diff --git a/docs/pipeline_deploy/high_performance_inference.md b/docs/pipeline_deploy/high_performance_inference.md
index 8404803afe..d8c3c528ab 100644
--- a/docs/pipeline_deploy/high_performance_inference.md
+++ b/docs/pipeline_deploy/high_performance_inference.md
@@ -691,14 +691,3 @@ python -m pip install ../../python/dist/ultra_infer*.whl
-
-
-
-
-
-
-
-
-
-
-
diff --git a/docs/pipeline_deploy/serving.en.md b/docs/pipeline_deploy/serving.en.md
index cd4fa92ede..5580014a24 100644
--- a/docs/pipeline_deploy/serving.en.md
+++ b/docs/pipeline_deploy/serving.en.md
@@ -128,7 +128,7 @@ Find the high-stability serving SDK corresponding to the pipeline in the table b
| General image classification |
-paddlex_hps_image_classification.tar.gz |
+paddlex_hps_image_classification_sdk.tar.gz |
| General object detection |
@@ -262,7 +262,7 @@ Select the pipeline you wish to deploy and click "获取" (acquire). Afterwards,
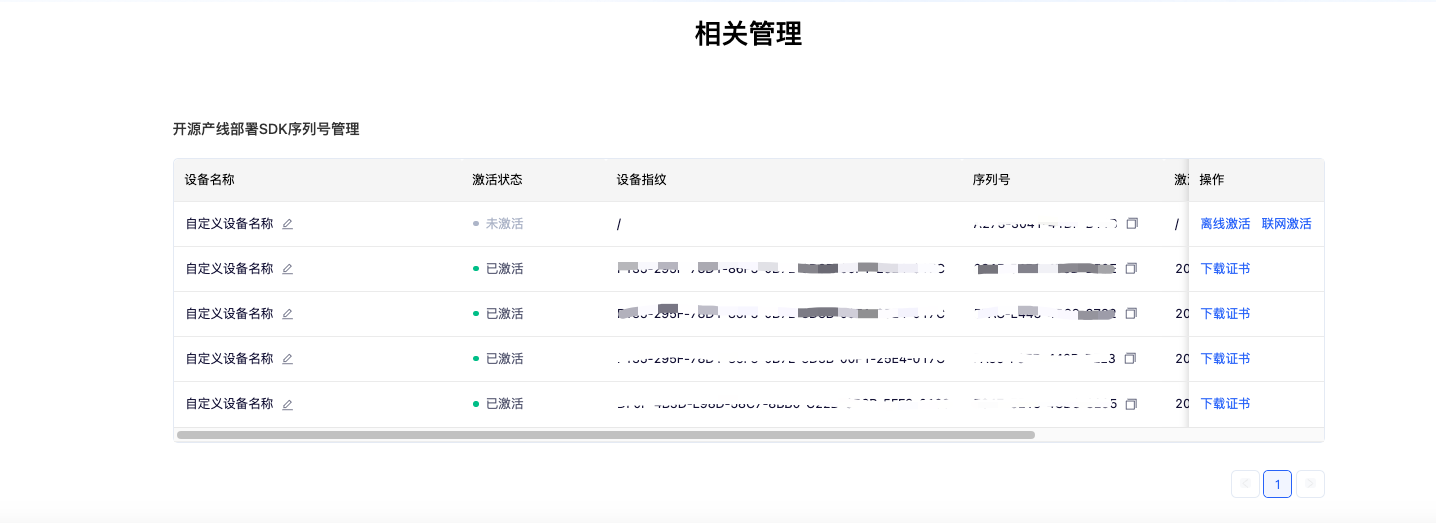 -**Please note**: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if a user deploys a pipeline on different machines, a separate serial number must be prepared for each machine.
+**Please note**: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if a user deploys a pipeline on different machines, a separate serial number must be prepared for each machine. **The high-stability serving solution is completely free.** PaddleX's authentication mechanism is targeted to count the number of deployments across various pipelines and provide pipeline efficiency analysis for our team through data modeling, so as to optimize resource allocation and improve the efficiency of key pipelines. It is important to note that the authentication process only uses non-sensitive information such as disk partition UUIDs, and PaddleX does not collect sensitive data such as device telemetry data. Therefore, in theory, **the authentication server cannot obtain any sensitive information**.
### 2.3 Adjust Configurations
@@ -312,13 +312,13 @@ First, pull the Docker image as needed:
- Image supporting deployment with NVIDIA GPU (the machine must have NVIDIA drivers that support CUDA 11.8 installed):
```bash
- docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0b2-gpu
+ docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0rc0-gpu
```
- CPU-only Image:
```bash
- docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0b2-cpu
+ docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0rc0-cpu
```
With the image prepared, execute the following command to run the server:
@@ -326,30 +326,32 @@ With the image prepared, execute the following command to run the server:
```bash
docker run \
-it \
+ -e PADDLEX_HPS_DEVICE_TYPE={deployment device type} \
+ -e PADDLEX_HPS_SERIAL_NUMBER={serial number} \
+ -e PADDLEX_HPS_UPDATE_LICENSE=1 \
-v "$(pwd)":/workspace \
-v "${HOME}/.baidu/paddlex/licenses":/root/.baidu/paddlex/licenses \
-v /dev/disk/by-uuid:/dev/disk/by-uuid \
-w /workspace \
- -e PADDLEX_HPS_DEVICE_TYPE={deployment device type} \
- -e PADDLEX_HPS_SERIAL_NUMBER={serial number} \
--rm \
--gpus all \
--network host \
--shm-size 8g \
{image name} \
- ./server.sh
+ /bin/bash server.sh
```
- The deployment device type can be `cpu` or `gpu`, and the CPU-only image supports only `cpu`.
