 +Source: Artwork by @allison_horst
+
+
+
+Source: Artwork by @allison_horst
+
+
+Regression prediction problem¶
What if we want to predict a quantitative value instead of a class label?
+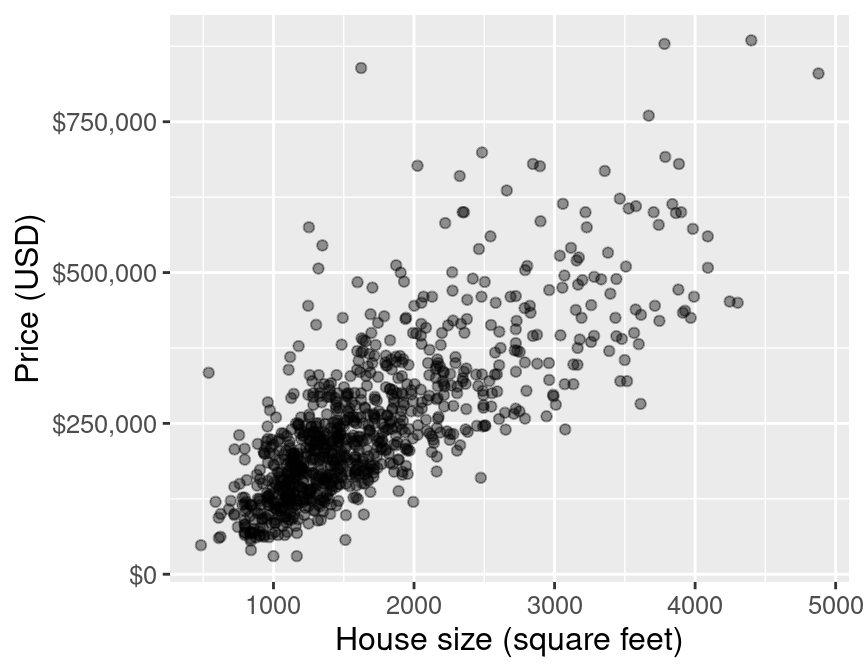
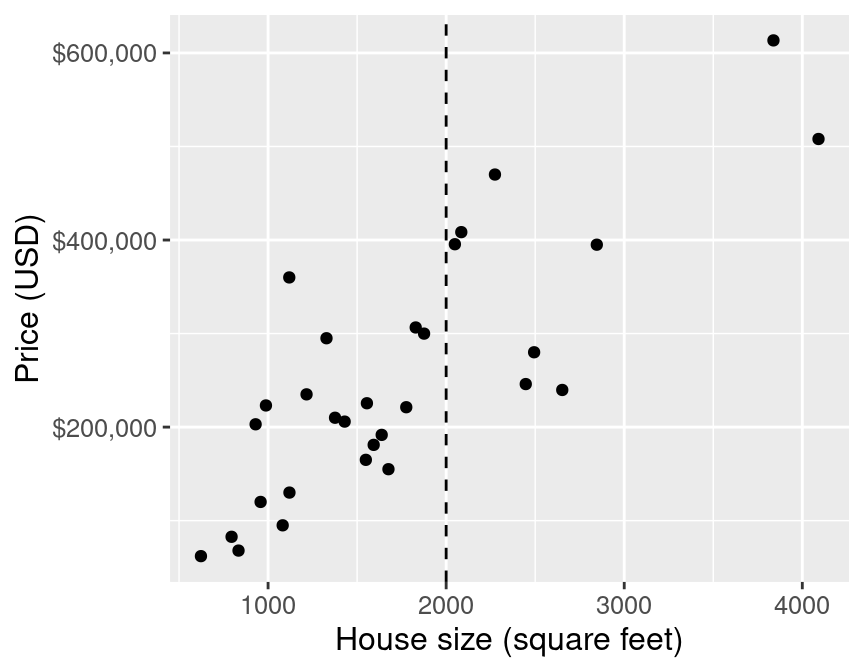
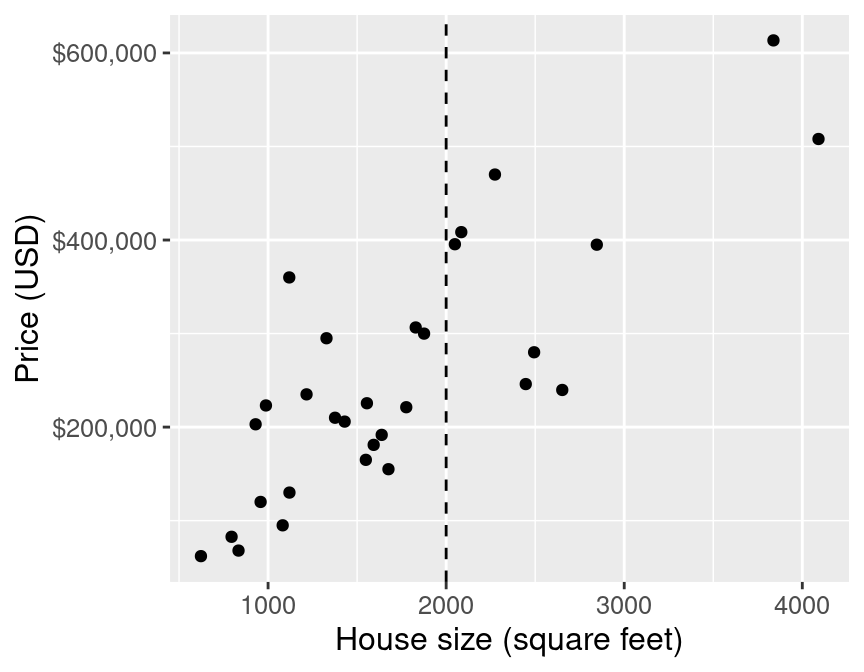
