-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathsql-study-day10-jimin
747 lines (698 loc) · 33.4 KB
/
sql-study-day10-jimin
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
## 07-1 하나의 열에 출력 결과를 담는 다중행 함수
- **다중행 함수**(multiple-row function)? **여러 행**을 바탕으로 **하나의 결과 값(하나의 행)**을 도출해내기 위해 사용하는 함수
- 다중행 함수 = 그룹 함수 = 복수행 함수
- sum 함수를 통해 급여 합계 출력하기
```sql
SELECT SUM(SAL)
FROM EMP;
```
- sum 함수는 **SELECT문으로 조회된 행**에 **지정한 열 값을 모두 더한 값**을 반환해주는 함수이다.
- 다중행 함수를 사용한 SELECT절에는 기본적으로 여러 행이 결과로 나올 수 있는 열을 함꼐 사용할 수 없다.
==> 다음과 같은 SELECT문은 실행되지 못하고 오류가 발생한다.
```sql
SELECT ENAME, SUM(SAL)
FROM EMP;
```
- 결과 값이 **한 행**으로 나온 데이터 SUM(SAL)과 **여러 행**이 나올 수 있는 데이터(ENAME)을 **함께 명시**했기 때문에 **오류**가 발생한다.
- 다중행 함수들
|함수|설명|
|:----------:|-------------------|
|SUM|지정한 데이터의 합 반환|
|COUNT|지정한 데이터의 개수 반환|
|MAX|지정한 데이터 중 최댓값 반환|
|MIN|지정한 데이터 중 최솟값 반환|
|AVG|지정한 데이터의 평균값 반환|
### - 합계를 구하는 SUM 함수
- SUM함수는 데이터의 합을 구하는 함수이다.
- 기본 형식
```sql
SUM([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[합계를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
```
- SUM함수를 분석하는 용도로 사용한다면 다음과 같이 함수를 작성한 후 OVER절을 사용할 수도 있다.
```sql
SUM([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[합계를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법을 지정)(선택)
```
- 추가 수당 합계 구하기
- 추가 수당 열은 NULL이 존재하는 열이다.
- 따라서 덧셈(+)연산만으로 합계를 구했다면 결과는 NULL이 나왔을 것이다.
- 하지만 , **SUM 함수는 NULL 데이터는 자동으로 제외**하고 합계를 구하므로 별다른 문제 없이 결과를 출력받을 수 있다.
```sql
SELECT SUM(COMM)
FROM EMP;
```
#### -- SUM함수와 DISTINCT, ALL 함께 사용하기
- SUM 함수를 작성할 떄 생략 가능 옵션 DISTINCT, ALL을 사용한 결과 비교하기
- 급여 합계 구하기(DISTINCT, ALL 사용)
```sql
SELECT SUM(DISTINCT SAL),
SUM(ALL SAL),
SUM(SAL)
FROM EMP;
```
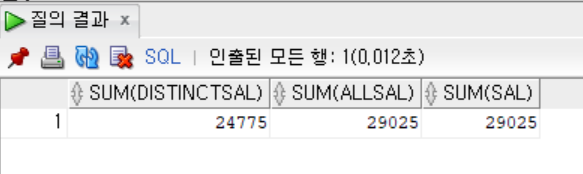
- ALL을 사용한 SUM함수의 결과 == 아무 옵션을 지정하지 않은 SUM함수의 결과
- DISTINCT를 지정하면 중복 데이터가 제거 되고 합계가 계산되기에, 다른 값이 나오게 된다.
- 하지만, 일반적으로 합계를 구할 때 같은 값을 제외하는 경우는 많지 않다.
### - 데이터의 개수를 구해 주는 COUNT 함수
- COUNT 함수는 **데이터의 개수**를 출력하는데 사용한다.
- COUNT 함수에 *을 사용하면 **SELECT문의 결과 값으로 나온 행 데이터의 개수**를 반환해준다.
- 기본 형식
```sql
COUNT([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[개수를 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법 지정)(선택)
```
- SUM함수에서와 마찬가지로 DISTINCT나 ALL을 사용하여 특정 데이터 또는 열을 지정할 수 있다.
- 옵션을 지정하지 않았을 경우, 중복을 허용하여 결과 값을 반환하는 ALL을 기본으로 한다.
- EMP 테이블의 데이터 개수 출력하기(사원수, 행 수)
```sql
SELECT COUNT(*)
FROM EMP;
```
- WHERE절의 조건식을 함께 사용하면 유용하게 사용할 수 있다.
- 부서 번호가 30번인 직원 수 구하기
```sql
SELECT COUNT(*)
FROM EMP
WHERE DEPTNO = 30;
```
- 특정 조건을 만족하는 데이터를 COUNT함수와 함꼐 사용한 결과 값은 다양한 분야에서 활용할 수 있다.
- 웹 커뮤니티
- 특정회원이 작성한 총 글수, 댓글 수, 글에서 받은 찬성 수, 반대 수 등을 조합
--> 어떤 상품이 많이 구매 되었는지 분석 가능
--> 화면의 어느 위치에 있는 항목이 자주 선택되었는지 분석 가능
#### -- COUNT함수와 DISTINCT, ALL 함께 사용하기
```sql
SELECT COUNT(DISTINCT SAL),
COUNT(ALL SAL),
COUNT(SAL)
FROM EMP;
```
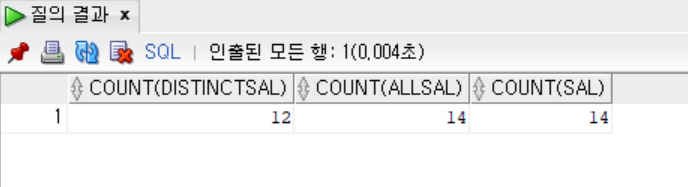
- COUNT 함수를 사용하면 NULL이 데이터로 포함되어 있을 경우, NULL 데이터는 반환 개수에서 제외된다.
- COUNT 함수를 사용하여 추가 수당 열 개수 출력하기
```sql
SELECT COUNT(COMM)
FROM EMP;
```

- COUNT 함수와 IS NOT NULL을 사용하여 추가 수당 열 개수 출력하기
```sql
SELECT COUNT(COMM)
FROM EMP
WHERE COMM IS NOT NULL;
```
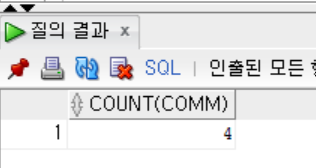
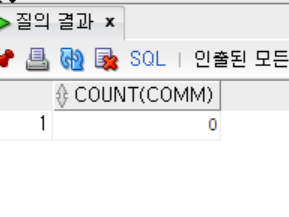
- COUNT 함수와 IS NULL을 사용하는 경우
```sql
SELECT COUNT(COMM)
FROM EMP
WHERE COMM IS NULL;
```
### - 최댓값과 최솟값을 구하는 MAX, MIN 함수
- MAX함수와 MIN함수는 단어 의미 그대로 입력 데이터 중 최댓값과 최솟값을 반환하는 함수이다.