- If CPU deployment is required, there is no need to specify `--gpus`.
- The above commands can only be executed properly after successful activation. PaddleX offers two activation methods: online activation and offline activation. They are detailed as follows:
- - Online activation: Add `-e PADDLEX_HPS_UPDATE_LICENSE=1` to the command to enable the program to complete activation automatically.
- - Offline Activation: Follow the instructions in the serial number management section to obtain the machine’s device fingerprint. Bind the serial number with the device fingerprint to obtain the certificate and complete the activation. For this activation method, you need to manually place the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (if the directory does not exist, you will need to create it).
+ - Online activation: Set `PADDLEX_HPS_UPDATE_LICENSE` to `1` for the first execution to enable the program to automatically update the license and complete activation. When executing the command again, you may set `PADDLEX_HPS_UPDATE_LICENSE` to `0` to avoid online license updates.
+ - Offline Activation: Follow the instructions in the serial number management section to obtain the machine’s device fingerprint. Bind the serial number with the device fingerprint to obtain the certificate and complete the activation. For this activation method, you need to manually place the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (if the directory does not exist, you will need to create it). When using this method, set `PADDLEX_HPS_UPDATE_LICENSE` to `0` to avoid online license updates.
- It is necessary to ensure that the `/dev/disk/by-uuid` directory on the host machine exists and is not empty, and that this directory is correctly mounted in order to perform activation properly.
-- If you need to enter the container for debugging, you can replace ``./server.sh` in the command with `/bin/bash`. Then execute `./server.sh` inside the container.
+- If you need to enter the container for debugging, you can replace `/bin/bash server.sh` in the command with `/bin/bash`. Then execute `/bin/bash server.sh` inside the container.
- If you want the server to run in the background, you can replace `-it` in the command with `-d`. After the container starts, you can view the container logs with `docker logs -f {container ID}`.
+- Add `-e PADDLEX_USE_HPIP=1` to use the PaddleX high-performance inference plugin to accelerate the pipeline inference process. However, please note that not all pipelines support using the high-performance inference plugin. Please refer to the [PaddleX High-Performance Inference Guide](./high_performance_inference.en.md) for more information.
You may observe output similar to the following:
@@ -367,8 +369,8 @@ Navigate to the `client` directory of the high-stability serving SDK, and run th
```bash
# It is recommended to install in a virtual environment
-python -m pip install paddlex_hps_client-*.whl
python -m pip install -r requirements.txt
+python -m pip install paddlex_hps_client-*.whl
```
The `client.py` script in the `client` directory contains examples of how to call the service and provides a command-line interface.
diff --git a/docs/pipeline_deploy/serving.md b/docs/pipeline_deploy/serving.md
index 04782dc2f5..a8221d5497 100644
--- a/docs/pipeline_deploy/serving.md
+++ b/docs/pipeline_deploy/serving.md
@@ -128,7 +128,7 @@ paddlex --serve --pipeline image_classification --use_hpip
-**Please note**: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if a user deploys a pipeline on different machines, a separate serial number must be prepared for each machine.
+**Please note**: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if a user deploys a pipeline on different machines, a separate serial number must be prepared for each machine. **The high-stability serving solution is completely free.** PaddleX's authentication mechanism is targeted to count the number of deployments across various pipelines and provide pipeline efficiency analysis for our team through data modeling, so as to optimize resource allocation and improve the efficiency of key pipelines. It is important to note that the authentication process only uses non-sensitive information such as disk partition UUIDs, and PaddleX does not collect sensitive data such as device telemetry data. Therefore, in theory, **the authentication server cannot obtain any sensitive information**.