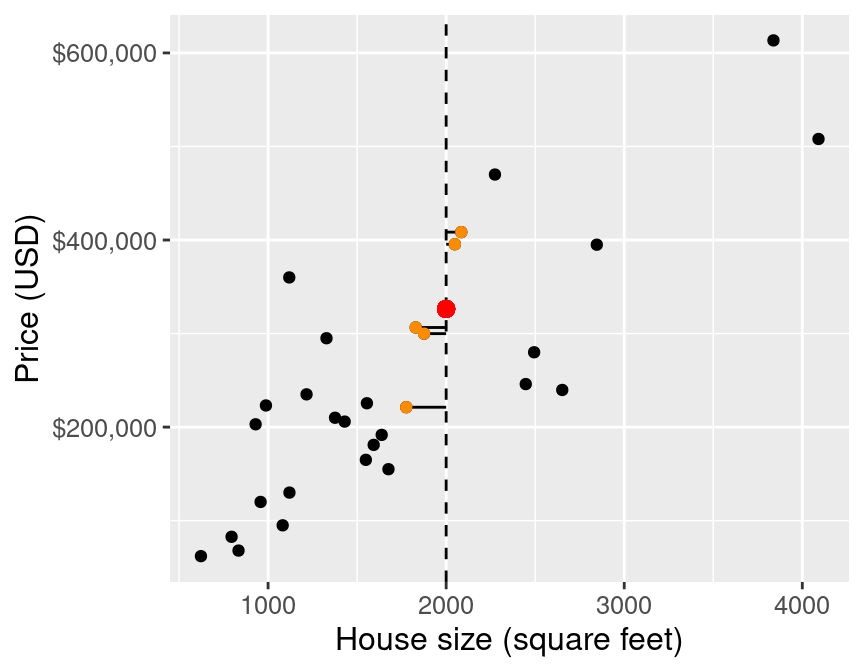
E.g.: predict the price of a 2000 square foot home (from this reduced dataset)
+
K nearest neighbours regression¶
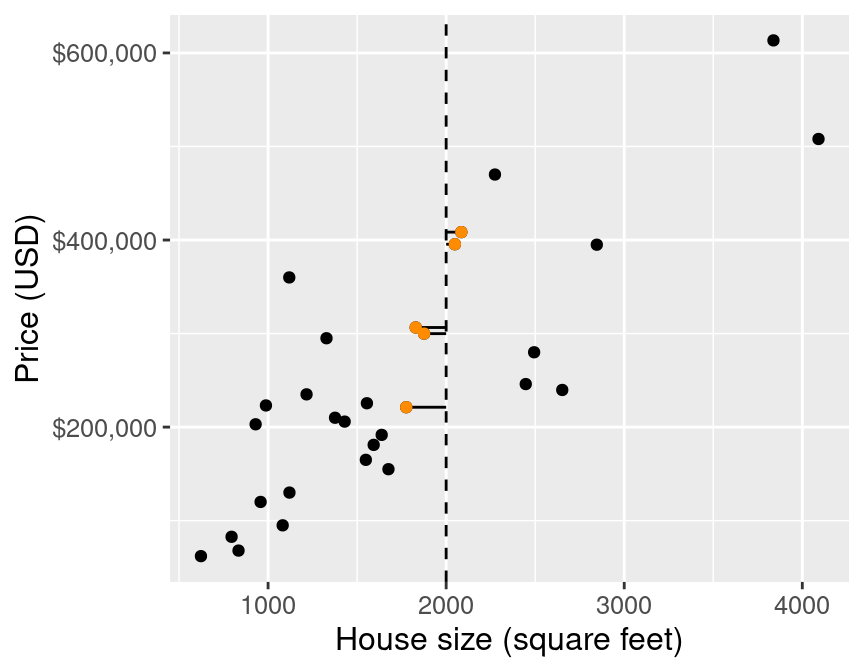
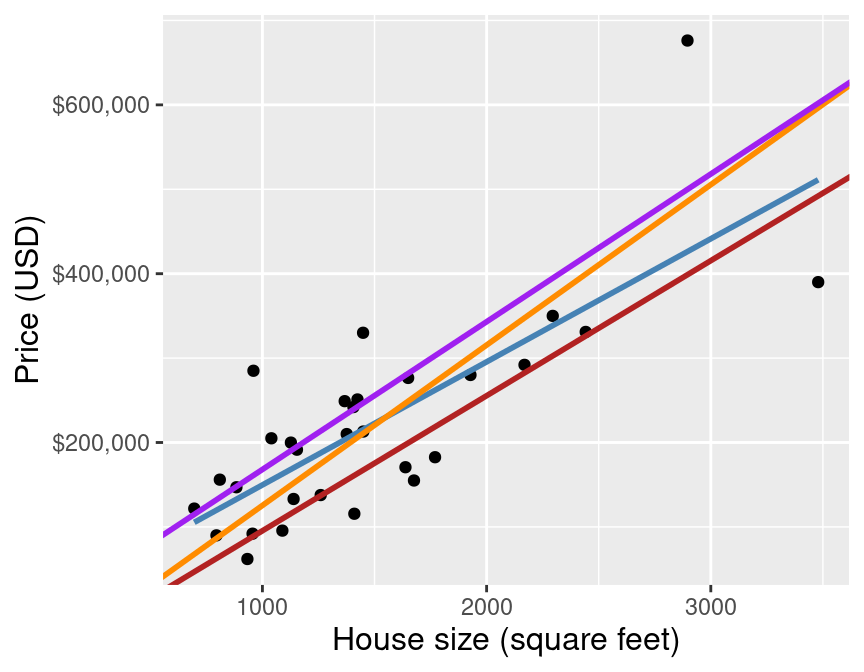
As in k-nn classification, we find the $k$-nearest