- MAX의 기본형식
```sql
MAX([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[최댓값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법 지정)(선택)
```
- MIN의 기본형식
```sql
MIN([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[최솟값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법 지정)(선택)
```
#### -- 숫자 데이터에 MAX, MIN 함수 사용하기
- MAX와 MIN 함수도 DISTINCT나 ALL을 지정할 수 있지만 최댓값과 최솟값은 중복 제거와 무관하기 때문에 실제로는 지정하지 않는다.
- 부서 번호가 10번인 사원들의 최대 급여 출력하기
```sql
SELECT MAX(SAL)
FROM EMP
WHERE DEPTNO = 10;
```
- 부서 번호가 10번인 사원들의 최소 급여 출력하기
```sql
SELECT MIN(SAL)
FROM EMP
WHERE DEPTNO = 10;
```
#### -- 날짜 데이터에 MAX, MIN 함수 사용하기
- 오라클 데이터베이스에서는 날짜 및 문자 데이터 크기 비교가 가능하다.
- 최근 == 연도가 큼
- 오래됨 == 연도가 작음
- 부서 번호가 20인 사원의 입사일 중 제일 최근 입사일 출력하기
```sql
SELECT MAX(HIREDATE)
FROM EMP
WHERE DEPTNO=20;
```
- 부서 번호가 20인 사원의 입사일 중 제일 오래된 입사일 출력하기
```sql
SELECT MIN(HIREDATE)
FROM EMP
WHERE DEPTNO=20;
```
## - 평균값을 구하는 AVG 함수
- AVG함수는 입력 데이터의 평균 값을 구하는 함수이다.
- 숫자 또는 숫자로 암시적 형 변환이 가능한 데이터만 사용할 수 있다.
- 기본 형식
```sql
AVG([DISTINCT, ALL 중 하나를 선택하거나
아무 값도 지정하지 않음(선택)]
[평균값을 구할 열이나 연산자, 함수를 사용한 데이터(필수)])
OVER(분석을 위한 여러 문법 지정)(선택)
```
- 부서 번호가 30인 사원들의 평균 급여 출력하기
```sql
SELECT AVG(SAL)
FROM EMP
WHERE DEPTNO=30;
```

- 자주 사용하는 방식은 아니지만, DISTINCT를 지정하면 중복 값을 제외하고 평균값을 구하므로 결과 값이 달라질 수 있다.
- DISTINCT를 지정하지 않으면 중복을 허용하는 ALL이 기본값이다.
- DISTINCT로 중복을 제거한 부서 30인 사원들의 급여 열의 평균 급여 구하기
```sql
SELECT AVG(DISTINCT SAL)
FROM EMP
WHERE DEPTNO=30;
```

## 07-2 결과 값을 원하는 열로 묶어 출력하는 GROUP BY절
- 다중행 함수는 지정 테이블의 데이터를 가공하여 하나의 결과 값만 출력한다.
- DEPTNO 열 값별로 급여의 평균 값을 구하려면 각 부서 평균 값을 구하기 위해 SELECT문을 다음과 같이 하나하나 제작해야 한다.
```sql
SELECT AVG(SAL) FROM EMP WHERE DEPTNO = 10;
SELECT AVG(SAL) FROM EMP WHERE DEPTNO = 20;
SELECT AVG(SAL) FROM EMP WHERE DEPTNO = 30;
```
- 위의 결과 값을 하나로 통합해서 보려면 집합 연산자를 다음과 같이 활용 할 수 있다.
```sql
SELECT AVG(SAL), '10' AS DEPTNO FROM EMP WHERE DEPTNO = 10
UNION ALL
SELECT AVG(SAL), '20' AS DEPTNO FROM EMP WHERE DEPTNO = 20
UNION ALL
SELECT AVG(SAL), '30' AS DEPTNO FROM EMP WHERE DEPTNO = 30;
```

- AVG 함수 옆에 부서 코드를 열을 바로 붙일 수 없기 때문에 10, 20, 30을 직접 작성하여 별칭을 준다.
--> 필요에 따라 이런 식으로 데이터를 강제로 넣어 결과 열에 명시하기도 한다.
- 하지만 위와 같은 방식은 번거롭기도 하고, 이후 특정 부서를 추가하거나 삭제할 때마다 SQL문을 수정해야 하므로 바람직하지 않다.
### - GROUP BY절의 기본 사용법
- **그룹화**? 여러 데이터에서 **의미 있는 하나의 결과**를 **특정 열 값별로** 묶어서 출력할 데이터
- SELECT문에서는 GROUP BY절을 작성하여 데이터를 그룹화 할 수 있다.
- 다음과 같이 순서에 맞게 장성하며 그룹으로 묶을 기준 열을 지정한다.
- **순서:
SELECT > FROM > WHERE > GROUP BY > ORDER BY**
- 기본형식
```sql
SELECT [조회할 열1 이름], [열2 이름], ..., [열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러개 지정 가능)]
ORDER BY [정렬하려는 열 지정]
```
- GROUP BY절에 명시하는 열은 여러 개 지정할 수 있다.
- 먼저 지정한 열로 대그룹을 나누고 그 다움 지정한 열로 소그룹을 나눈다.
- GROUP BY절에는 별칭이 인식되지 않는다.
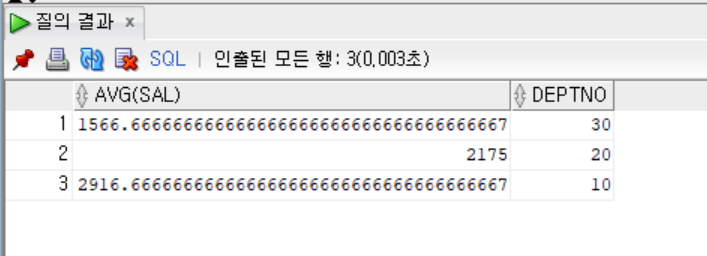
- GROUP BY절을 사용하여 부서별 평균 급여 출력하기
```sql
SELECT AVG(SAL), DEPTNO
FROM EMP
GROUP BY DEPTNO;
```
- /**각 부서**/의 /**직책별**/ /**평균 급여**/를 알고 싶다면, GROUP BY절에 JOB 열을 추가로 명시하여 오른쪽과 같이 작성할 수 있다.