### 2.3 Adjust Configurations
@@ -312,13 +312,13 @@ First, pull the Docker image as needed:
- Image supporting deployment with NVIDIA GPU (the machine must have NVIDIA drivers that support CUDA 11.8 installed):
```bash
- docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0b2-gpu
+ docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0rc0-gpu
```
- CPU-only Image:
```bash
- docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0b2-cpu
+ docker pull ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/hps:paddlex3.0.0rc0-cpu
```
With the image prepared, execute the following command to run the server:
@@ -326,30 +326,32 @@ With the image prepared, execute the following command to run the server:
```bash
docker run \
-it \
+ -e PADDLEX_HPS_DEVICE_TYPE={deployment device type} \
+ -e PADDLEX_HPS_SERIAL_NUMBER={serial number} \
+ -e PADDLEX_HPS_UPDATE_LICENSE=1 \
-v "$(pwd)":/workspace \
-v "${HOME}/.baidu/paddlex/licenses":/root/.baidu/paddlex/licenses \
-v /dev/disk/by-uuid:/dev/disk/by-uuid \
-w /workspace \
- -e PADDLEX_HPS_DEVICE_TYPE={deployment device type} \
- -e PADDLEX_HPS_SERIAL_NUMBER={serial number} \
--rm \
--gpus all \
--network host \
--shm-size 8g \
{image name} \
- ./server.sh
+ /bin/bash server.sh
```
- The deployment device type can be `cpu` or `gpu`, and the CPU-only image supports only `cpu`.
- If CPU deployment is required, there is no need to specify `--gpus`.
- The above commands can only be executed properly after successful activation. PaddleX offers two activation methods: online activation and offline activation. They are detailed as follows:
- - Online activation: Add `-e PADDLEX_HPS_UPDATE_LICENSE=1` to the command to enable the program to complete activation automatically.
- - Offline Activation: Follow the instructions in the serial number management section to obtain the machine’s device fingerprint. Bind the serial number with the device fingerprint to obtain the certificate and complete the activation. For this activation method, you need to manually place the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (if the directory does not exist, you will need to create it).
+ - Online activation: Set `PADDLEX_HPS_UPDATE_LICENSE` to `1` for the first execution to enable the program to automatically update the license and complete activation. When executing the command again, you may set `PADDLEX_HPS_UPDATE_LICENSE` to `0` to avoid online license updates.
+ - Offline Activation: Follow the instructions in the serial number management section to obtain the machine’s device fingerprint. Bind the serial number with the device fingerprint to obtain the certificate and complete the activation. For this activation method, you need to manually place the certificate in the `${HOME}/.baidu/paddlex/licenses` directory on the machine (if the directory does not exist, you will need to create it). When using this method, set `PADDLEX_HPS_UPDATE_LICENSE` to `0` to avoid online license updates.
- It is necessary to ensure that the `/dev/disk/by-uuid` directory on the host machine exists and is not empty, and that this directory is correctly mounted in order to perform activation properly.
-- If you need to enter the container for debugging, you can replace ``./server.sh` in the command with `/bin/bash`. Then execute `./server.sh` inside the container.
+- If you need to enter the container for debugging, you can replace `/bin/bash server.sh` in the command with `/bin/bash`. Then execute `/bin/bash server.sh` inside the container.
- If you want the server to run in the background, you can replace `-it` in the command with `-d`. After the container starts, you can view the container logs with `docker logs -f {container ID}`.
+- Add `-e PADDLEX_USE_HPIP=1` to use the PaddleX high-performance inference plugin to accelerate the pipeline inference process. However, please note that not all pipelines support using the high-performance inference plugin. Please refer to the [PaddleX High-Performance Inference Guide](./high_performance_inference.en.md) for more information.
You may observe output similar to the following:
@@ -367,8 +369,8 @@ Navigate to the `client` directory of the high-stability serving SDK, and run th
```bash
# It is recommended to install in a virtual environment
-python -m pip install paddlex_hps_client-*.whl
python -m pip install -r requirements.txt
+python -m pip install paddlex_hps_client-*.whl
```
The `client.py` script in the `client` directory contains examples of how to call the service and provides a command-line interface.
diff --git a/docs/pipeline_deploy/serving.md b/docs/pipeline_deploy/serving.md