neighbours (here $k=5$) in terms of the predictors
+
K nearest neighbours regression¶
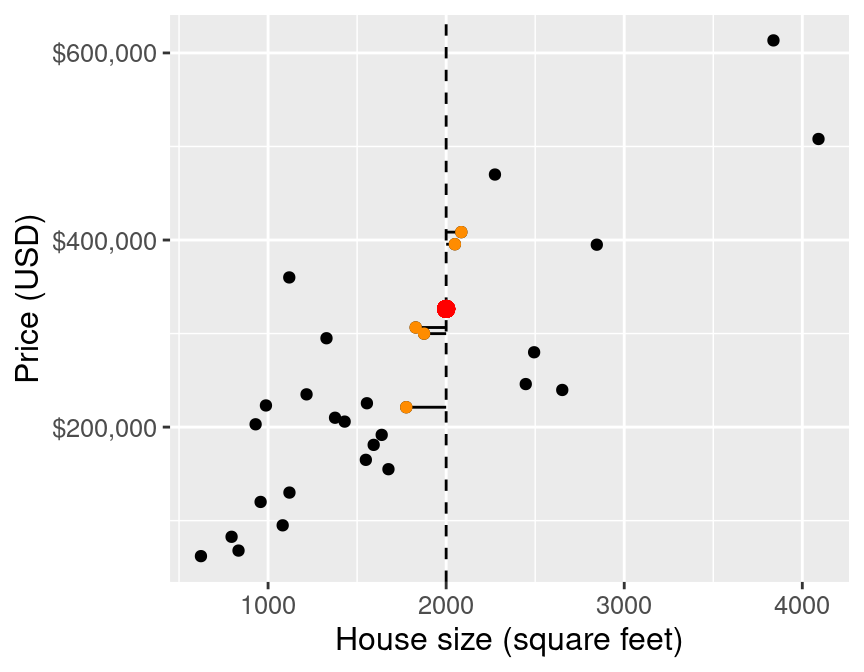
Then we average the values for the $k$-nearest neighbours, and use that as the prediction:
+
K nearest neighbours regression¶
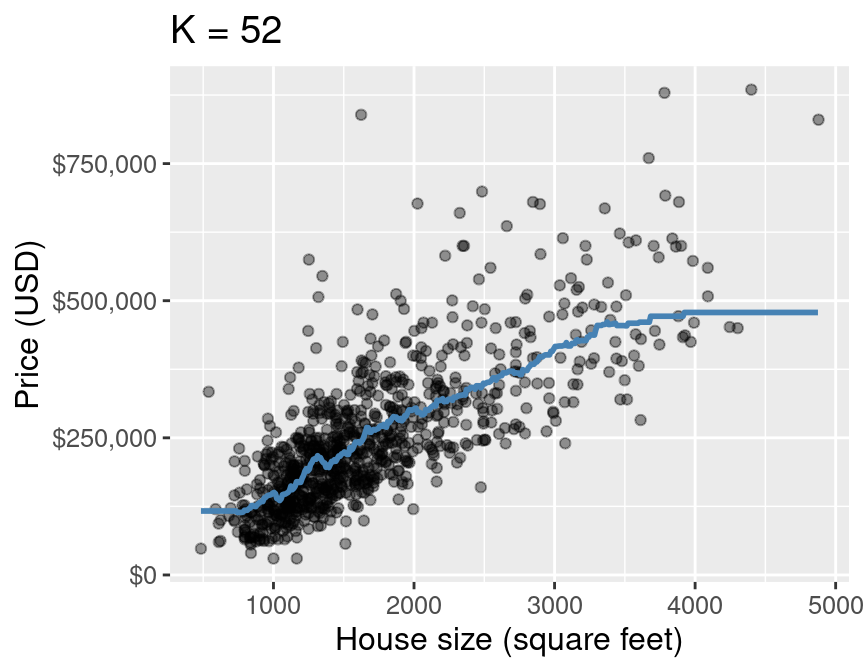