```sql
SELECT AVG(SAL), DEPTNO, JOB
FROM EMP
GROUP BY DEPTNO, JOB
ORDER BY DEPTNO, JOB;
```

- GROUP BY절을 사용한 그룹화 이후, 가지런한 정렬 결과를 원한다면 ORDER BY절로 정렬 기준을 정해 주어야 한다.
- 위의 예시에서는 GROUP BY절에 명시된 부서 번호로 그룹을 먼저 묶고, 그룹 내에서 사원 직책 여를 기준으로 다시 소그룹을 묶어 급여 평균을 출력한다.
### - GROUP BY절을 사용할 때 유의할 점
- **다중행 함수를 사용하지 않은** 일반 열을 **GROUP BY절에 명시하지 않으면**, **SELECT절에서 사용할 수 없다**.
- GROUP BY절에 없는 열을 SELECT절에 포함했을 경우
--> 오류가 나게 된다.
```sql
SELECT ENAME, DEPTNO, AVG(SAL)
FROM EMP
GROUP BY DEPTNO;
```
- DEPTNO를 기준으로 그룹화 되어, DEPTNO열과 AVG(SAL) 열은 한 행으로 출력되지만, ENAME열은 여러 행으로 구성되어 각 열별 데이터 수가 달라져서 출력이 불가능하다.
- **GROUP BY절**을 사용할 때는 **SELECT절의 열**도 유심히 살펴 봐야 한다.
- <span style="background-color: rgba(242,179,188,0.5)">**GROUP BY절을 사용한 그룹화는, 그룹화 된 열 외에 일반 열을 SELECT절에 명시할 수 없다.**</span>
==> 이점만 유의하면 큰 문제가 발생하지 않을 것!
## 07-3 GROUP BY절에 조건을 줄 때 사용하는 HAVING절
- **HAVING절**은 **SELECT문에 GROUP BY절이 존재할 때만** 사용할 수 있다.
- **GROUP BY절을 통해 그룹화된 결과 값의 범위를 제한**하는데 사용된다.
- 각 부서의 직책별 평균 급여를 구하되, 그 평균 급여가 2000이상인 그룹만 출력하려면 다음과 같이 SELECT문에 GROUP BY절과 HAVING절을 작성하면 된다.
```sql
SELECT DEPTNO, JOB, AVG(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
HAVING AVG(SAL) >= 2000
ORDER BY DEPTNO, JOB;
```

- HAVING절을 통해 AVG(SAL) 값이 2000을 넘지 않는 그룹의 결과는 출력되지 않음을 알 수 있다.
### - HAVING절의 기본 사용법
- HAVING절의 기본형식
```sql
SELECT [조회할 열1 이름], [열2 이름], ..., [열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY [그룹화할 열을 지정(여러개 지정 가능)]
HAVING [출력 그룹을 제한하는 조건식]
ORDER BY [정렬하려는 열 지정]
```
- HAVING절은 GROUP BY절이 존재하는 경우, GROUP BY절 바로 다음에 작성한다.
- GROUP BY와 마찬가지로 별칭은 사용할 수 없다.
### - HAVING절을 사용할 때 유의점
- HAVING절도 WHERE절처럼 지정한 조건식이 참인 결과만 출력한다는 점에서 비슷한 부분이 있다.
- 차이점: 쓰임새가 다르다.
**WHERE -> 출력 대상 행을 제한
HAVING -> 그룹화된 대상을 출력에서 제한**
- 만약, 출력 결과를 제한하기 위해 HAVING을 사용하지 않고 조건식을 WHERE절에 명시하면 다음과 같이 SELECT문이 실행되지 않고 오류가 발생한다.
-> 출력 행을 제한하는 WHERE절에서는 그룹화된 데이터 AVG(SAL)을 제한하는 조건식을 지정할 수 없다.
==> **다중행 결과 값은 WHERE에서 제한 할 수 없다.**
```sql
SELECT DEPTNO, JOB, AVG(SAL)
FROM EMP
WHERE AVG(SAL) >= 2000
GROUP BY DEPTNO, JOB
ORDER BY DEPTNO, JOB;
```
### - WHERE절과 HAVING절의 차이점
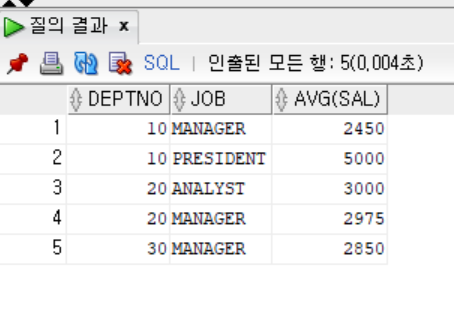
- WHERE절을 사용하지 않고 HAVING절만 사용한 경우
```sql
SELECT DEPTNO, JOB, AVG(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
HAVING AVG(SAL) >= 2000
ORDER BY DEPTNO, JOB;
```
- WHERE절과 HAVING절을 모두 사용한 경우
```sql
SELECT DEPTNO, JOB, AVG(SAL)
FROM EMP
WHERE SAL <= 3000
GROUP BY DEPTNO, JOB
HAVING AVG(SAL) >= 2000
ORDER BY DEPTNO, JOB;
```

- WHERE절을 추가한 SELECT문에서는 10번 부서의 PRESIDENT 데이터가 출력되지 않는다.
-> **WHERE절**이,
**GROUP BY절과 HAVING절을 사용한 데이터 그룹화**보다,
**먼저 출력 대상이 될 행을 제한**하기 때문이다.
- 즉, GROUP BY절을 사용해 부서별, 직책별 데이터를 그룹화하기 전에, 급여가 3000를 초과한 급여를 받는 사원의 데이터는 결과에서 먼저 제외되어 그룹화 대상에 속하지도 못하게 되는 것이다.
- 따라서, **WHERE절을 실행한 후에 나온 결과 데이터**가
**GROUP BY절과 HAVING절의 그룹화 대상 데이터**가 된다.
=> WHERE -> GROUP BY + HAVING
- 그룹이 만들어지기 전에 걸러진 데이터는 그룹화가 진행되지 않는다.
- 예; 연예인 엔터테인먼트에서 새로운 여성 아이돌 그룹을 결성하려고 할 때, 남성 연예인 지망생은 처음부터 고려 대상에서 제외된다.
> **GROUP BY로 그룹을 나누는 대상 데이터를 처음부터 제외할 목적이라면 WHERE절을 함께 사용한다.**
- GROUP BY절을 수행하기 전에 WHERE절의 조건식으로 출력행의 제한이 먼저 이루어 진다.