index 04782dc2f5..a8221d5497 100644
--- a/docs/pipeline_deploy/serving.md
+++ b/docs/pipeline_deploy/serving.md
@@ -128,7 +128,7 @@ paddlex --serve --pipeline image_classification --use_hpip
| 通用图像分类 |
-paddlex_hps_image_classification.tar.gz |
+paddlex_hps_image_classification_sdk.tar.gz |
| 通用目标检测 |
@@ -263,7 +263,7 @@ paddlex --serve --pipeline image_classification --use_hpip
-**请注意**:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署产线,则必须为每台机器准备单独的序列号。
+**请注意**:每个序列号只能绑定到唯一的设备指纹,且只能绑定一次。这意味着用户如果使用不同的机器部署产线,则必须为每台机器准备单独的序列号。**高稳定性服务化部署完全免费。**PaddleX 的鉴权机制核心在于统计各产线的部署数量,并通过数据建模为团队提供产线效能分析,以便进行资源的优化配置和重点产线效率的提升。需要特别说明的是,鉴权过程只使用硬盘分区 UUID 等非敏感信息,PaddleX 也并不采集设备遥测数据等敏感数据,因此理论上**鉴权服务器无法获取到任何敏感信息**。
### 2.3 调整配置
@@ -327,30 +327,32 @@ PaddleX 高稳定性服务化部署方案基于 NVIDIA Triton Inference Server
```bash
docker run \
-it \
+ -e PADDLEX_HPS_DEVICE_TYPE={部署设备类型} \
+ -e PADDLEX_HPS_SERIAL_NUMBER={序列号} \
+ -e PADDLEX_HPS_UPDATE_LICENSE=1 \
-v "$(pwd)":/workspace \
-v "${HOME}/.baidu/paddlex/licenses":/root/.baidu/paddlex/licenses \
-v /dev/disk/by-uuid:/dev/disk/by-uuid \
-w /workspace \
- -e PADDLEX_HPS_DEVICE_TYPE={部署设备类型} \
- -e PADDLEX_HPS_SERIAL_NUMBER={序列号} \
--rm \
--gpus all \
--network host \
--shm-size 8g \
{镜像名称} \
- ./server.sh
+ /bin/bash server.sh
```
- 部署设备类型可以为 `cpu` 或 `gpu`,CPU-only 镜像仅支持 `cpu`。
- 如果希望使用 CPU 部署,则不需要指定 `--gpus`。
- 以上命令必须在激活成功后才可以正常执行。PaddleX 提供两种激活方式:离线激活和在线激活。具体说明如下:
- - 联网激活:在命令中添加 `-e PADDLEX_HPS_UPDATE_LICENSE=1`,使程序自动完成激活。
- - 离线激活:按照序列号管理部分中的指引,获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录)。
+ - 联网激活:在第一次执行时设置 `PADDLEX_HPS_UPDATE_LICENSE` 为 `1`,使程序自动更新证书并完成激活。再次执行命令时可以将 `PADDLEX_HPS_UPDATE_LICENSE` 设置为 `0` 以避免联网更新证书。
+ - 离线激活:按照序列号管理部分中的指引,获取机器的设备指纹,并将序列号与设备指纹绑定以获取证书,完成激活。使用这种激活方式,需要手动将证书存放在机器的 `${HOME}/.baidu/paddlex/licenses` 目录中(如果目录不存在,需要创建目录)。使用这种方式时,将 `PADDLEX_HPS_UPDATE_LICENSE` 设置为 `0` 以避免联网更新证书。
- 必须确保宿主机的 `/dev/disk/by-uuid` 存在且非空,并正确挂载该目录,才能正常执行激活。
-- 如果需要进入容器内部调试,可以将命令中的 `./server.sh` 替换为 `/bin/bash`,在容器中执行 `./server.sh`。
+- 如果需要进入容器内部调试,可以将命令中的 `/bin/bash server.sh` 替换为 `/bin/bash`,然后在容器中执行 `/bin/bash server.sh`。
- 如果希望服务器在后台运行,可以将命令中的 `-it` 替换为 `-d`。容器启动后,可通过 `docker logs -f {容器 ID}` 查看容器日志。
+- 在命令中添加 `-e PADDLEX_USE_HPIP=1` 可以使用 PaddleX 高性能推理插件加速产线推理过程。但请注意,并非所有产线都支持使用高性能推理插件。请参考 [PaddleX 高性能推理指南](./high_performance_inference.md) 获取更多信息。
可观察到类似下面的输出信息:
@@ -368,8 +370,8 @@ I1216 11:37:21.643494 35 http_server.cc:167] Started Metrics Service at 0.0.0.0:
```bash
# 建议在虚拟环境中安装
-python -m pip install paddlex_hps_client-*.whl
python -m pip install -r requirements.txt
+python -m pip install paddlex_hps_client-*.whl
```
`client` 目录的 `client.py` 脚本包含服务的调用示例,并提供命令行接口。
diff --git a/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.en.md b/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.en.md
index 326ccfc4ea..e9591a4550 100644
--- a/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.en.md
+++ b/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.en.md
@@ -718,9 +718,9 @@ Below is the API reference for basic service deployment and multi-language servi
The key corresponding to the index, used to identify the created index. It can be used as input for other operations. |
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -791,9 +791,9 @@ Below is the API reference for basic service deployment and multi-language servi
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -842,9 +842,9 @@ Below is the API reference for basic service deployment and multi-language servi
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -1014,7 +1014,7 @@ if resp_index_build.status_code != 200:
pprint.pp(resp_index_build.json())
sys.exit(1)
result_index_build = resp_index_build.json()["result"]
-print(f"Number of images indexed: {len(result_index_build['idMap'])}")
+print(f"Number of images indexed: {result_index_build['imageCount']}")
for pair in image_label_pairs_to_add:
with open(pair["image"], "rb") as file:
@@ -1029,7 +1029,7 @@ if resp_index_add.status_code != 200:
pprint.pp(resp_index_add.json())
sys.exit(1)
result_index_add = resp_index_add.json()["result"]
-print(f"Number of images indexed: {len(result_index_add['idMap'])}")
+print(f"Number of images indexed: {result_index_add['imageCount']}")
payload = {"ids": ids_to_remove, "indexKey": result_index_build["indexKey"]}
resp_index_remove = requests.post(f"{API_BASE_URL}/face-recognition-index-remove", json=payload)
@@ -1038,7 +1038,7 @@ if resp_index_remove.status_code != 200:
pprint.pp(resp_index_remove.json())
sys.exit(1)
result_index_remove = resp_index_remove.json()["result"]
-print(f"Number of images indexed: {len(result_index_remove['idMap'])}")