If we do that for a range of house sizes, we can draw the curve of predictions:
+
Regression prediction problem¶
We still have to answer these two questions:
+-
+
Is our model any good?
+
+How do we choose
+k?
+
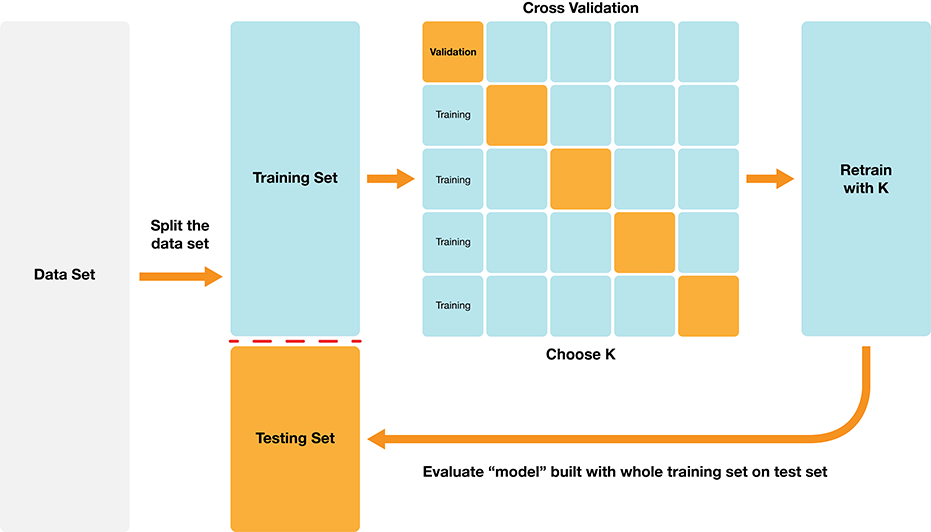
The same general strategy as in classification works here!