---
## 07-4 그룹화와 관련된 여러 함수
### - ROLLUP, CUBE, GROUPING SETS 함수
#### -- ROLLUP, CUBE 함수
- ROLLUP, CUBE, GROUPING SETS 함수는 GROUP BY절에 지정할 수 있는 특수 함수이다.
- **ROLLUP함수**, **CUBE함수**: **그룹화 데이터의 합계**를 함께 출력하는데 사용한다.
- ROLLUP 함수의 기본 형식
```sql
SELECT [조죄할 열 1 이름], [열2 이름], ..., [열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP([그룹화 열 지정(여러 개 지정 가능)]);
```
- CUBE 함수의 기본 형식
```sql
SELECT [조죄할 열 1 이름], [열2 이름], ..., [열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY CUBE([그룹화 열 지정(여러 개 지정 가능)]);
```
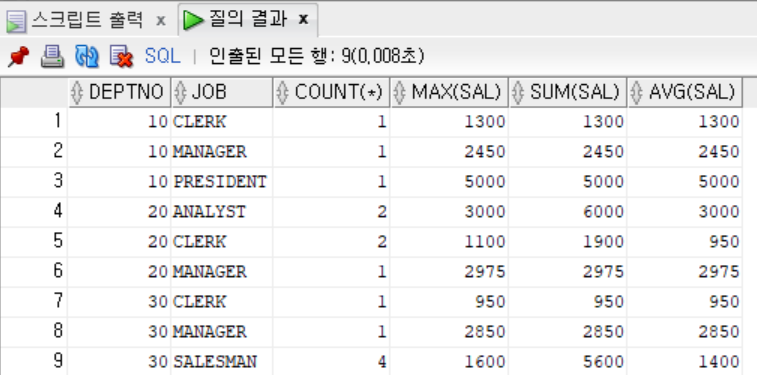
- 기존 GROUP BY절만 사용한 그룹화
```sql
SELECT DEPTNO, JOB, COUNT(*), MAX(SAL), SUM(SAL), AVG(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
ORDER BY DEPTNO, JOB;
```
- ROLLUP함수를 적용한 그룹화
```sql
SELECT DEPTNO, JOB, COUNT(*), MAX(SAL), SUM(SAL), AVG(SAL)
FROM EMP
GROUP BY ROLLUP(DEPTNO, JOB);
```
- **그룹화가 되지 않은 열의 변수**는** 꼭 ROLLUP안에** 넣어주어야 한다.(DPETNO, JOB)
(GROUP BY와 동일하게)
- 즉, ROLLUP함수에 명시한 열에 한하여 결과가 출력된다.
- **ROLLUP함수 안**에는 **그룹함수**(COUNT, MAX, MIN, ..)를 **지정할 수 없다**!

- ROLLUP함수는 명시한 열을 소그룹부터 대그룹의 순서로 각 그룹별 결과를 출력하고(여기까지는 일반 GROUP BY와 동일) 마지막에 **총 데이터의 결과**를 출력한다.
- 즉, 각 부서의 직책별 사원수, 최고 급여, 급여 합, 평균 급여를 출력하고 마지막에 테이블 전체 데이터를 대상으로 한 사원 수, 최고 급여, 급여 합, 평균 급여를 출력한다.
- CUBE 함수를 적용한 그룹화
```sql
SELECT DEPTNO, JOB, COUNT(*), MAX(SAL), SUM(SAL), AVG(SAL)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY DEPTNO, JOB;
```

- CUBE 함수는 ROLLUP함수를 사용했을 때보다 좀 더 많은 결과가 나온다.
- 주의깊게 봐야할 부분은 13행~18행인데, 이 부분은 DEPTNO, 부서와 상관 없이 직책별 결과가 함께 출력되고 있음을 알 수 있다.
- **CUBE 함수**는 **지정한 모든 열**(DEPTNO, JOB)에서 **가능한 조합의 결과**를 **모두 출력**한다.
- 결과를 눈에 띄게 출력하기 위해서 ORDER BY절을 사용해서 출력하였다.
- ROLLUP 함수
- 지정한 열 수에 따라 다음과 같이 결과 값이 조합된다.
- N개의 열 지정 -> N+1개 조합 출력
>ROLLUP(A, B, C)
>1. A그룹별 B그룹별 C그룹에 해당하는 결과 출력
>2. A그룹별 B그룹에 해당하는 결과 출력
>3. A그룹에 해당하는 결과 출력
>4. 전체 데이터 결과 출력
- CUBE함수
- 지정한 **모든 열의 조합**을 사용
>CUBE(A, B, C)
>1. A그룹별 B그룹별 C그룹에 해당하는 결과 출력
>2. A그룹별 B그룹에 해당하는 결과 출력
>3. B그룹별 C그룹에 해당하는 결과 출력
>4. A그룹별 C그룹에 해당하는 결과 출력
>5. A그룹에 해당하는 결과 출력
>6. B그룹에 해당하는 결과 출력
>7. C그룹에 해당하는 결과 출력
>8. 전체 데이터 결과 출력
- N개의 열 지정 -> 2^N개 조합 출력
- 따라서, CUBE함수는 제곱수로 조합 경우의 수가 올라가므로 감당하기 어려울 정도의 기하급수적인 증가가 일어난다.
- Partial Rollup/Cube(부분 또는 분할 ROLLUP, CUBE):
이를 방지하기 위해, 필요한 조합의 출력만 보려면 ROLLUP함수와 CUBE함수에 그룹화 열 중 일부만을 지정할 수도 있다.
- DEPTNO를 먼저 그룹화 한 후, ROLLUP함수에 JOB지정하기
```sql
SELECT DEPTNO, JOB, COUNT(*)
FROM EMP
GROUP BY DEPTNO, rollup(JOB);
```
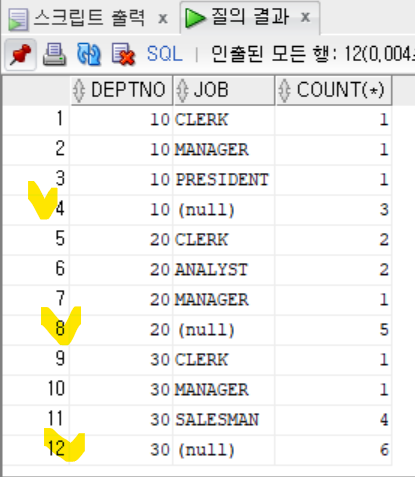
- 각각의 부서에 존재하는 각 직책별 사원 수와 각 부서별 사원 수의 합 출력
- NULL 표시 처리된 애가 ROLLUP안에 들어간 애다.