+print(f"Number of images indexed: {result_index_remove['imageCount']}")
with open(infer_image_path, "rb") as file:
image_bytes = file.read()
diff --git a/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.md b/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.md
index 0f22a43fb4..88d973ddec 100644
--- a/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.md
+++ b/docs/pipeline_usage/tutorials/cv_pipelines/face_recognition.md
@@ -714,9 +714,9 @@ data_root # 数据集根目录,目录名称可以改变
索引对应的键,用于标识建立的索引。可用作其他操作的输入。 |
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -787,9 +787,9 @@ data_root # 数据集根目录,目录名称可以改变
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -838,9 +838,9 @@ data_root # 数据集根目录,目录名称可以改变
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -1011,7 +1011,7 @@ if resp_index_build.status_code != 200:
pprint.pp(resp_index_build.json())
sys.exit(1)
result_index_build = resp_index_build.json()["result"]
-print(f"Number of images indexed: {len(result_index_build['idMap'])}")
+print(f"Number of images indexed: {result_index_build['imageCount']}")
for pair in image_label_pairs_to_add:
with open(pair["image"], "rb") as file:
@@ -1026,7 +1026,7 @@ if resp_index_add.status_code != 200:
pprint.pp(resp_index_add.json())
sys.exit(1)
result_index_add = resp_index_add.json()["result"]
-print(f"Number of images indexed: {len(result_index_add['idMap'])}")
+print(f"Number of images indexed: {result_index_add['imageCount']}")
payload = {"ids": ids_to_remove, "indexKey": result_index_build["indexKey"]}
resp_index_remove = requests.post(f"{API_BASE_URL}/face-recognition-index-remove", json=payload)
@@ -1035,7 +1035,7 @@ if resp_index_remove.status_code != 200:
pprint.pp(resp_index_remove.json())
sys.exit(1)
result_index_remove = resp_index_remove.json()["result"]
-print(f"Number of images indexed: {len(result_index_remove['idMap'])}")
+print(f"Number of images indexed: {result_index_remove['imageCount']}")
with open(infer_image_path, "rb") as file:
image_bytes = file.read()
diff --git a/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.en.md b/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.en.md
index d8d843687c..f1e5102ddd 100644
--- a/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.en.md
+++ b/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.en.md
@@ -679,9 +679,9 @@ Below is the API reference for basic service deployment and multi-language servi
The key corresponding to the index, used to identify the created index. It can be used as input for other operations. |
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -752,9 +752,9 @@ Below is the API reference for basic service deployment and multi-language servi
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -803,9 +803,9 @@ Below is the API reference for basic service deployment and multi-language servi
-idMap |
-object |
-Mapping from vector IDs to labels. |
+imageCount |
+integer |
+The number of images indexed. |
@@ -975,7 +975,7 @@ if resp_index_build.status_code != 200:
pprint.pp(resp_index_build.json())
sys.exit(1)
result_index_build = resp_index_build.json()["result"
-print(f"Number of images indexed: {len(result_index_build['idMap'])}")
+print(f"Number of images indexed: {result_index_build['imageCount']}")
for pair in image_label_pairs_to_add:
with open(pair["image"], "rb") as file:
@@ -990,7 +990,7 @@ if resp_index_add.status_code != 200:
pprint.pp(resp_index_add.json())
sys.exit(1)
result_index_add = resp_index_add.json()["result"]
-print(f"Number of images indexed: {len(result_index_add['idMap'])}")
+print(f"Number of images indexed: {result_index_add['imageCount']}")
payload = {"ids": ids_to_remove, "indexKey": result_index_build["indexKey"]}
resp_index_remove = requests.post(f"{API_BASE_URL}/shitu-index-remove", json=payload)
@@ -999,7 +999,7 @@ if resp_index_remove.status_code != 200:
pprint.pp(resp_index_remove.json())
sys.exit(1)
result_index_remove = resp_index_remove.json()["result"]
-print(f"Number of images indexed: {len(result_index_remove['idMap'])}")
+print(f"Number of images indexed: {result_index_remove['imageCount']}")
with open(infer_image_path, "rb") as file:
image_bytes = file.read()
diff --git a/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.md b/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.md
index 750957761c..92bc82632d 100644
--- a/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.md
+++ b/docs/pipeline_usage/tutorials/cv_pipelines/general_image_recognition.md
@@ -676,9 +676,9 @@ data_root # 数据集根目录,目录名称可以改变
索引对应的键,用于标识建立的索引。可用作其他操作的输入。 |
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -749,9 +749,9 @@ data_root # 数据集根目录,目录名称可以改变