+
1. Is our model any good?¶
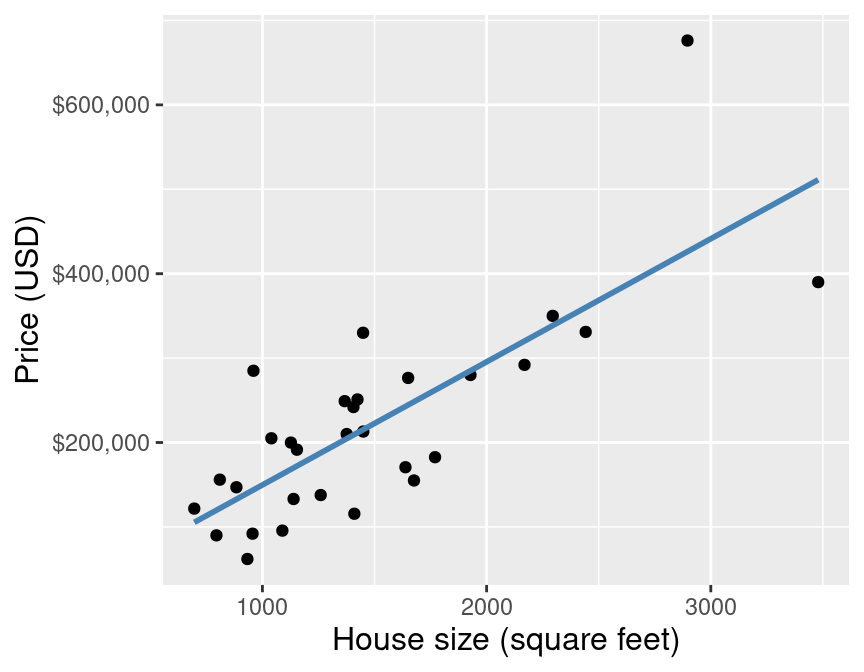
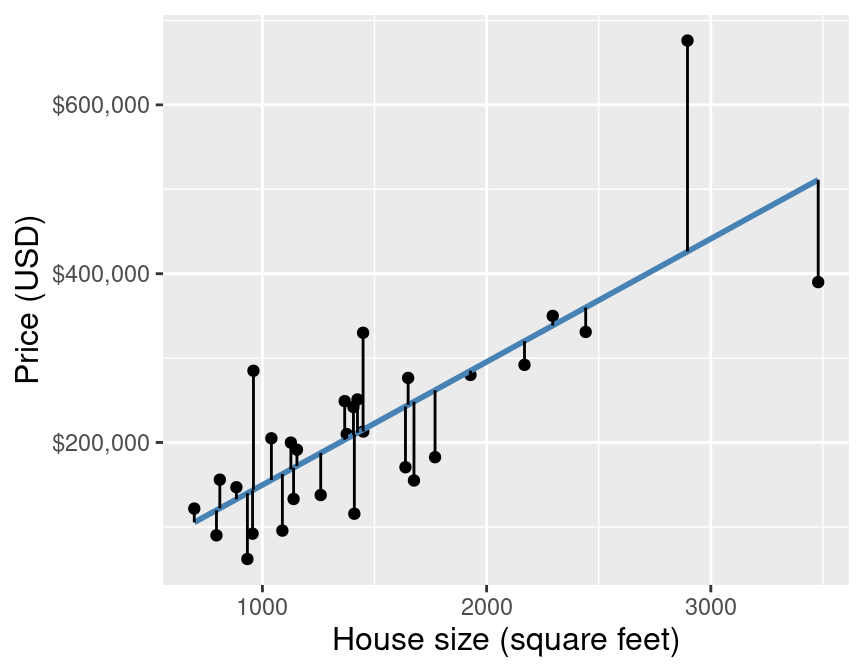
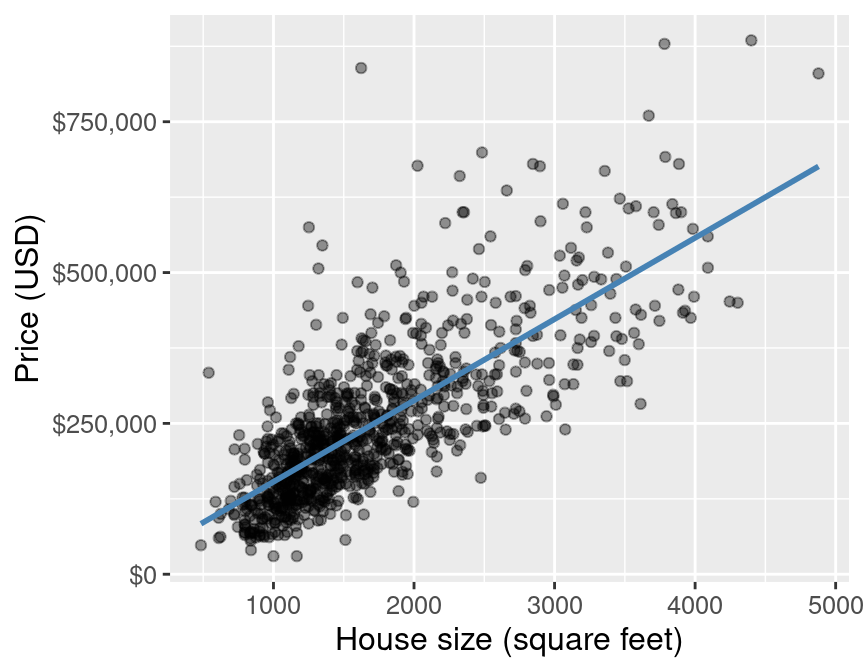
The blue line depicts our predictions from k-nn regression.