- JOB을 먼저 그룹화 한 후 ROLLUP함수에 DEPTNO지정하기
```sql
SELECT DEPTNO, JOB, COUNT(*)
FROM EMP
GROUP BY JOB, rollup(DEPTNO);
```
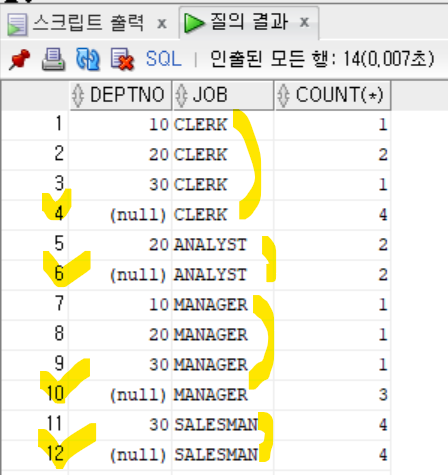
- 특정 직업을 가진 사람들의 부서별 인원수와 각 직업별 사원 수의 합 출력
- ROLLUP, CUBE가 익숙치 않다면, 다음의 단계를 따르며 차근차근 접근하자
1. 먼저 그룹화 열을 GROUP BY절로 명시한다.
2. ROLLUP, CUBE함수를 일부 열에 조금씩 적용하며 결과 값을 살펴본다.
#### -- GROUPING SETS 함수
- GROUPING SETS 함수는 같은 수준의 **그룹화 열이 여러 개**일때 각 열별 그룹화를 통해 결과 값을 출력하는데 사용한다.
- 여러 그룹화 대상 열의 결과 값을 각각 같은 수준으로 출력한다.
- 기본 형식
```sql
SELECT [조죄할 열 1 이름], [열2 이름], ..., [열N 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY GROUPING SETS([그룹화 열 지정(여러 개 지정 가능)]);
```
- **ROLLUP, CUBE**함수는 특정 부서 내 직업별 인원수와 같이 열을 대그룹, 소그룹과 같이 계층적으로 **그룹화**하여 **데이터를 집계**하였다.
- **GROUPING SETS**함수는 부서별 인원수, 직업별 인원수의 결과 값을 하나의 결과로 출력할 수 있다.
==> 지정한 **모든 열을 각각 대그룹**으로 처리하여 출력하는 것!
- 즉, GROUPING SETS 함수는 그룹화를 위해 지정한 열이 계층적으로 분류되지 않고, **각각 따로 그룹화**한 후, 연산을 수행하는 것이다.
- GROUPING SETS 함수를 사용하여 열별로 그룹으로 묶어 출력하기
```sql
SELECT DEPTNO, JOB, COUNT(*)
FROM EMP
GROUP BY GROUPING SETS(DEPTNO, JOB)
ORDER BY DEPTNO, JOB;
```

### - 그룹화 함수
- 그룹화 함수는 데이터 자체의 가공이나 특별한 연산 기능을 수행하지는 않지만 그룹화 데이터의 식별이 쉽고, 가독성을 높이기 위한 목적으로 사용한다.
#### -- GROUPING 함수
- GROUPING함수는 **ROLLUP또는 CUBE함수를 사용한 GROUP BY절**에 그룹화 대상으로 지정한 열이 **그룹화된 상태로 결과가 집계**되는지 확인하는데 사용한다.
- 즉, 현재 결과가 그룹화 대상 열의, 그룹화가 이루어진 상태의 집계인지 여부를 출력
- GROUP BY절에 명시된 열 중 하나를 지정할 수 있다.
- 기본 형식
```sql
SELECT [조회할 열 1 이름], [열2 이름], ..., [열N 이름]
GROUPING [GROUP BY절에 ROLLUP 또는 CUBE에 명시한 그룹화 할 열 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE([그룹화 열]);
```
- DEPTNO, JOB열의 그룹화 결과 여부를 GROUPING 함수로 확인하기
```sql
SELECT DEPTNO, JOB, COUNT(*), MAX(SAL), MIN(SAL), AVG(SAL),
GROUPING(DEPTNO),
GROUPING(JOB)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY DEPTNO, JOB;
```
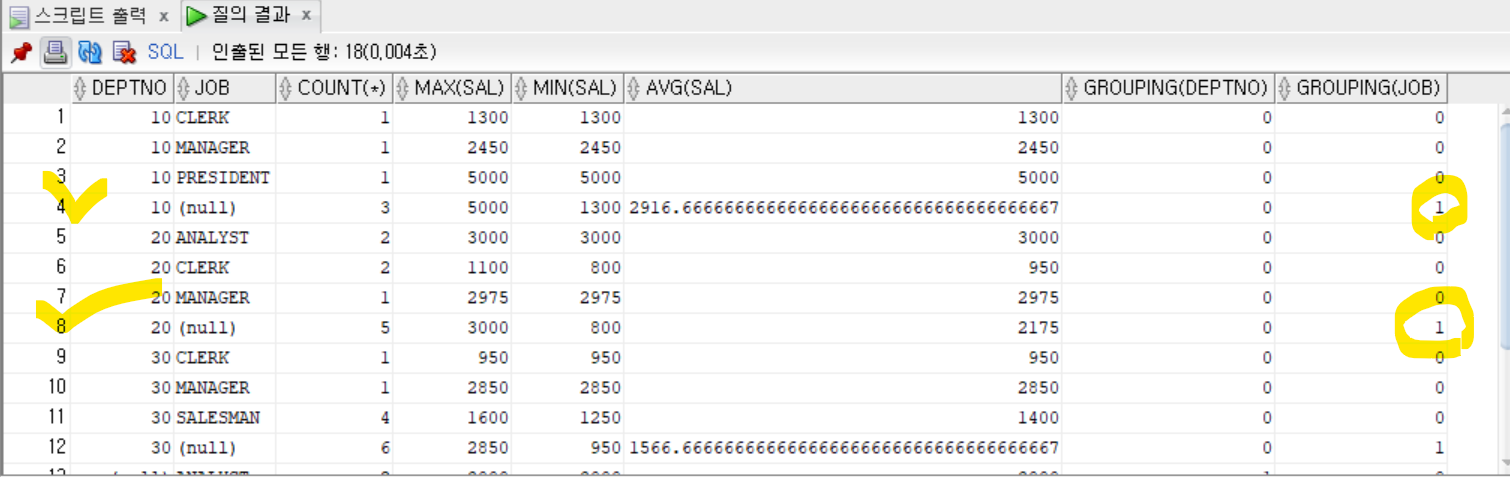
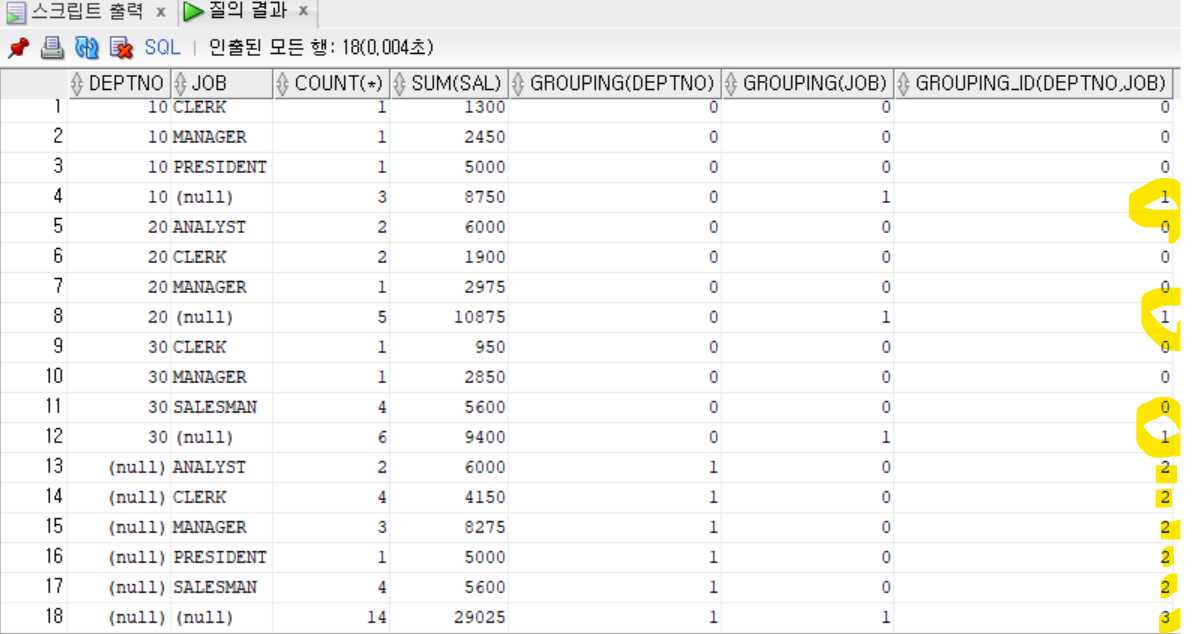
- 0: GROUPING 함수에서 지정한 열이 그룹화 되었음을 의미
- 1: GROUPING 함수에서 지정한 열이 그룹화 되지 않았음을 의미
- 맨 마지막 행의 두 데이터가 모두 1, 1인 경우는 DEPTNO, JOB 두 열 모두 그룹화하지 않은 상태, 모든 데이터의 집계 결과를 나타낸다.
