EasyAnimateV5-7b-zh-InP | EasyAnimateV5 | 22 GB | 🤗Link | 😄Link | 公式の画像から動画への重み。複数の解像度(512、768、1024)での動画予測をサポートし、49フレーム、毎秒8フレームでトレーニングされ、中国語と英語のバイリンガル予測をサポートします。 |
| EasyAnimateV5-7b-zh | EasyAnimateV5 | 22 GB | 🤗Link | 😄Link | 公式のテキストから動画への重み。複数の解像度(512、768、1024)での動画予測をサポートし、49フレーム、毎秒8フレームでトレーニングされ、中国語と英語のバイリンガル予測をサポートします。 |
| EasyAnimateV5-Reward-LoRAs | EasyAnimateV5 | - | 🤗Link | 😄Link | 公式インバース伝播技術モデルによるEasyAnimateV 5-12 b生成ビデオの最適化によるヒト選好の最適化| |
12B:
| 名前 | 種類 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|---|---|---|---|---|---|
| EasyAnimateV5-12b-zh-InP | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 公式の画像から動画への重み。複数の解像度(512、768、1024)での動画予測をサポートし、49フレーム、毎秒8フレームでトレーニングされ、中国語と英語のバイリンガル予測をサポートします。 |
| EasyAnimateV5-12b-zh-Control | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 公式の動画制御重み。Canny、Depth、Pose、MLSDなどのさまざまな制御条件をサポートします。複数の解像度(512、768、1024)での動画予測をサポートし、49フレーム、毎秒8フレームでトレーニングされ、中国語と英語のバイリンガル予測をサポートします。 |
| EasyAnimateV5-12b-zh | EasyAnimateV5 | 34 GB | 🤗Link | 😄Link | 公式のテキストから動画への重み。複数の解像度(512、768、1024)での動画予測をサポートし、49フレーム、毎秒8フレームでトレーニングされ、中国語と英語のバイリンガル予測をサポートします。 |
| EasyAnimateV5-Reward-LoRAs | EasyAnimateV5 | - | 🤗Link | 😄Link | 公式インバース伝播技術モデルによるEasyAnimateV 5-12 b生成ビデオの最適化によるヒト選好の最適化| |
(Obsolete) EasyAnimateV4:
| 名前 | 種類 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|---|---|---|---|---|---|
| EasyAnimateV4-XL-2-InP | EasyAnimateV4 | 解凍前: 8.9 GB / 解凍後: 14.0 GB | 🤗Link | 😄Link | 公式のグラフ生成動画モデル。複数の解像度(512、768、1024、1280)での動画予測をサポートし、144フレーム、毎秒24フレームでトレーニングされています。 |
(Obsolete) EasyAnimateV3:
| 名前 | 種類 | ストレージスペース | Hugging Face | Model Scope | 説明 |
|---|---|---|---|---|---|
| EasyAnimateV3-XL-2-InP-512x512 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3公式の512x512テキストおよび画像から動画への重み。144フレーム、毎秒24フレームでトレーニングされています。 |
| EasyAnimateV3-XL-2-InP-768x768 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3公式の768x768テキストおよび画像から動画への重み。144フレーム、毎秒24フレームでトレーニングされています。 |
| EasyAnimateV3-XL-2-InP-960x960 | EasyAnimateV3 | 18.2GB | 🤗Link | 😄Link | EasyAnimateV3公式の960x960テキストおよび画像から動画への重み。144フレーム、毎秒24フレームでトレーニングされています。 |
(Obsolete) EasyAnimateV2:
| 名前 | 種類 | ストレージスペース | URL | Hugging Face | Model Scope | 説明 |
|---|---|---|---|---|---|---|
| EasyAnimateV2-XL-2-512x512 | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | EasyAnimateV2公式の512x512解像度の重み。144フレーム、毎秒24フレームでトレーニングされています。 |
| EasyAnimateV2-XL-2-768x768 | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | EasyAnimateV2公式の768x768解像度の重み。144フレーム、毎秒24フレームでトレーニングされています。 |
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | ダウンロード | - | - | 特定のタイプの画像でトレーニングされたLora。画像はURLからダウンロードできます。 |
(Obsolete) EasyAnimateV1:
| 名前 | 種類 | ストレージスペース | URL | 説明 |
|---|---|---|---|---|
| easyanimate_v1_mm.safetensors | モーションモジュール | 4.1GB | ダウンロード | 80フレーム、毎秒12フレームでトレーニングされています。 |
| 名前 | 種類 | ストレージスペース | URL | 説明 |
|---|---|---|---|---|
| PixArt-XL-2-512x512.tar | Pixart | 11.4GB | ダウンロード | Pixart-Alpha公式の重み。 |
| easyanimate_portrait.safetensors | Pixartのチェックポイント | 2.3GB | ダウンロード | 内部のポートレートデータセットでトレーニングされています。 |
| easyanimate_portrait_lora.safetensors | PixartのLora | 654.0MB | ダウンロード | 内部のポートレートデータセットでトレーニングされています。 |
- より大きなパラメータを持つモデルをサポートします。
- Dingdingを使用してグループ77450006752を検索するか、スキャンして参加します。
- WeChatグループに参加するには画像をスキャンするか、期限切れの場合はこの学生を友達として追加して招待します。


{kind=link}
{kind=link}
- CogVideo: https://github.com/THUDM/CogVideo/
- Flux: https://github.com/black-forest-labs/flux
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
- HunYuan DiT: https://github.com/tencent/HunyuanDiT
- ComfyUI-KJNodes: https://github.com/kijai/ComfyUI-KJNodes
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
- ComfyUI-CameraCtrl-Wrapper: https://github.com/chaojie/ComfyUI-CameraCtrl-Wrapper
- CameraCtrl: https://github.com/hehao13/CameraCtrl
- DragAnything: https://github.com/showlab/DragAnything
このプロジェクトはApache License (Version 2.0)の下でライセンスされています。