+
1. Is our model any good?¶
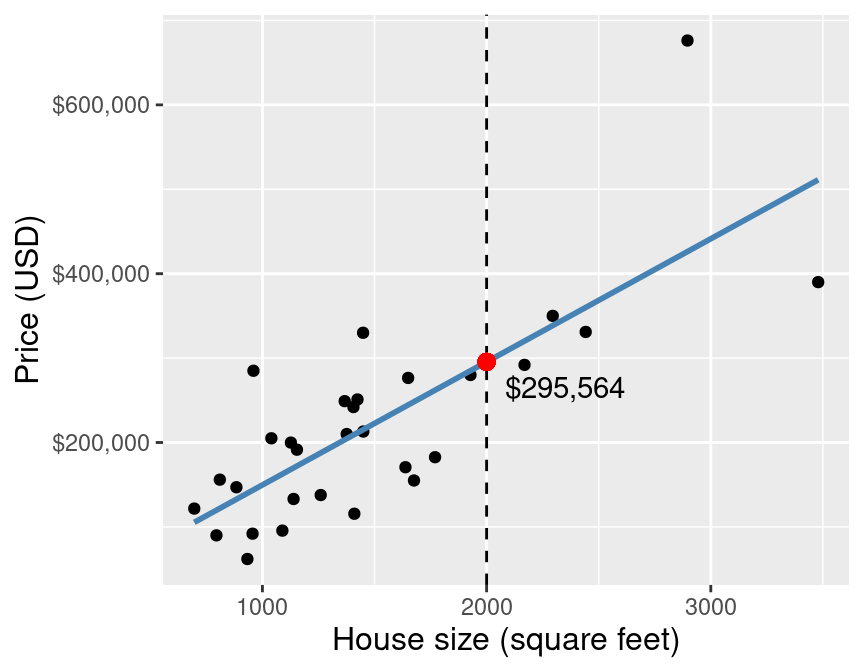
The blue line depicts our predictions from k-nn regression. The red lines depict the error in our predictions, i.e., the difference between the $i^\text{th}$ test data response and our prediction $\hat{y}_i$:
+
 +
+1. Is our model any good?¶
We (roughly) add up these errors to evaluate our regression model
+-
+
- Not out of 1, but instead in units of the target variable (bit harder to interpret) +
|
+ Root Mean Squared Prediction Error (RMSPE): +$$RMSPE = \sqrt{\frac{1}{n}\sum\limits_{i=1}^{n}(y_i - \hat{y_i})^2}$$ +- $n$ is the number of observations +- $y_i$ is the observed value for the $i^\text{th}$ test observation +- $\hat{y_i}$ is the predicted value for the $i^\text{th}$ test observation + |
+ |
+
RMSE vs RMSPE¶
-
+
- Root Mean Squared Error (RMSE): The same formula except on the data used to train the model
-
+
- this indicates how well our model can fit our data +
+ - Root Mean Squared Prediction Error (RMSPE): predicting on unseen data.
-
+
- this indicates how well our model generalizes to future data +
+
No standard terminology.
+2. How do we choose k?¶
+Roughly the same as before!