- GROUPING 함수의 결과 값을 0, 1로 구별하여 출력하면, 현재 출력되는 데이터가 어떤 열의 그룹화를 통해 나온 것인지 알 수 있다.
- GROUPING 함수의 결과가 오직 0과 1로만 출력된다는 점을 이용하면 밑에와 같이 해당 열의 그룹화 없이 ROLLUP 또는 CUBE함수로 처리하여 표기할 수도 있다.
--> DECODE문으로 GROUPING함수를 적용하여 결과 표기하기
```sql
SELECT DECODE(GROUPING(DEPTNO), 1, 'ALL_DEPT', DEPTNO) AS DEPTNO,
DECODE(GROUPING(JOB), 1, 'ALL_JOB', JOB) AS JOB,
COUNT(*), MAX(SAL), SUM(SAL), AVG(SAL)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY DEPTNO, JOB;
```

#### -- GROUPING_ID 함수
- GROUPING_ID 함수는 GROUPING 함수와 마찬가지로 ROLLUP 또는 CUBE 함수로 연산할 때 특정 열이 그룹화되었는지를 출력하는 함수이다.
- 그룹화 여부를 검사할 열을 하나씩 지정하는 GROUPING함수와 달리, GROUPING_ID 함수는 **한 번에 여러 열**을 지정할 수 있다.
- 기본 형식
```sql
SELECT [조회할 열 1 이름], [열2 이름], ..., [열N 이름]
GROUPING_ID [GROUP BY절에 ROLLUP 또는 CUBE에 명시한 그룹화 할 열 이름]
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ROLLUP 또는 CUBE([그룹화 열]);
```
- GROUPING_ID 함수를 사용한 결과는 그룹화 비트 벡터(grouping bit vector)값으로 나타낸다.
- GROUPING_ID(a, b)와 같이 열을 두 개 지정한다면 출력 결과는 다음과 같다.
|그룹화 된 열|그룹화 빅트 벡터|최종 결과|
|:--------:|:------------:|:------:|
|a, b|0 0|0|
|a|0 1|1|
|b|1 0|2|
|없음|1 1|3|
- 각 열의 그룹화 유무에 따라 0과 1이 결과 값으로 나오는 것은 GROUPING과 같지만,
GROUPING_ID 함수는 한 번에 여러 열을 지정할 수 있으므로 지정한 열의 순서에 따라 0, 1값이 하나씩 출력되어,
이렇게 0과 1로 구성된 그룹화 비트 벡터 값을 2진수로 보고 10진수로 바꾼 값이 최종 결과로 출력된다.
- DEPTNO, JOB을 함께 명시한 GROUPING_ID함수 사용하기
```sql
SELECT DEPTNO, JOB, COUNT(*), SUM(SAL),
GROUPING(DEPTNO),
GROUPING(JOB),
GROUPING_ID(DEPTNO, JOB)
FROM EMP
GROUP BY CUBE(DEPTNO, JOB)
ORDER BY DEPTNO, JOB;
```
### - LISTAGG 함수
- LISTAGG 함수는 그룹에 속해 있는 데이터를 **가로로 나열**할 때 사용한다.
- 각 부서에는 속하는 사원이름은 여러개인데, GROUP BY절을 통해 DEPTNO열을 그룹화 해버리면 ENAME 데이터는 GROUP BY절에 명시하지 않는 이상 SELECT절에 명시할 수 없다.
- GROUP BY절로 그룹화 하여 부서 번호와 사원 이름 출력하기
```sql
SELECT DEPTNO, ENAME
FROM EMP
GROUP BY DEPTNO, ENAME;
```
- 하지만 ENAME을 GROUP BY 절에 명시해주어 그룹화 해주면 출력은 가능하지만, 필요없는 행이 너무 많아지게 된다.
==> 출력 정보에 비해 행이 너무 많아지기 때문에 부서별 ENAME 사원의 이름을 가로로 나타내고 싶을 때, LISTAGG 함수를 사용할 수 있다.
- LIST함수의 기본형식
- 가로로 나열할 열을 지정하고 필요하다면 각 데이터 사이에 넣을 **구분자**를 지정할 수 있다.