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -800,9 +800,9 @@ data_root # 数据集根目录,目录名称可以改变
-idMap |
-object |
-向量ID到标签的映射。 |
+imageCount |
+integer |
+索引的图像数量。 |
@@ -973,7 +973,7 @@ if resp_index_build.status_code != 200:
pprint.pp(resp_index_build.json())
sys.exit(1)
result_index_build = resp_index_build.json()["result"]
-print(f"Number of images indexed: {len(result_index_build['idMap'])}")
+print(f"Number of images indexed: {result_index_build['imageCount']}")
for pair in image_label_pairs_to_add:
with open(pair["image"], "rb") as file:
@@ -988,7 +988,7 @@ if resp_index_add.status_code != 200:
pprint.pp(resp_index_add.json())
sys.exit(1)
result_index_add = resp_index_add.json()["result"]
-print(f"Number of images indexed: {len(result_index_add['idMap'])}")
+print(f"Number of images indexed: {result_index_add['imageCount']}")
payload = {"ids": ids_to_remove, "indexKey": result_index_build["indexKey"]}
resp_index_remove = requests.post(f"{API_BASE_URL}/shitu-index-remove", json=payload)
@@ -997,7 +997,7 @@ if resp_index_remove.status_code != 200:
pprint.pp(resp_index_remove.json())
sys.exit(1)
result_index_remove = resp_index_remove.json()["result"]
-print(f"Number of images indexed: {len(result_index_remove['idMap'])}")
+print(f"Number of images indexed: {result_index_remove['imageCount']}")
with open(infer_image_path, "rb") as file:
image_bytes = file.read()
diff --git a/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.en.md b/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.en.md
index a086690e98..7d6c7bf596 100644
--- a/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.en.md
+++ b/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.en.md
@@ -1641,6 +1641,16 @@ Below is the API reference for basic service-oriented deployment and examples of
object |
A key-value pair of relative paths of Markdown images and Base64-encoded images. |
+
+isStart |
+boolean |
+Whether the first element on the current page is the start of a segment. |
+
+
+isEnd |
+boolean |
+Whether the last element on the current page is the end of a segment. |
+
diff --git a/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.md b/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.md
index 04bc6e9f62..f5a8493f4c 100644
--- a/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.md
+++ b/docs/pipeline_usage/tutorials/ocr_pipelines/layout_parsing_v2.md
@@ -1527,6 +1527,16 @@ for res in output:
object |
Markdown图片相对路径和base64编码图像的键值对。 |
+
+isStart |
+boolean |
+当前页面第一个元素是否为段开始。 |
+
+
+isEnd |
+boolean |
+当前页面最后一个元素是否为段结束。 |
+
多语言调用服务示例
diff --git a/libs/paddlex-hpi/src/paddlex_hpi/model_info_collection.json b/libs/paddlex-hpi/src/paddlex_hpi/model_info_collection.json
index 24a209c4bf..0be9168d4c 100644
--- a/libs/paddlex-hpi/src/paddlex_hpi/model_info_collection.json
+++ b/libs/paddlex-hpi/src/paddlex_hpi/model_info_collection.json
@@ -8204,6 +8204,19 @@
},
"PP-OCRv4_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8212,6 +8225,19 @@
},
"PP-OCRv4_server_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8220,6 +8246,19 @@
},
"ch_SVTRv2_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8228,6 +8267,19 @@
},
"ch_RepSVTR_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8236,6 +8288,19 @@
},
"PP-OCRv4_server_rec_doc": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8244,6 +8309,19 @@
},
"ta_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8252,6 +8330,19 @@
},
"latin_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8260,6 +8351,19 @@
},
"chinese_cht_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8268,6 +8372,19 @@
},
"ka_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8276,6 +8393,19 @@
},
"PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8284,6 +8414,19 @@
},
"korean_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8292,6 +8435,19 @@
},
"en_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8300,6 +8456,19 @@
},
"devanagari_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8308,6 +8477,19 @@
},
"te_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8316,6 +8498,19 @@
},
"en_PP-OCRv4_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8324,6 +8519,19 @@
},
"arabic_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8332,6 +8540,19 @@
},
"japan_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
@@ -8340,6 +8561,19 @@
},
"cyrillic_PP-OCRv3_mobile_rec": {
"backend_config_pairs": [
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true,
+ "trt_precision": "FP16"
+ }
+ ],
+ [
+ "paddle_infer",
+ {
+ "enable_trt": true
+ }
+ ],
[
"paddle_infer",
{}
diff --git a/paddlex/hpip_links.html b/paddlex/hpip_links.html