+-
+
- Cross validation:
-
+
- Split data into $C$ folds +
- Train +
- Evaluate model +
- Pick k that gives the lowest RMSPE on validation set +
+
-
+
- Train model on whole training dataset (not split into folds) +
-
+
- Evaluate how good the predictions are using the test data +
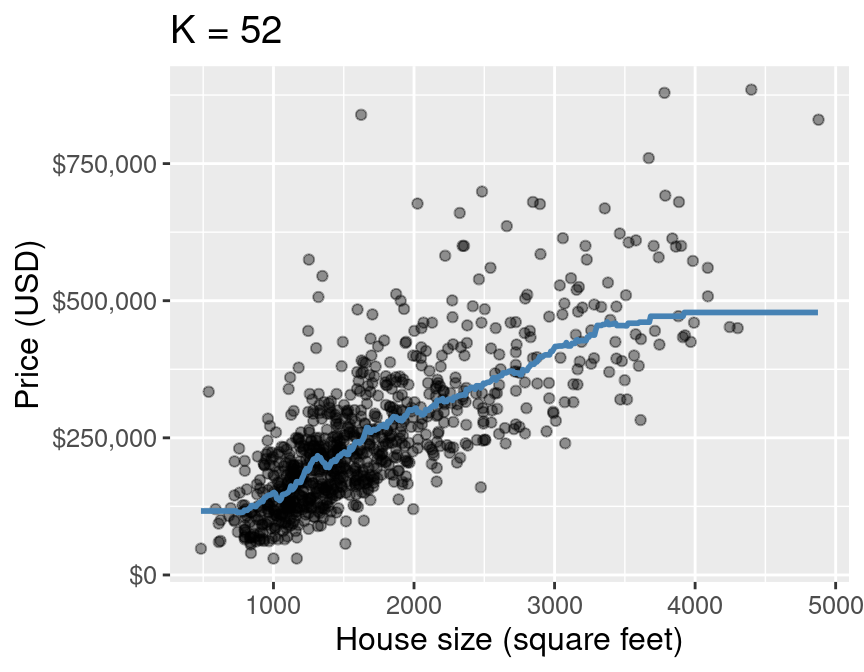
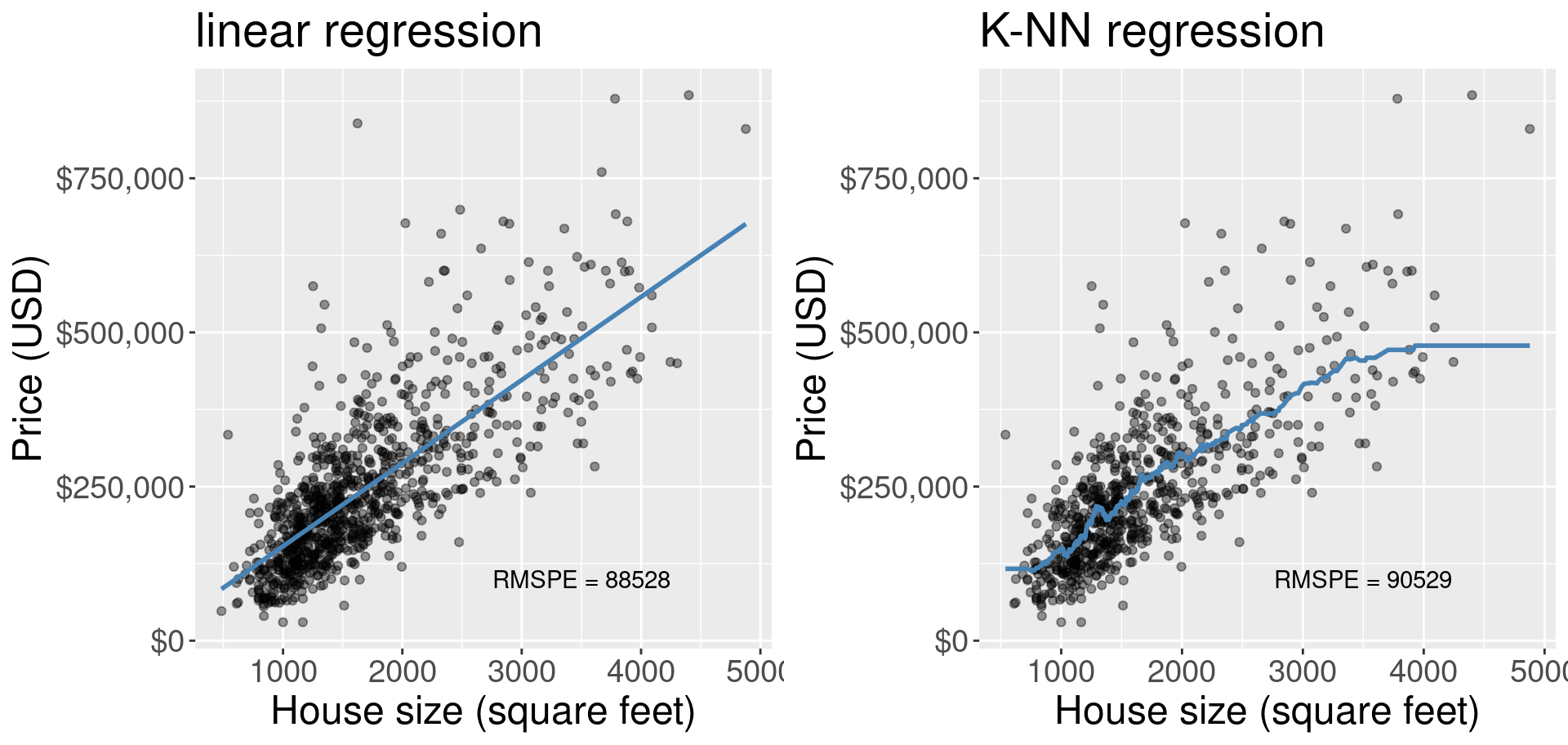
How does $k$ affect k-nn regression?¶