- 가로로 출력할 데이터를 **정렬**할 수도 있다.
- ORDER BY와 사용법이 같다.
- 왼쪽부터 오른쪽 바향으로 지정한 정렬 옵션에 따라 데이터가 가지런히 나열된다.
```sql
SELECT [조회할 열 1 이름], [열2 이름], ..., [열N 이름]
LISTAGG([나열할 열(필수)], [각 데이터를 구분하는 구분자(선택)])
WITHIN GROUP(ORDER BY 나열할 열의 정렬 기준 열(선택)])
FROM [조회할 테이블 이름]
WHERE [조회할 행을 선별하는 조건식]
GROUP BY ([그룹화할 열]);;
```
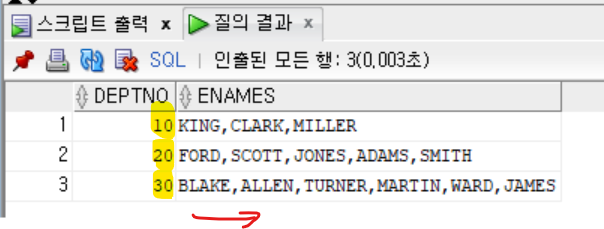
- 부서별 사원 이름을 나란히 나열하여 출력하기
- DEPTNO는 각 부서에 속해 있는 이름을 출력하기 위해 사용된다.
```sql
SELECT DEPTNO,
LISTAGG(ENAME, ',')
WITHIN GROUP(ORDER BY SAL DESC) AS ENAMES
FROM EMP
GROUP BY DEPTNO;
```
### - PIVOT, UNPIVOT 함수
- **PIVOT함수**? 기존 테이블 행을 열로 바꾼다. (행** -> 열**)
- **UNPIVOT함수**? 기존 테이블 열을 행으로 바꾼다. (**열 -> 행**)
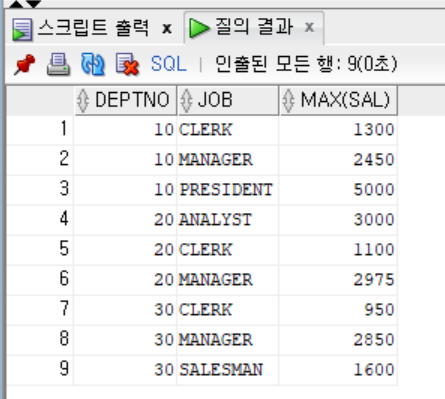
- 부서별, 직업별로 그룹화하여 최고 급여 데이터 출력하기
```sql
SELECT DEPTNO, JOB, MAX(SAL)
FROM EMP
GROUP BY DEPTNO, JOB
ORDER BY DEPTNO, JOB;
```
- 세로로만 나열되는 DEPTNO와 JOB열을 PIVOT함수를 사용하면, DEPTNO와 JOB을 각각 행과 열로, 가로와 세로로 나누어 출력할 수 있다.
- 두 DEPTNO와 JOB의 겹치는 값으로 출력할 값인 MAX(SAL)을 먼저 명시하고,
**가로줄로 표기할 열**을 **FOR로 명시**한 후에 **IN안에 **출력하려는 열 데이터를 지정한다.
- 별칭도 설정할 수 있다.
- PIVOT함수를 사용하여 직업별, 부서별 최고 급여를 2차원 표 형태로 출력하기
```sql
SELECT *
FROM(SELECT DEPTNO, JOB, SAL
FROM EMP)
PIVOT(MAX(SAL)
FOR DEPTNO IN (10, 20, 30)
)
ORDER BY JOB;
```

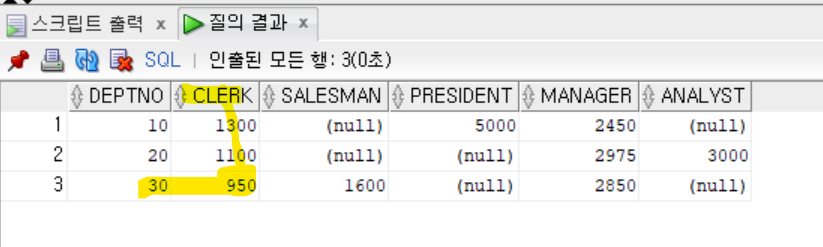
- PIVOT함수를 사용하여 부서별, 직업별 최고 급여를 2차원 표 형태로 출력하기
```sql
SELECT *
FROM(SELECT DEPTNO, JOB, SAL
FROM EMP)
PIVOT(MAX(SAL)
FOR JOB IN ('CLERK' AS CLERK,
'SALESMAN' AS SALESMAN,
'PRESIDENT' AS PRESIDENT,
'MANAGER' AS MANAGER,
'ANALYST' AS ANALYST)
)
ORDER BY DEPTNO;
```
- 서브쿼리(subquery): FROM절 안에 다시 SELECT문이 들어가 있는 형태
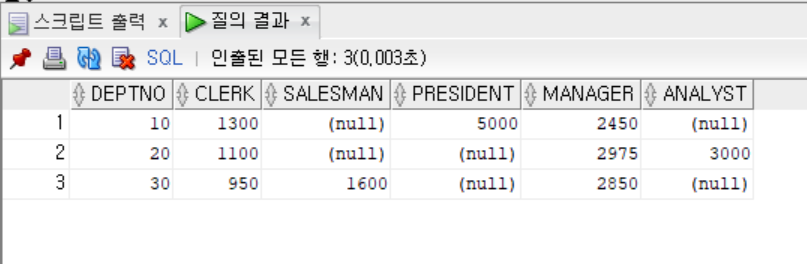
- DECODE문을 활용하여 PIVOT 함수와 같은 출력 구현하기
(오라클 버전이 11g 이전 버전일 경우에는 이 방식을 사용해야 할 수도 있다.)
```sql
SELECT DEPTNO,
MAX(DECODE(JOB, 'CLERK', SAL)) AS "CLERK",
MAX(DECODE(JOB, 'SALESMAN', SAL)) AS "SALESMAN",
MAX(DECODE(JOB, 'PRESIDENT', SAL)) AS "PRESIDENT",
MAX(DECODE(JOB, 'MANAGER', SAL)) AS "MANAGER",
MAX(DECODE(JOB, 'ANALYST', SAL)) AS "ANALYST"
FROM EMP
GROUP BY DEPTNO
ORDER BY DEPTNO;
```
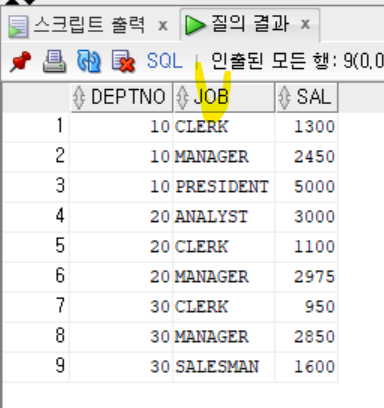
- UNPIVOT 함수는 PIVOT 함수와 반대 기능을 한다.