new file mode 100644
index 0000000000..5a974fc1e0
--- /dev/null
+++ b/paddlex/hpip_links.html
@@ -0,0 +1,15 @@
+
+
+
+ PaddleX HPIP Links
+
+
+
+
+
+
+
+
+
+
+
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/face_recognition.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/face_recognition.py
index ed9371d887..ee1566de13 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/face_recognition.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/face_recognition.py
@@ -76,7 +76,9 @@ async def _build_index(
return ResultResponse[schema.BuildIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.BuildIndexResult(indexKey=index_key, idMap=index_data.id_map),
+ result=schema.BuildIndexResult(
+ indexKey=index_key, imageCount=len(index_data.id_map)
+ ),
)
@primary_operation(
@@ -116,7 +118,7 @@ async def _add_images_to_index(
return ResultResponse[schema.AddImagesToIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.AddImagesToIndexResult(idMap=index_data.id_map),
+ result=schema.AddImagesToIndexResult(imageCount=len(index_data.id_map)),
)
@primary_operation(
@@ -146,7 +148,9 @@ async def _remove_images_from_index(
return ResultResponse[schema.RemoveImagesFromIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.RemoveImagesFromIndexResult(idMap=index_data.id_map),
+ result=schema.RemoveImagesFromIndexResult(
+ imageCount=len(index_data.id_map)
+ ),
)
@primary_operation(
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing_v2.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing_v2.py
index 8c3e3aa933..10e0b06971 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing_v2.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/layout_parsing_v2.py
@@ -86,6 +86,7 @@ async def _infer(
return_urls=ctx.extra["return_img_urls"],
max_img_size=ctx.extra["max_output_img_size"],
)
+ md_flags = md_data["page_continuation_flags"]
if ctx.config.visualize:
imgs = {
"input_img": img,
@@ -105,7 +106,12 @@ async def _infer(
layout_parsing_results.append(
dict(
prunedResult=pruned_res,
- markdown=dict(text=md_text, images=md_imgs),
+ markdown=dict(
+ text=md_text,
+ images=md_imgs,
+ isStart=md_flags[0],
+ isEnd=md_flags[1],
+ ),
outputImages=(
{k: v for k, v in imgs.items() if k != "input_img"}
if imgs
diff --git a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_shituv2.py b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_shituv2.py
index a32b05bb21..f17c8ec9d0 100644
--- a/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_shituv2.py
+++ b/paddlex/inference/serving/basic_serving/_pipeline_apps/pp_shituv2.py
@@ -71,7 +71,9 @@ async def _build_index(
return ResultResponse[schema.BuildIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.BuildIndexResult(indexKey=index_key, idMap=index_data.id_map),
+ result=schema.BuildIndexResult(
+ indexKey=index_key, imageCount=len(index_data.id_map)
+ ),
)
@primary_operation(
@@ -111,7 +113,7 @@ async def _add_images_to_index(
return ResultResponse[schema.AddImagesToIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.AddImagesToIndexResult(idMap=index_data.id_map),
+ result=schema.AddImagesToIndexResult(imageCount=len(index_data.id_map)),
)
@primary_operation(
@@ -141,7 +143,9 @@ async def _remove_images_from_index(
return ResultResponse[schema.RemoveImagesFromIndexResult](
logId=serving_utils.generate_log_id(),
- result=schema.RemoveImagesFromIndexResult(idMap=index_data.id_map),
+ result=schema.RemoveImagesFromIndexResult(
+ imageCount=len(index_data.id_map)
+ ),
)
@primary_operation(
@@ -184,7 +188,7 @@ async def _infer(
objs: List[Dict[str, Any]] = []
for obj in result["boxes"]:
rec_results: List[Dict[str, Any]] = []
- if obj["rec_scores"] is not None:
+ if obj["rec_scores"] != [None]:
for label, score in zip(obj["labels"], obj["rec_scores"]):
rec_results.append(
dict(
diff --git a/paddlex/inference/serving/schemas/face_recognition.py b/paddlex/inference/serving/schemas/face_recognition.py
index a635b1fe22..765d54785b 100644
--- a/paddlex/inference/serving/schemas/face_recognition.py
+++ b/paddlex/inference/serving/schemas/face_recognition.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict, Final, List, Optional
+from typing import Final, List, Optional
from pydantic import BaseModel
@@ -53,7 +53,7 @@ class BuildIndexRequest(BaseModel):
class BuildIndexResult(BaseModel):
indexKey: str
- idMap: Dict[int, str]
+ imageCount: int
ADD_IMAGES_TO_INDEX_ENDPOINT: Final[str] = "/face-recognition-index-add"
@@ -65,7 +65,7 @@ class AddImagesToIndexRequest(BaseModel):
class AddImagesToIndexResult(BaseModel):
- idMap: Dict[int, str]
+ imageCount: int
REMOVE_IMAGES_FROM_INDEX_ENDPOINT: Final[str] = "/face-recognition-index-remove"