Discussion: Which of the following is overfitting? Underfitting?¶
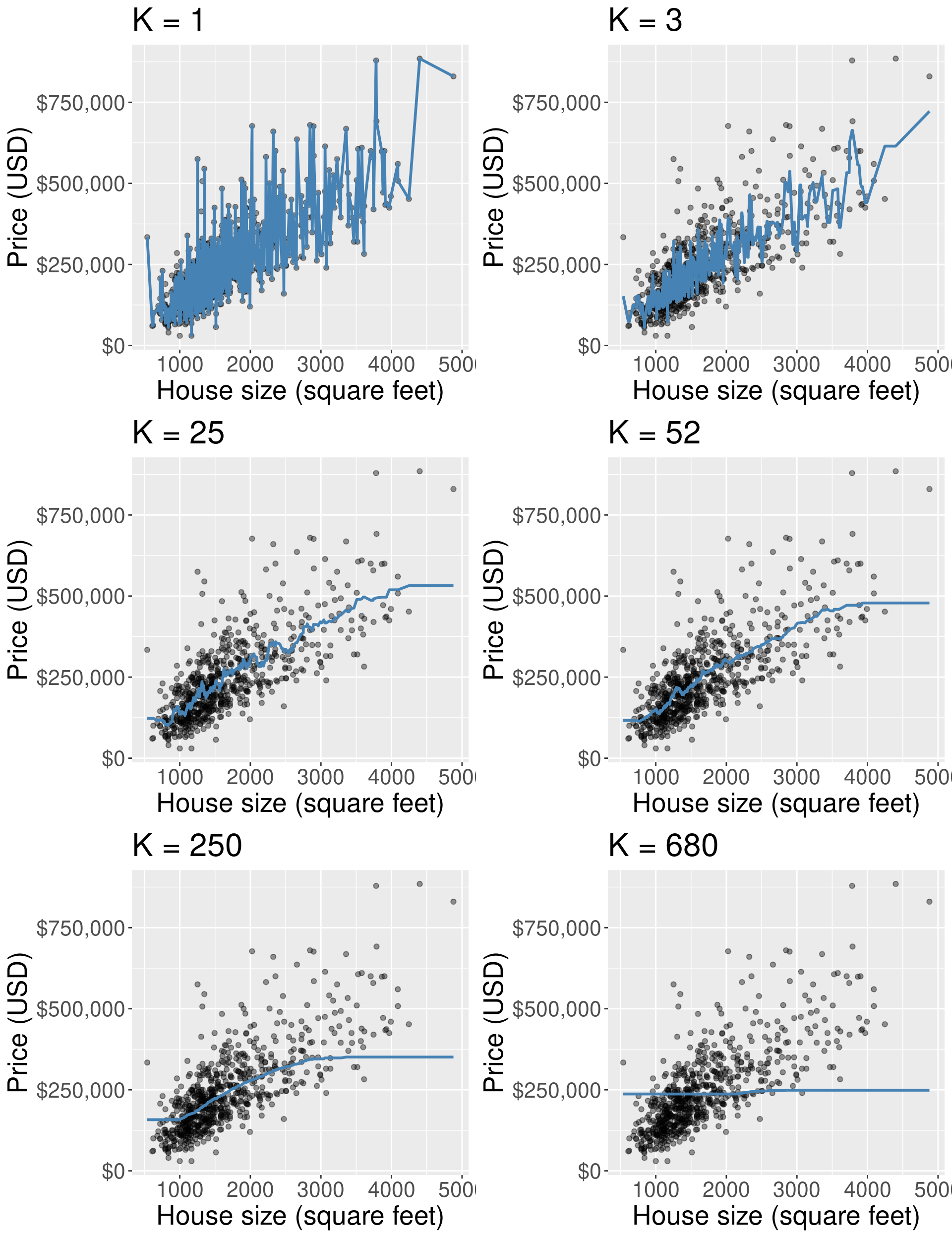
Worksheet time - go for it!¶
-
+
- Remember work together with your groups - help one another if you can! +
- If you get stuck, we will be walking around to answer questions +
- Please reserve your proposal questions and ask during office hours today +
What did you learn?¶
-
+
+
+
+
 +
+


 +
+