- UNPIVOT 함수 역시 SELECT문을 먼저 작성하고 출력 데이터(SAL)을 명시한 후, 세로로 늘어뜨릴 가로 열을 FOR문에 명시한다.
```sql
SELECT *
FROM (
SELECT DEPTNO,
MAX(DECODE(JOB, 'CLERK', SAL)) AS "CLERK",
MAX(DECODE(JOB, 'SALESMAN', SAL)) AS "SALESMAN",
MAX(DECODE(JOB, 'PRESIDENT', SAL)) AS "PRESIDENT",
MAX(DECODE(JOB, 'MANAGER', SAL)) AS "MANAGER",
MAX(DECODE(JOB, 'ANALYST', SAL)) AS "ANALYST"
FROM EMP
GROUP BY DEPTNO
ORDER BY DEPTNO
)
UNPIVOT(
SAL FOR JOB IN (CLERK, SALESMAN, PRESIDENT, MANAGER, ANALYST)
)
ORDER BY DEPTNO, JOB;
```
---
## 7장 EXERCISE
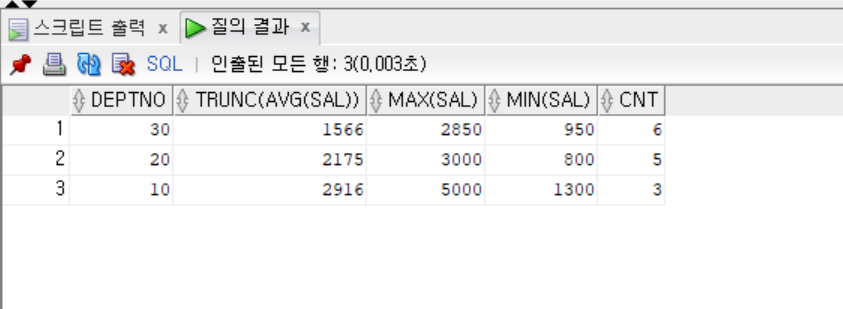
1.
```sql
SELECT DEPTNO, TRUNC(AVG(SAL)), MAX(SAL), MIN(SAL), COUNT(*) AS CNT
FROM EMP
GROUP BY DEPTNO;
```
2.
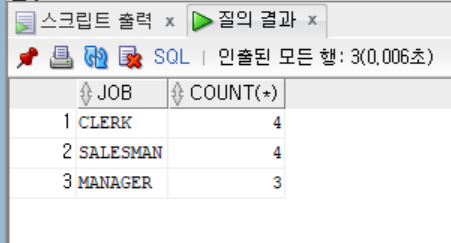
```sql
SELECT JOB, COUNT(*)
FROM EMP
GROUP BY JOB
HAVING COUNT(*) >= 3;
```
3.
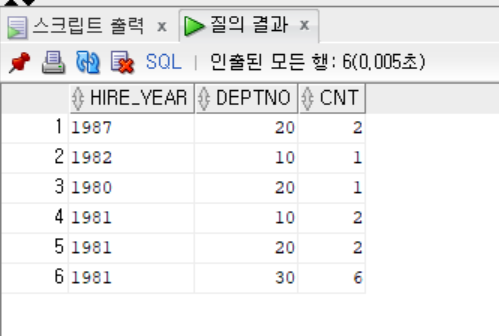
```sql
SELECT
TO_CHAR(HIREDATE, 'YYYY') AS HIRE_YEAR,
DEPTNO,
COUNT(*) AS CNT
FROM EMP
GROUP BY
TO_CHAR(HIREDATE, 'YYYY'),
DEPTNO;
```
4.
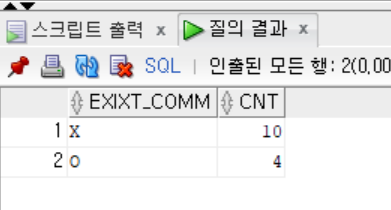
- CASE 이용 버전
```sql
SELECT
CASE
WHEN COMM IS NULL THEN 'X'
WHEN COMM IS NOT NULL THEN 'O'
END AS EXIST_COMM,
COUNT(*) AS CNT
FROM EMP
GROUP BY
CASE
WHEN COMM IS NULL THEN 'X'
WHEN COMM IS NOT NULL THEN 'O'
END;
```
- NVL2 이용버전
```sql
SELECT NVL2(COMM, 'O', 'X') AS EXIXT_COMM,
COUNT(*) AS CNT
FROM EMP
GROUP BY NVL2(COMM, 'O', 'X');
```
5.
```sql
SELECT DEPTNO,
TO_CHAR(HIREDATE, 'YYYY') AS HIRE_DATE,
COUNT(*) AS CNT,
MAX(SAL) AS MAX_SAL,
SUM(SAL) AS SUM_SAL,
AVG(SAL) AS AVG_SAL
FROM EMP
GROUP BY
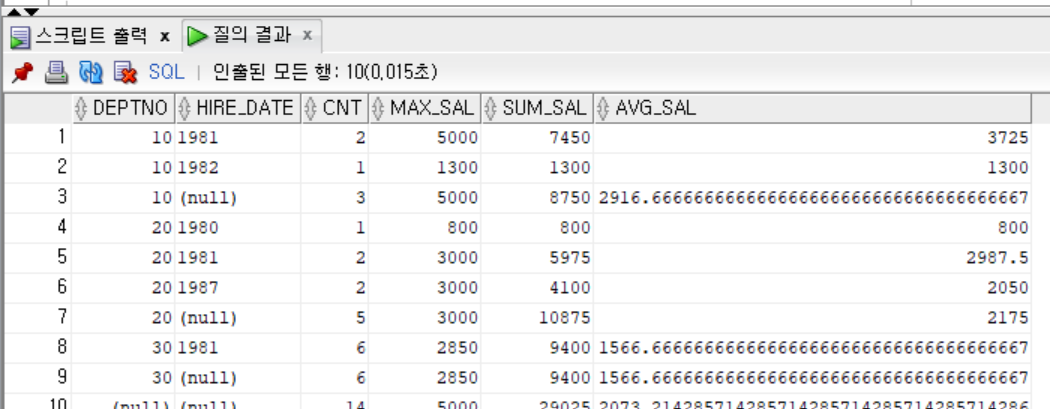
ROLLUP(DEPTNO, TO_CHAR(HIREDATE, 'YYYY'));
```