@@ -77,7 +77,7 @@ class RemoveImagesFromIndexRequest(BaseModel):
class RemoveImagesFromIndexResult(BaseModel):
- idMap: Dict[int, str]
+ imageCount: int
INFER_ENDPOINT: Final[str] = "/face-recognition-infer"
diff --git a/paddlex/inference/serving/schemas/layout_parsing_v2.py b/paddlex/inference/serving/schemas/layout_parsing_v2.py
index b1991b9136..b060698de5 100644
--- a/paddlex/inference/serving/schemas/layout_parsing_v2.py
+++ b/paddlex/inference/serving/schemas/layout_parsing_v2.py
@@ -63,6 +63,8 @@ class InferRequest(ocr.BaseInferRequest):
class MarkdownData(BaseModel):
text: str
images: Dict[str, str]
+ isStart: bool
+ isEnd: bool
class LayoutParsingResult(BaseModel):
diff --git a/paddlex/inference/serving/schemas/pp_shituv2.py b/paddlex/inference/serving/schemas/pp_shituv2.py
index 4d5943b28d..d7ad84eb48 100644
--- a/paddlex/inference/serving/schemas/pp_shituv2.py
+++ b/paddlex/inference/serving/schemas/pp_shituv2.py
@@ -12,7 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-from typing import Dict, Final, List, Optional
+from typing import Final, List, Optional
from pydantic import BaseModel
@@ -53,7 +53,7 @@ class BuildIndexRequest(BaseModel):
class BuildIndexResult(BaseModel):
indexKey: str
- idMap: Dict[int, str]
+ imageCount: int
ADD_IMAGES_TO_INDEX_ENDPOINT: Final[str] = "/shitu-index-add"
@@ -65,7 +65,7 @@ class AddImagesToIndexRequest(BaseModel):
class AddImagesToIndexResult(BaseModel):
- idMap: Dict[int, str]
+ imageCount: int
REMOVE_IMAGES_FROM_INDEX_ENDPOINT: Final[str] = "/shitu-index-remove"
@@ -77,7 +77,7 @@ class RemoveImagesFromIndexRequest(BaseModel):
class RemoveImagesFromIndexResult(BaseModel):
- idMap: Dict[int, str]
+ imageCount: int
INFER_ENDPOINT: Final[str] = "/shitu-infer"
diff --git a/paddlex/paddlex_cli.py b/paddlex/paddlex_cli.py
index e3bd77410d..80c178b354 100644
--- a/paddlex/paddlex_cli.py
+++ b/paddlex/paddlex_cli.py
@@ -14,13 +14,12 @@
import os
import argparse
+import importlib.resources
import subprocess
import sys
import shutil
from pathlib import Path
-from importlib_resources import files, as_file
-
from . import create_pipeline
from .inference.pipelines import load_pipeline_config
from .repo_manager import setup, get_all_supported_repo_names
@@ -144,6 +143,7 @@ def parse_str(s):
default=8080,
help="Port number to serve on (default: 8080).",
)
+ # Serving also uses `--pipeline`, `--device`, and `--use_hpip`
################# paddle2onnx #################
paddle2onnx_group.add_argument(
@@ -200,14 +200,16 @@ def install(args):
"""install paddlex"""
def _install_serving_deps():
- with as_file(files("paddlex").joinpath("serving_requirements.txt")) as req_file:
+ with importlib.resources.path(
+ "paddlex", "serving_requirements.txt"
+ ) as req_file:
return subprocess.check_call(
[sys.executable, "-m", "pip", "install", "-r", str(req_file)]
)
def _install_paddle2onnx_deps():
- with as_file(
- files("paddlex").joinpath("paddle2onnx_requirements.txt")
+ with importlib.resources.path(
+ "paddlex", "paddle2onnx_requirements.txt"
) as req_file:
return subprocess.check_call(
[sys.executable, "-m", "pip", "install", "-r", str(req_file)]
@@ -226,18 +228,22 @@ def _install_hpi_deps(device_type):
sys.exit(2)
if device_type == "cpu":
- packages = ["ultra_infer_python", "paddlex_hpi"]
+ packages = ["ultra-infer-python", "paddlex-hpi"]
elif device_type == "gpu":
- packages = ["ultra_infer_gpu_python", "paddlex_hpi"]
-
- return subprocess.check_call(
- [sys.executable, "-m", "pip", "install"]
- + packages
- + [
- "--find-links",
- "https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/pipeline_deploy/high_performance_inference.md",
- ]
- )
+ packages = ["ultra-infer-gpu-python", "paddlex-hpi"]
+
+ with importlib.resources.path("paddlex", "hpip_links.html") as f:
+ return subprocess.check_call(
+ [
+ sys.executable,
+ "-m",
+ "pip",
+ "install",
+ "--find-links",
+ str(f),
+ *packages,
+ ]
+ )
# Enable debug info
os.environ["PADDLE_PDX_DEBUG"] = "True"
diff --git a/requirements.txt b/requirements.txt
index 4bd07bb803..181f494079 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -32,7 +32,6 @@ premailer
PyMuPDF
ujson
Pillow
-importlib_resources>=6.4
######## For Chatocrv3 #######
langchain==0.2.17
langchain-community==0.2.17
diff --git a/setup.py b/setup.py
index 6b4ef6c591..a9cfcd46ef 100644
--- a/setup.py
+++ b/setup.py
@@ -82,6 +82,7 @@ def _recursively_find(pattern, exts=None):
pkg_data.append("repo_manager/requirements.txt")
pkg_data.append("serving_requirements.txt")
pkg_data.append("paddle2onnx_requirements.txt")
+ pkg_data.append("hpip_links.html")
return pkgs, {"paddlex": pkg_data}